

Scaling Surgical AI Data Annotation Workflows
Explore how to efficiently scale surgical data annotation workflows in medical imaging and video analysis. This guide covers best practices, tools, and strategies to enhance AI model performance and streamline the annotation process.


How can we make Artificial Intelligence a truly trustworthy partner for surgeons? That’s a question I grapple with constantly.
It’s a huge challenge, especially when you think about the data involved. Just one hour of surgical video can create terabytes of incredibly detailed information that needs careful analysis.
I've seen projects where labeling this data – teaching the AI what it's seeing – takes up almost 80% of the total time spent building the AI model! That's a massive hurdle slowing down progress.
From my experience working in this field and seeing what works best, the solution isn't just working harder; it's working smarter by building efficient, scalable ways to handle surgical data annotation.
We need strong systems specifically designed for medical images and videos. In this guide, I want to share my insights on how we can create these systems, ensuring the AI we build is safe, reliable, and genuinely helpful in healthcare.
Why We Label Data for Surgical AI?
So, what is data annotation in this context? Simply put, it's adding labels to medical images (like X-rays or MRIs) or videos (like recordings of surgeries).
These labels point out important things – maybe outlining an organ, identifying a specific surgical tool, or marking a cancerous lesion.
These labels are how we teach the AI. The AI learns from thousands of these examples. Once trained, it can potentially assist surgeons during operations, help doctors diagnose conditions faster, or even predict how a patient might respond to treatment.
Getting these labels exactly right is critical for building AI we can trust. If we make mistakes in labeling, the AI learns the wrong patterns. Imagine labeling the edge of a tumor slightly off in an MRI scan.
The AI might then misunderstand what cancer looks like, which could lead to dangerous errors if it were used to help plan a real surgery. Accurate annotation is the absolute foundation.
Why Scaling Matters?
AI in surgery is advancing quickly. Every new application needs more and more precisely labeled data to learn effectively.
Manually labeling just one complex surgical video can take many, many hours. When you need to label thousands of videos to train a robust AI model, doing it purely manually becomes impossible.
This is where scaling our annotation workflows comes in. It means setting up processes and using tools that allow us to handle much larger amounts of data more quickly and efficiently, without sacrificing quality.
Scalable systems ensure our AI models get the huge amounts of high-quality data they need to perform reliably and safely in the demanding world of modern healthcare. Let's walk through how we build systems like that.
Challenges in Surgical Data Annotation
Labeling surgical data isn't easy. It has some unique difficulties we need to tackle.
Here is an image from Springer Journal on Surgical Endoscopy.
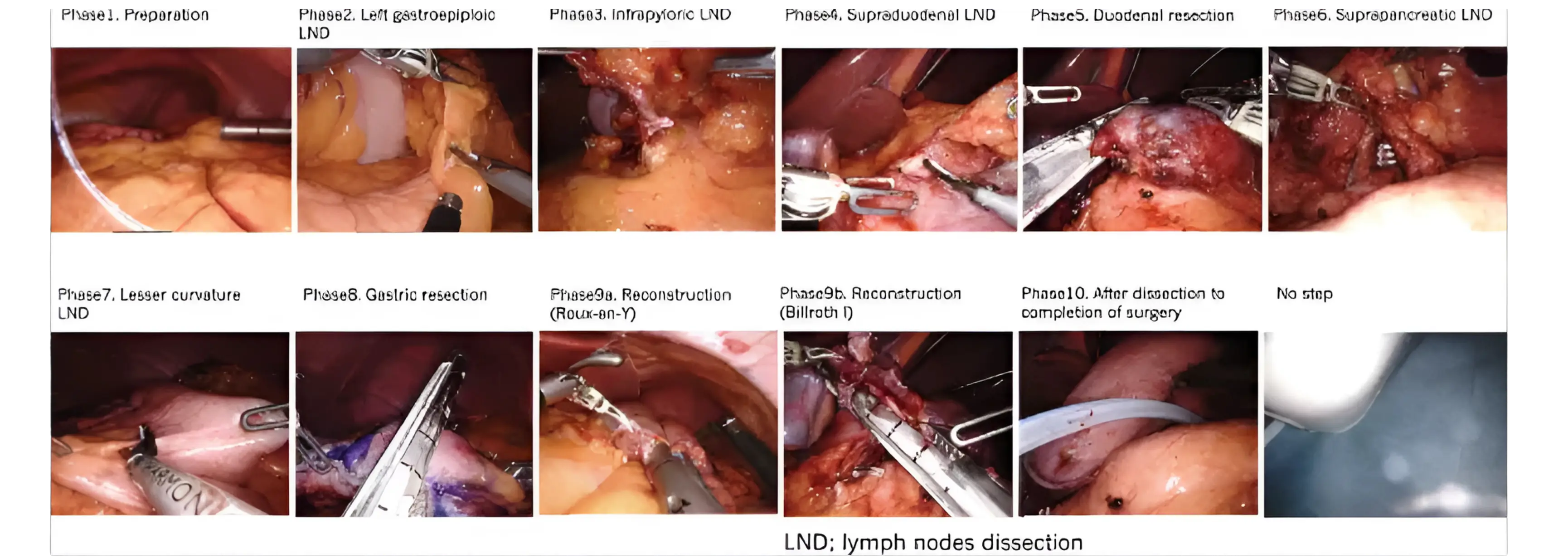
Data Complexity In Surgery
Complexity of Surgical Data
Medical images often contain very subtle details. Telling apart similar-looking tissues on a CT scan requires a trained eye.
