

Run Qwen2.5-VL 7B Locally: Vision AI Made Easy
Discover how to deploy Qwen2.5-VL 7B, Alibaba Cloud's advanced vision-language model, locally using Ollama. This guide covers installation steps, hardware requirements, and practical applications like OCR, chart analysis, and UI understanding for efficient multimodal AI tasks.

Artificial Intelligence (AI) now extends beyond text to understand images and video. Alibaba's Qwen2.5-VL series, particularly the 7 billion (7B) parameter instruction-tuned model, is a powerful open-source Vision-Language Model (VLM).
This guide provides a practical, technical overview of using Qwen2.5-VL 7B via Ollama, a tool simplifying local AI model deployment. We will cover setup, code, key features, and use cases.
Quick Start
- Install Ollama: Download from [ollama.com](https://ollama.com).
- Pull the Model: Run `ollama pull qwen2.5vl:7b` in your terminal.
- Run Inference: Copy our [Python script](#running-qwen25-vl-7b-locally) to analyze images instantly.
Key Technical Features
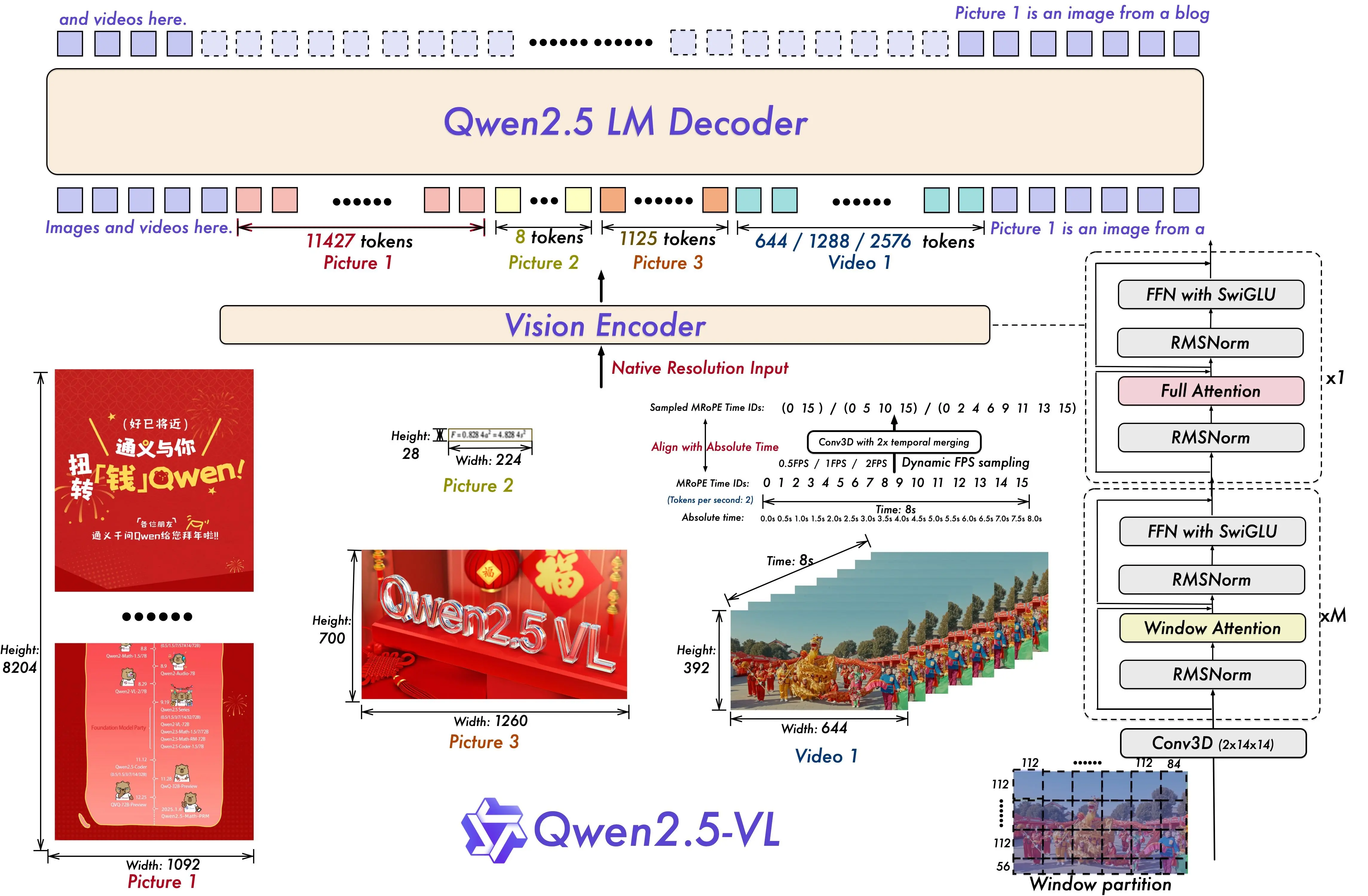
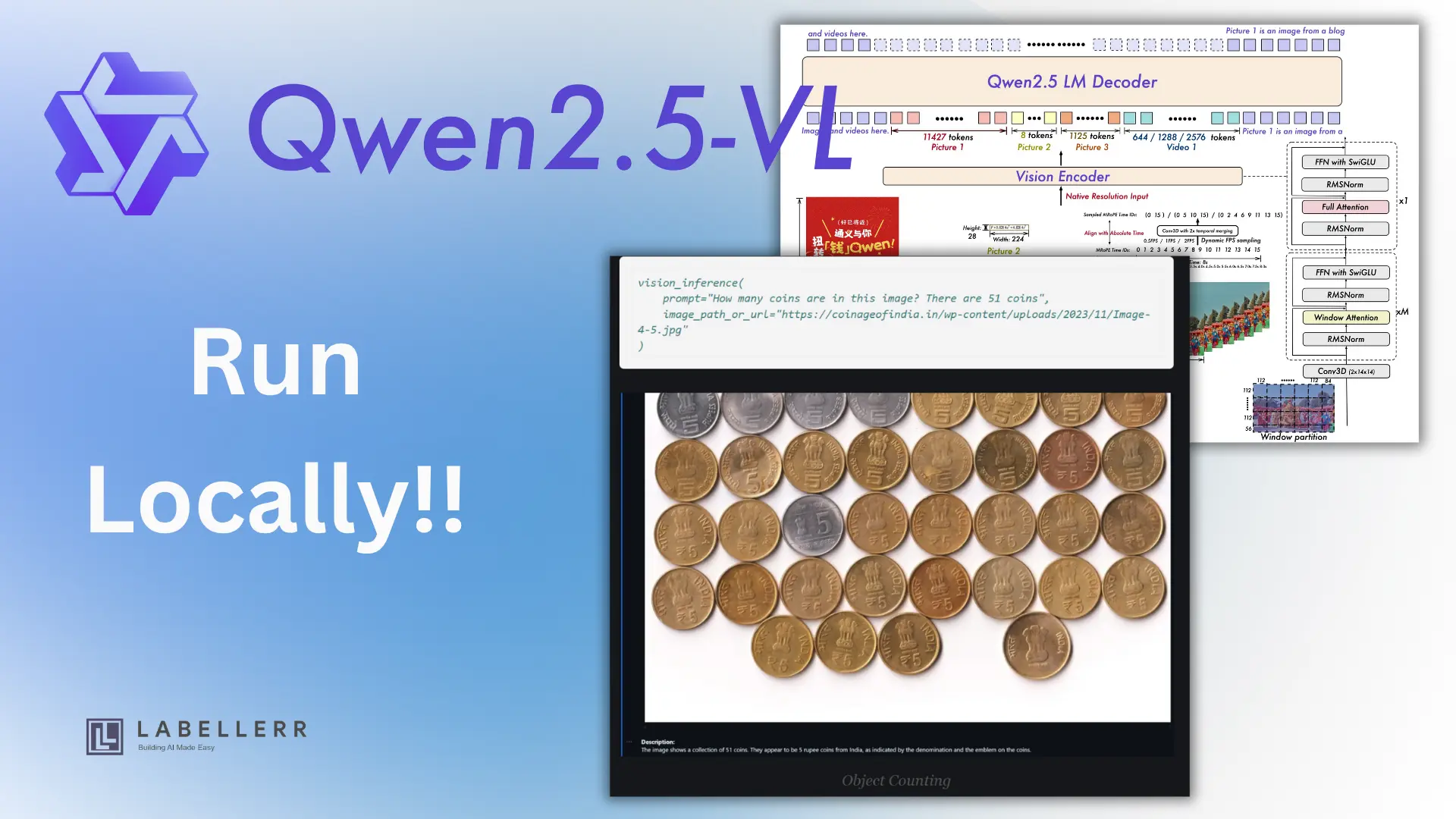
QWEN-2.5VL Architecture
Qwen2.5-VL 7B processes images and text to generate text responses.
