

SAM Fine-Tuning Using LoRA
Learn how to fine‑tune SAM with LoRA to achieve precise, domain‑specific segmentation without massive GPU costs. Freeze the SAM backbone, train only tiny low‑rank adapters, and deploy high‑accuracy models on modest hardware—fast, modular, and efficient.


In AI model adaptation, AI engineers faced a seemingly impossible problem on how to fine-tune AI models for specific business needs without bankrupting their organizations.
Traditional fine-tuning approaches have a major flaw of large computation costs, technical limitations and resource constraints that made model fine-tuning accessible only to tech giants with virtually unlimited budgets.
Before the advent of LoRA (Low-Rank Adaptation), AI engineers were trapped in a resource-intensive problem.
For example, Full fine-tuning required updating all parameters of a pre-trained model, which for a 7B parameter model meant 84GB of GPU memory and costs ranging from $10,000 to $50,000 per fine-tuning run.
This meant that adapting a modest 7B model to specific business requirements could easily consume the entire GPU budget of a startup or small AI team.
In this blog, you will learn about fine-tuning and its different methods and also learn to implement LoRA fine-tuning on SAM.
What is Fine-Tuning and why is it needed?
Fine-tuning is the process of taking a pre-trained machine learning model and further training it on a smaller, targeted dataset to adapt it for specific tasks or use cases.
This approach leverages the knowledge and features already learned by the model during its initial training on large, diverse datasets, making it more efficient than training a model from scratch.
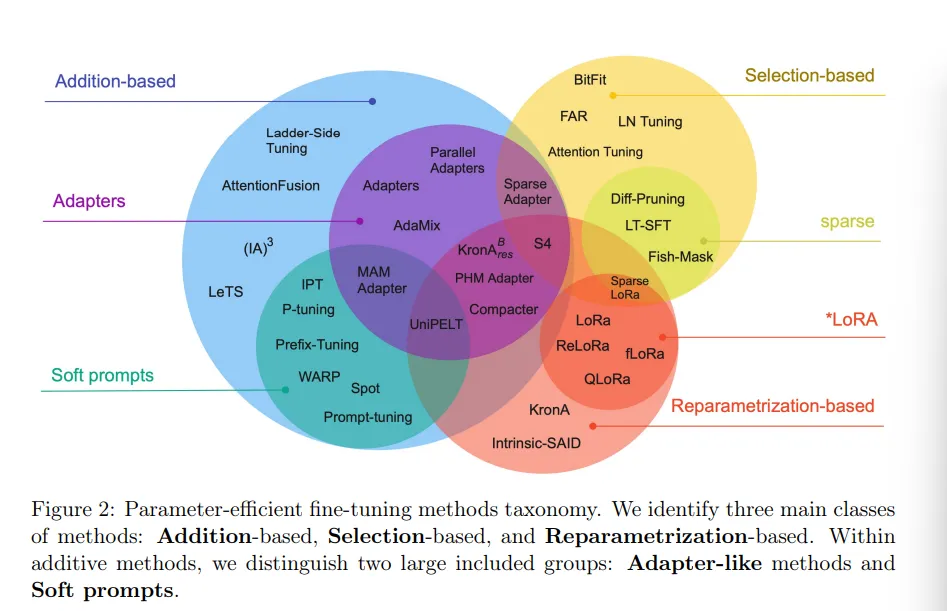
All-Fine-tuning-method
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
Why is it needed?
Pre-trained models, while powerful, are designed to be general-purpose and may not perform optimally for specialized tasks or domain-specific applications
Without fine-tuning, even the most powerful models may underperform on niche or specialized domains.
Fine-tuning addresses several key challenges:
- Domain Adaptation: Large language models like GPT-3 or BERT are trained on broad, general datasets but may struggle with niche use cases such as medical terminology, legal documents, or specific industries' knowledge.
- Task Specialization: A general-purpose model might recognize objects broadly but requires fine-tuning to excel at specific tasks, such as identifying particular species of birds or analyzing financial documents.