Surgical videos? Even harder! Things move fast, tools can block the view temporarily (we call this occlusion), blood can obscure things, and the lighting isn't always perfect.
Labeling accurately under these conditions – maybe tracing a tiny blood vessel in a fast-moving, sometimes blurry video – demands incredible precision and concentration.
Every Surgery is Different (Variability)
No two operations are identical. Surgeons have different ways of doing things, use different tools, and approach problems differently.
Plus, every patient's body is unique. Our labels need to correctly capture all this variety.
For example, the "right" place to show an incision in one heart surgery video might look slightly different in another because of the surgeon's technique or the patient's anatomy.
This means we can't just create super rigid, simple rules for labeling. We need adaptable guidelines and often rely on the judgment of experienced professionals.
Domain Expertise
This isn't a task you can just hand off to anyone. Correctly labeling surgical data requires real medical knowledge.
Often, we need surgeons, radiologists, or specially trained clinical staff to do the labeling or at least carefully check it.
Think about it – only someone with years of training can reliably tell a tumor from healthy tissue on an MRI. Finding these experts and getting their valuable time is a major challenge.
It can slow down projects and increase costs, which is why planning to involve them effectively from the start is so important for building trustworthy AI.
Privacy and Security
Medical data is extremely private. Strict laws like HIPAA in the US or GDPR in Europe control how we handle it. Our annotation process must have strong safeguards built-in.
This means removing anything that identifies the patient (anonymization), storing the data securely (using encryption and controlling who can access it), and ensuring only authorized people handle it.
A mistake here could have severe legal consequences, damage reputations, and, most importantly, break patient trust. Trustworthy AI starts with protecting patient privacy.
Wrangling the Data: Management Strategies
Getting the data ready for annotation is a big job in itself.
Storing Huge Datasets
Surgical datasets are often massive. A single high-res video can be gigabytes, and projects might involve thousands of them. We need storage that can handle this scale and grow easily. The main options are:
- Cloud Storage: Services like AWS S3, Google Cloud Storage, or Azure Blob Storage are popular because they are flexible.
We can easily increase or decrease storage space as needed, it's often cheaper for large amounts of data, and it lets teams in different locations access the data securely. - On-Premise Servers: Keeping data on our own servers gives us direct physical control, which some institutions prefer for security reasons.
However, it's usually more expensive to set up and harder to scale quickly.
For most projects, especially those involving remote teams, cloud storage makes a lot of sense.
Keeping Data Organized
Good organization is key. We need a logical way to structure the data, maybe using folders named by surgery type, date, or an anonymous patient ID.
It's also crucial to keep a detailed log or database (metadata) tracking each file – like "Colonoscopy_Video_Case123_Annotated_DrSmith_QA_Pass_2025-05-02". Good annotation platforms often help manage this metadata.
A well-organized system saves a huge amount of time and stops people from labeling the wrong data or missing files.
Cleaning Up the Data (Preprocessing)
Raw medical images and videos often need some cleanup before we start labeling. Common steps I find helpful include:
- Standardizing Formats: Making sure all images are in a common format like DICOM or NIfTI, and videos are in standard types like MP4.
- Improving Quality: Sometimes adjusting brightness or contrast can make subtle but important details (like tissue edges) easier for annotators to see.
- Removing Clutter: Cropping images to just the important area or trimming unnecessary parts from videos (like setup time before the surgery starts).
Good preprocessing makes the labeling job easier, faster, and more accurate.
Making More Data (Augmentation)
Data augmentation is a trick where we create slightly modified versions of our existing data to make our dataset seem bigger.
For example, we might slightly rotate an image or adjust its brightness. In medical imaging, we have to be very careful with this.
The changes must still look realistic. Flipping a chest X-ray horizontally, for example, would put the heart on the wrong side – a bad idea!
Safe augmentations for surgical data might include minor brightness shifts, slight contrast changes, or adding a tiny bit of realistic noise.
It helps make the AI model more robust without teaching it unrealistic things. This careful approach is vital for trustworthiness.
Choosing the Right Tools
Tools Infrastruture
The software we use for labeling has a huge impact on efficiency and quality.
Popular Annotation Tools We See
There are many tools out there, some better suited for medical data than others. Some of the options I've encountered include:
- Labellerr: This is a platform I know well. It offers a comprehensive suite of tools for various annotation types (like bounding boxes, polygons, segmentation) needed for both images and videos.
It focuses on building efficient workflows, includes AI-assisted features to speed up labeling, and emphasizes data security and team collaboration – all important for medical projects. - Labelbox: A well-known commercial platform. It's generally user-friendly, good for teams working together, and handles both images and videos.
- CVAT: A free, open-source tool originally from Intel. It's popular for video annotation and quite flexible, but might need more technical setup.
- 3D Slicer: Another free, open-source tool, but this one shines for 3D medical scans (like CTs and MRIs). It's widely used in medical research.
- Encord: A commercial platform built specifically with complex medical imaging and video in mind. It often has features tailored for clinical needs and AI assistance.
The best choice depends on budget, team skills, the type of data (2D, 3D, image, video), and the specific labeling features needed.
Must-Have Features for Surgical Tools
When I evaluate tools for surgical data, I look for specific capabilities:
- Handles Medical Formats: Can it easily open and work with DICOM and NIfTI files?
- Works in 3D and Time: Can it handle 3D scans (slice by slice) and video sequences properly?
- Precise Labeling Tools: Does it have good tools for drawing exact shapes, like polygons (for outlining organs), brushes (for detailed areas), keypoints (for tracking joints), and simple bounding boxes?
- Good Video Tools: For videos, does it offer things like smooth frame-by-frame movement (scrubbing), tools to automatically track objects between frames, and interpolation (guessing labels between keyframes)?
- Teamwork Features: Can multiple people label, review, comment, and track progress easily?
- Performance: Can it handle large files without crashing or becoming slow?
Open-Source vs. Commercial Platforms
- Open-Source (like CVAT, 3D Slicer): The big plus is they're free! They can also be very customizable if you have coding skills.
However, setting them up, maintaining them, and integrating them can take more technical effort. Support usually comes from online communities. - Commercial: These usually offer a smoother experience right away, have dedicated customer support, are easier to set up, and include built-in features for managing large projects (like security controls and reporting).
They cost money, usually through subscriptions.
In my experience, technically strong teams might lean towards open-source for control, while organisations that need speed, ease of use, reliable support, and enterprise-level features often find commercial platforms provide better overall value and authoritativeness for critical medical projects.
Connecting Tools to Our Workflow
For peak efficiency, the annotation tool shouldn't be isolated. It needs to connect smoothly with our data storage and AI training systems.
I look for tools with APIs or SDKs (ways for software to talk to each other). These allow us to automate steps like:
- Automatically sending new batches of images/videos from storage to the tool for labeling.
- Assigning tasks automatically to the right annotators.
- Pulling the finished labels back automatically to feed into the AI training pipeline.
This automation saves time, reduces manual errors, and speeds up the whole process.
Quality First: Control and Validation
In medical AI, quality isn't just important – it's everything. Trustworthiness depends on it.
Why High-Quality Labels Are Non-Negotiable
A tiny mistake in a label – slightly off tumor boundary, wrong instrument name – teaches the AI incorrectly.
If that flawed AI is used clinically, it could lead to wrong diagnoses or surgical errors, harming patients. Strict quality control (QA) ensures the AI learns from accurate data, which is the only way to build safe and effective medical tools.