- Performance Optimization: Fine-tuning can significantly improve model performance on target tasks compared to using pre-trained models out of the box.
For example, a business adding generative AI into customer support might fine-tune a large language model on its product information and past customer interactions to produce more relevant responses - Resource Efficiency: Rather than training massive models from scratch, which requires enormous computational resources and time, fine-tuning allows organizations to leverage existing pre-trained models and adapt them efficiently.
Different methods of Fine-tuning.
There are two ways to fine-tune a model: either by traditional full fine-tuning, which is resource-intensive, or by performing parameter-efficient techniques, also known as PEFT methods.
Full Fine-Tuning
Full fine-tuning involves updating all parameters of a pre-trained model during the training process. While this approach can yield excellent results, it comes with significant drawbacks:
- Computational Intensity: Requires updating all model parameters, demanding substantial GPU memory and processing power.
- Storage Costs: Each fine-tuned model requires storing the entire model weights, leading to massive storage requirements.
- Training Time: The process is slow and expensive.
Parameter-Efficient Fine-Tuning (PEFT) Methods
To address the limitations of full fine-tuning, researchers have developed several parameter-efficient techniques that achieve comparable performance while dramatically reducing computational requirements.
- Adapter Tuning
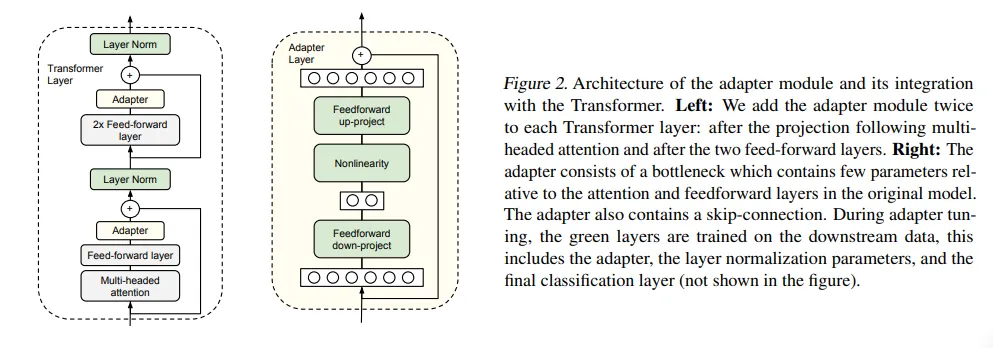
Adapter-tuning
Parameter-Efficient Transfer Learning for NLP
Adapter tuning involves inserting small, trainable modules called adapters between the layers of a pre-trained model while keeping the original model parameters frozen.
The adapter method:
- Adds new neural network layers with bottleneck architectures.
- Requires training only 0.5-8% of the original model parameters.
- Can achieve performance within 0.4% of full fine-tuning while training two orders of magnitude fewer parameters.
- Introduces some inference latency due to additional computational layers.
2. Prefix Tuning
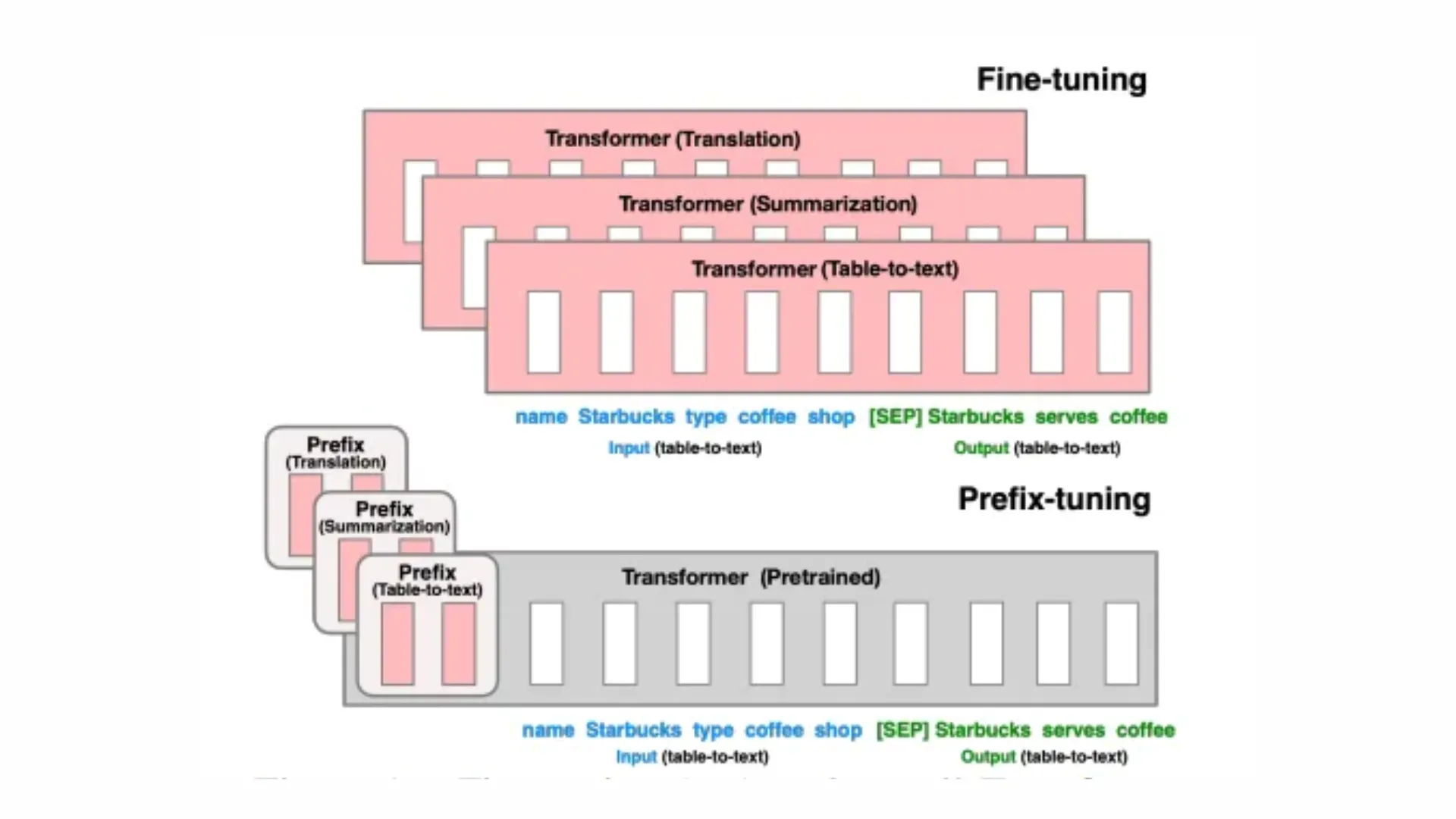
Prefix-Tuning
Prefix tuning optimizes task-specific continuous vectors (prefixes) that are prepended to the input sequence, while keeping the pre-trained model parameters frozen.
This method:
- Learns "soft prompts" through backpropagation rather than discrete text prompts.
- Becomes more competitive with scale, matching full fine-tuning performance as models exceed billions of parameters.
- Provides efficient task adaptation with minimal parameter overhead.
- Offers better domain transfer robustness compared to full model tuning.