How We Ensure Accuracy
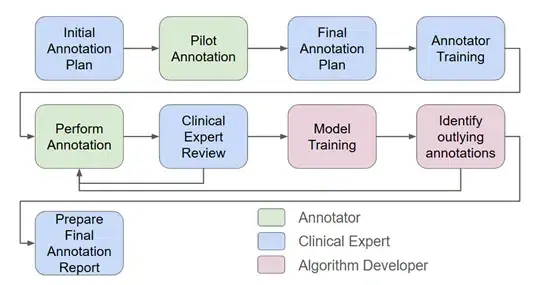
Quality Control Workflow
We need multiple checks and balances:
- Crystal Clear Guidelines: Detailed instructions with pictures showing exactly how to label everything are essential for consistency.
- Two Sets of Eyes (Double-Blind): Have two annotators label the same data without seeing each other's work. Comparing their results highlights confusing areas or where more training is needed.
- Expert Review: For tricky or critical labels (like cancer margins), we must have experienced doctors or surgeons review and approve them. Their expertise is irreplaceable.
- Agreeing on Tough Calls (Consensus): If something is genuinely hard to label, have several experts label it and then use a system (like majority vote) to decide the final label. Studies confirm that multiple reviewers significantly reduce errors.
Measuring Consistency (Inter-Annotator Agreement)
We use statistics (like Cohen's Kappa or IoU) to measure how consistently different annotators label the same things.
Low scores mean something is wrong – unclear guidelines, confusing tool, or poor training. When people disagree, we need a process for them (and experts) to discuss and agree on the right way.
This helps everyone learn and improves the guidelines.
Checking the Final Dataset (Validation)
We need to regularly check the quality of our labeled data:
- Spot Checks: Randomly select a portion of labeled data (maybe 10%) for senior annotators or experts to review carefully.
- See How the AI Does: Train the AI model on some data and test it. If the model performs badly, it might be because the labels are poor quality. We can look at the AI's specific mistakes to find labels that need fixing.
- Track Changes (Audit Trails): Good platforms log who made each label and when. This helps track down errors and ensures accountability.
Letting AI Help: Automation and Assistance
Manually labeling everything is slow. We can use AI itself to speed things up.
Pre-Labeling
We can use existing AI models to automatically create initial "draft" labels. For example, an AI might automatically outline the major organs in a CT scan.
Our human annotators then just need to check and fix these suggestions. This is usually much faster than starting from a blank slate.
Active Learning
This is a clever approach where the AI model helps us decide what to label next. The model identifies the examples it's most confused about.
We send these tricky cases to our human experts first. By focusing expert time on the most informative examples, we can often train a highly accurate AI model with less total labeling effort.
Semi-Supervised & Unsupervised
These advanced techniques try to learn from the large amounts of unlabeled data we often have, combining it with our smaller labeled sets.
Semi-supervised learning uses both labeled and unlabeled data together. Unsupervised learning can find patterns or groups in unlabeled data automatically (like clustering similar surgical video scenes), which might then be labeled more efficiently as a batch.
These can reduce the need for massive manual labeling campaigns.
Human-in-the-Loop
This creates a cycle: AI suggests labels, humans review/correct, AI learns from the corrections, and makes better suggestions next time.
It combines AI's speed with human expertise and judgment, improving efficiency while maintaining high quality through expert oversight.
Making the Workflow Efficient
Good management makes the process smoother and faster.
Assigning Tasks Wisely
We need to match the difficulty of the labeling task to the annotator's skill level. Simple tasks might go to trained general annotators, but complex medical judgments must go to clinical specialists.
Using project management tools helps track assignments, monitor progress, and ensure work is distributed fairly.
Parallel Processing
We break large projects into smaller batches. Multiple annotators or teams can then work on different batches simultaneously.
Cloud platforms make this easy for remote teams. Doing work in parallel dramatically cuts down the overall project time.
Iterative Feedback
Annotation should be a cycle of improvement. We regularly need to see how AI models perform when trained on our labeled data.
Where does the AI make mistakes? This often points to problems in our annotations or guidelines.
We use this feedback to fix the guidelines, retrain annotators, and correct bad labels. Constant improvement leads to better data over time.
Measuring Efficiency
To know if our workflow is getting better, we track key numbers:
- Speed: How long does it take to label an image or a minute of video?
- Throughput: How much data gets finished per day or week?
- Cost: What's the total cost per labeled item?
- Quality: What are our agreement scores? How many labels need fixing in QA?
Tracking these helps find bottlenecks and measure the impact of changes we make.
Cases and Best Practices
Looking at successful projects helps us improve.