- LoRA Fine-Tuning
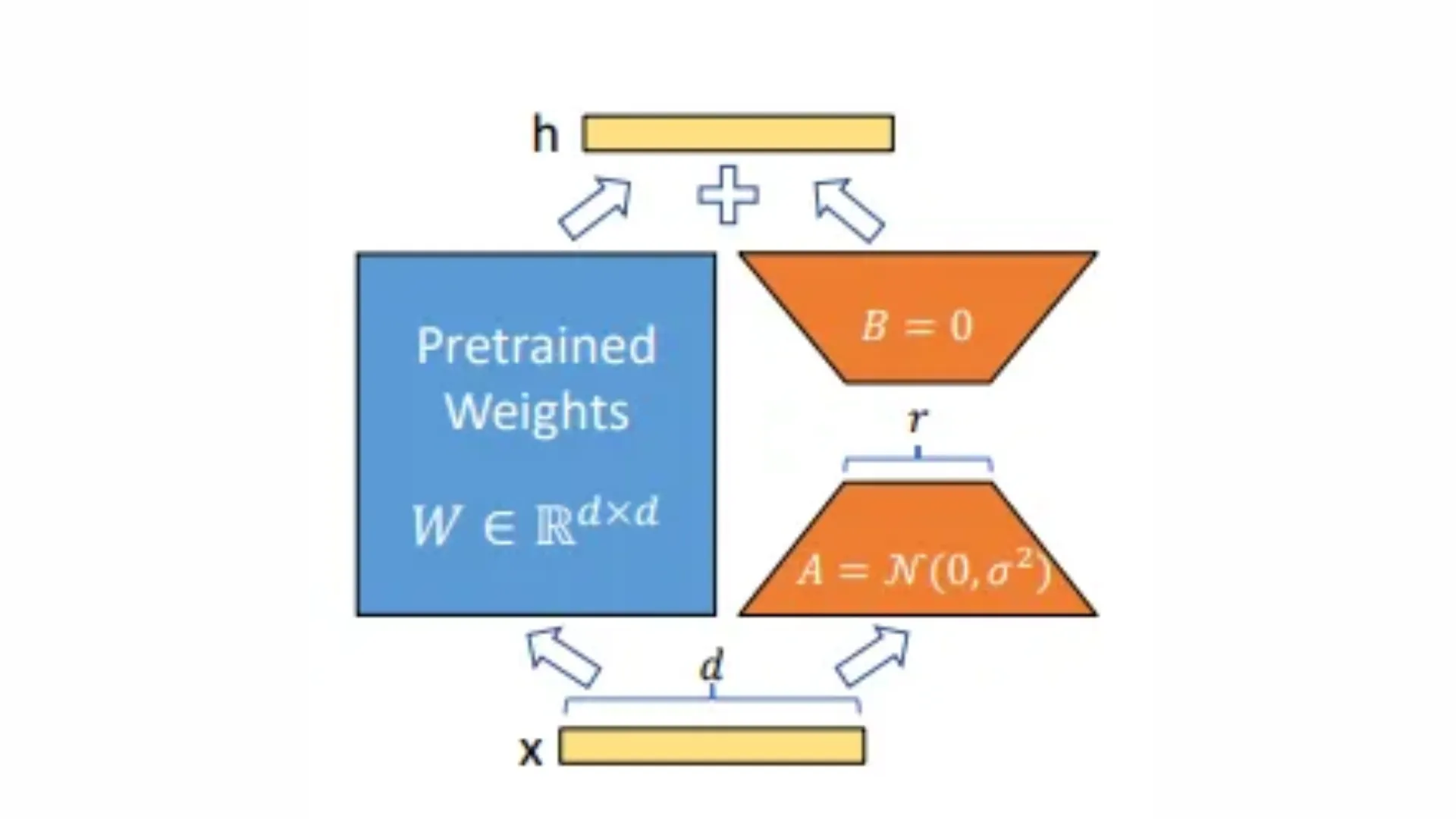
LoRA Fine-tuning
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
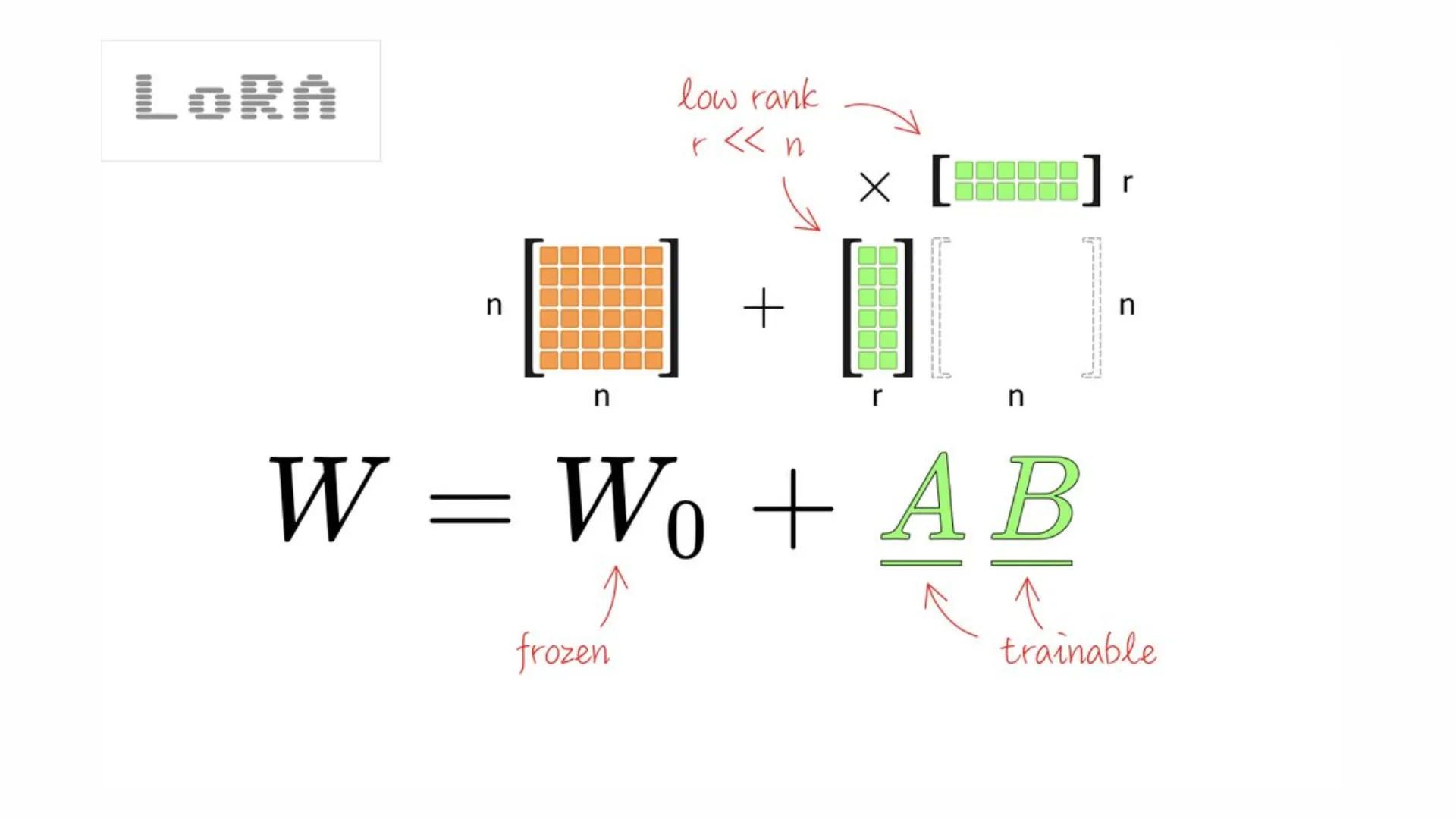
LoRA (Low-Rank Adaptation) is a popular PEFT method that makes fine-tuning large models practical and efficient.
This method:
- Freeze the original model: The main model’s weights are not changed.
- Add small “side” matrices: LoRA introduces two small trainable matrices into certain layers of the model.
- Train only the new parts: During fine-tuning, only these small matrices are updated.
- Combine at the end: The effect of the small matrices is merged with the original model during inference, so the model behaves as if it were fully fine-tuned.
How does LoRA fine-tuning work?
LoRA (Low-Rank Adaptation) fine-tuning works by making the process of adapting large models much more efficient, both in terms of speed and resource usage.
How LoRA works
Here’s a step-by-step explanation of the process:
- Freeze the Original Model
- The main model’s parameters (weights) are kept unchanged during training. This means the pre-trained knowledge is preserved, and you don’t need to use a lot of memory or computation to update everything.
- Add Small “Side” Matrices
- Instead of changing the huge weight matrices inside the model, LoRA adds two much smaller, trainable matrices (let’s call them A and B) to certain layers, usually the attention layers in transformers.
- These matrices are called “low-rank” because they are much smaller than the original weight matrices.
The size of these matrices is controlled by a parameter called rank (r), which you can adjust depending on how much flexibility you want.
- Train Only the New Parts
- During fine-tuning, only these small A and B matrices are updated based on your new data. The original, large model weights stay frozen.
- The idea is that these small matrices can capture the necessary changes for your specific task, without needing to change the whole model.
- How the Math Works
- In a regular model, you’d update a big matrix (let’s call it W) directly.
- With LoRA, you instead learn how to represent the needed changes (ΔW) as the product of A and B: ΔW=B×AΔW=B×A.
- Since A and B are much smaller, you only need to learn a tiny fraction of what you’d otherwise have to.
- Combine at the End
- When you want to use the fine-tuned model (for inference), you merge the effects of the small matrices back into the original model.
- This can be done by simply adding the product of A and B to the original weights, or by keeping them as adapters that are applied during inference.
- There’s no extra delay or slowdown, and you still get the benefits of the fine-tuning.
Why LoRA is Efficient?
- Very few new parameters: Instead of updating billions of parameters, LoRA may only need to train a few million.
- Saves memory: Requires much less GPU memory, so you can fine-tune large models on consumer hardware.
- No extra delay: At inference time, LoRA doesn’t slow down the model.
- Easy to swap: You can have different LoRA adapters for different tasks and switch between them quickly.
How to perform SAM Fine-Tuning using LoRA?
To perform SAM fine-tuning using LoRA, we have created a GitHub repo through which you can fine-tune SAM with very few steps.
Step 1: Clone the git repo
!git clone https://github.com/TheLunarLogic/SAMFinetuning.git
Step 2: Load the dataset. Here I am using the COCO dataset for fine-tuning (you can create your own).
# provide the coco dataset path for both train and val
train_csv = '/your/training/csv/path'
val_csv = '/your/validation/csv/path'
Step 3: Perform fine-tuning
from SAMFinetuning.train import fine_tuning
fine_tuning(train_csv, val_csv,
checkpoint='facebook/sam-vit-base',
save_dir= "./checkpoints"
batch_size= 2
num_epochs= 5
learning_rate= 1e-4
weight_decay= 1e-4
patience= 10
image_size= 1024
num_workers= 4
)
A fine-tuned SAM model will be saved in the checkpoint directory.
Conclusion
By freezing the bulk of a model’s pre‑trained parameters and training only two compact low‑rank matrices, LoRA delivers near‑full‑tuning performance with a fraction of the memory, compute, and storage overhead.
Its plug‑and‑play adapters let you spin up new task‑specialized variants in minutes, swap workloads across domains, and preserve core knowledge without risk of catastrophic forgetting.
Combined with tools like our SAM fine-tuning repository, LoRA empowers organizations of any size to tailor SAM models to these specific business needs, rapidly, affordably, and at scale.
FAQs
Q1. What is LoRA fine-tuning and how does it differ from full fine-tuning?
A. LoRA (Low‑Rank Adaptation) freezes the vast majority of a pre‑trained model’s weights and injects two small, trainable matrices into each layer. Unlike full fine‑tuning—which updates every parameter and demands massive compute—LoRA trains only a tiny fraction of parameters, slashing memory and cost.
Q2. Why use LoRA to fine-tune the Segment Anything Model (SAM)?
A. SAM is a large vision model that benefits from task-specific adaptation. LoRA lets you tailor SAM to new datasets (e.g., COCO) using consumer‑grade GPUs by training only low‑rank adapters. You get near‑full performance gains without the expense or infrastructure of updating all 100+ million weights.
Q3. Can I switch between multiple tasks once I’ve fine‑tuned with LoRA?
A. Yes. Each LoRA adapter is a self‑contained module. You can load different adapters for different tasks—object segmentation, instance mask refinement, specialized domains—without altering the base SAM weights or retraining from scratch.
References

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