What Success Looks Like
Projects like the EndoVis challenge successfully annotated thousands of complex surgical video frames by using a combination of expert input, clear rules, good tools, and AI assistance.
Case studies often show huge speed increases (like 10x faster) when moving from basic manual methods to optimized workflows.
Lessons I've Learned
From my own work and seeing others, key takeaways are:
- Involve Experts Early and Often: Don't wait until the end to show clinicians the data or guidelines. Get their input from day one.
- Train Your Annotators Well: Good training is crucial for quality and consistency.
- Be Consistent: Use standard naming, formats, and rules everywhere.
- Test Small First: Try your whole process on a small dataset before launching into a massive project.
My Recommended Best Practices
Based on what works:
- Clinical Experts are Key: Ensure they define tasks and validate critical labels for trustworthiness.
- Use AI Assistance: Leverage pre-labeling and active learning.
- Implement Strong QA: Use multiple reviewers and validation checks.
- Match Tasks to Skills: Assign work appropriately.
- Choose Scalable Tools: Pick platforms ready for large datasets and teams.
- Document Everything: Keep clear records.
Common Mistakes to Avoid
- Skimping on Experts: Don't use non-specialists for complex medical labeling just to save money. Fix: Budget for expert time.
- Vague Guidelines: Leads to inconsistent labels. Fix: Create detailed visual guides and keep improving them.
- Ignoring Privacy Rules: A huge risk. Fix: Build security and anonymization in from the start.
- Checking Quality Only Once: Too late to fix systemic issues. Fix: Implement ongoing QA throughout the process.
Future Trends
Surgical data annotation keeps evolving.
Federated Learning
This allows different hospitals to train AI models together without actually sharing sensitive patient data.
Each place trains on its own data, and only the model's learned updates are combined securely. It’s a promising way to build better AI using more diverse data while respecting privacy.
Synthetic Data Generation
AI can now generate realistic-looking synthetic medical images or videos. This "fake" data can supplement real data, especially for rare conditions where real examples are scarce. It helps make AI models more robust, though it doesn't fully replace real annotated data yet.
Smarter Automation
AI models for automatically labeling images and videos are getting better all the time. The goal is to reduce manual work further, so human experts spend more time reviewing complex cases and less time on basic labeling.
Thinking Ethically
As AI gets used more in surgery, we must consider ethics carefully. Are our datasets diverse, or will the AI only work well for certain groups of people? We need to actively seek representative data and check our models for fairness. Being transparent about how data is used is also vital for building trust.
Conclusion
Successfully scaling surgical data annotation is complex but achievable with the right strategy.
It needs careful planning, the right mix of expert and trained annotators, smart use of technology (including AI help and good platforms), and a relentless focus on quality and security.
Optimizing the workflow through automation, smart task management, and continuous learning from feedback is how we handle the sheer volume and difficulty of surgical data.
The field will continue to see more automation and new techniques like federated learning and synthetic data.
These advancements will help us overcome current challenges. Ultimately, efficient, high-quality annotation pipelines are the bedrock upon which we'll build the next generation of truly impactful AI tools for surgery.
Building trustworthy AI for surgery requires all of us working together. We need to share what works, agree on standards for quality, find responsible ways to collaborate, and always prioritize ethics like fairness and patient privacy.
By committing to rigorous data practices, we can speed up the development of AI that genuinely enhances surgical care and improves lives worldwide.
FAQs
Q1: What is surgical data annotation?
Surgical data annotation involves labeling medical images and videos to identify anatomical structures, surgical instruments, and procedural phases.
This process is crucial for training AI models in tasks like surgical workflow analysis and instrument detection.
Q2: Why is scaling annotation workflows important in medical imaging?
Scaling annotation workflows ensures that large volumes of medical data are accurately labeled, which is essential for developing reliable AI models.
Efficient workflows reduce time and resource constraints, enabling faster advancements in medical diagnostics.
Q3: What challenges are faced in surgical data annotation?
Challenges include the need for expert annotators, maintaining data privacy, ensuring consistency across annotations, and managing large datasets.
Addressing these challenges is vital for the success of AI applications in healthcare.
Q4: How can technology aid in scaling annotation workflows?
Technologies like AI-assisted annotation tools, active learning, and collaborative platforms can automate and streamline the annotation process, reducing manual effort and improving consistency.
Q5: What are best practices for managing annotation teams?
Best practices include standardized training for annotators, clear annotation guidelines, regular quality checks, and utilizing collaborative tools to coordinate efforts across teams.
References

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