- Parameters: 7 billion, offering a balance of capability and resource needs for local execution .
- Architecture Highlights :
- "Naive Dynamic Resolution": Handles images of various resolutions and aspect ratios by mapping them to a dynamic number of visual tokens, improving efficiency .
- Multimodal Rotary Position Embedding (M-RoPE): Enhances understanding of positional information across text and images .
- Streamlined Vision Encoder: Optimized for better integration with the Qwen2.5 language model architecture .
- Training: Built on the Qwen2.5 LLM, instruction-tuned for visual inputs.
- Core Capabilities :
- Multilingual OCR: Extracts text from English, Japanese, Arabic, etc.
- Chart/Table Parsing: Converts visual data into structured formats (JSON/CSV).
- Object Localization: Identifies and describes positions of objects in images.
- Document Understanding: Analyzes invoices, forms, and UI screenshots.
Setup: Qwen2.5-VL 7B with Ollama
To run Qwen2.5-VL 7B locally:
Prerequisites:
- Python installed.
- Ollama installed (from
ollama.com). - Sufficient system resources (a 7B VLM typically needs decent RAM and VRAM, often 8GB+ VRAM).
Download Model via Ollama:
Open your terminal and execute (verify the exact tag from Ollama's library, e.g., qwen2.5vl:7b or qwen2.5vl-instruct:7b):
# Download the qwen2.5vl 7b model using Ollama
ollama pull qwen2.5vl:7b
Verify with ollama list.
Setup Summary
| Step | Action | Command/Code |
|---|---|---|
| 1 | Install Ollama | curl -fsSL https://ollama.com/install.sh | sh |
| 2 | Download Qwen2.5-VL 7B | ollama pull qwen2.5vl:7b |
| 3 | Install Python Libraries | pip install ollama requests Pillow |
Install Python Libraries:
# Install the required python libraries using pip
pip install ollama requests Pillow
Running Qwen2.5-VL 7B Locally
This script demonstrates loading images and performing inference.
Image Loading Function:
import requests import ollama def load_image(image_path_or_url): """Load image bytes from a local path or URL.""" if image_path_or_url.startswith('http://') or image_path_or_url.startswith('https://'): print(f"Downloading image from: {image_path_or_url}") response = requests.get(image_path_or_url) response.raise_for_status() # Ensure download was successful return response.content else: print(f"Loading image from local path: {image_path_or_url}") with open(image_path_or_url, 'rb') as f: return f.read()
This function fetches image data as bytes.
Qwen2.5-VL Inference Function:
def vision_inference(prompt, image_path_or_url, model='qwen2.5vl:7b'): try: image_bytes = load_image(image_path_or_url) print(f"\nSending prompt to qwen2.5vl-7b ({model}): '{prompt}'") response = ollama.chat( model=model, messages=[ { 'role': 'user', 'content': prompt, 'images': [image_bytes], # Image bytes are passed here } ] ) if 'message' in response and 'content' in response['message']: print(f"\n Qwen Says:\n{response['message']['content']}") else: print(f"Unexpected response format from Ollama: {response}") except Exception as e: print(f"An error occurred: {e}")
The qwen2_5vl_image_inference function sends the prompt and image bytes to the Qwen model via ollama.chat().
Example Usage:
Save the above functions into a Python file (e.g., run_qwen_vision.py).
if name == "main": print("--- Example: Analyzing a URL Image with Qwen2.5-VL ---") # Example image of a car license plate url_image_path = "https://acko-cms.ackoassets.com/fancy_number_plate_bfbc501f34.jpg" qwen2_5vl_image_inference( prompt="What is the primary focus of this image? Describe any text visible and its significance.", image_path_or_url=url_image_path ) # To test with a local image: print("\n--- Example: Describing a Local Image with Qwen2.5-VL ---") local_image_path = "your_local_image.jpg" # Replace with your image path try: from PIL import Image as PImage # For creating a dummy test image try: PImage.open(local_image_path) except FileNotFoundError: img = PImage.new('RGB', (600, 400), color = 'green'); img.save(local_image_path) print(f"Created dummy '{local_image_path}'. Replace with your own image.") qwen2_5vl_image_inference( prompt="Describe the main objects in this image and their spatial relationships.", image_path_or_url=local_image_path ) except Exception as e: print(f"Error with local image example: {e}")
Run this script. It will analyze an image of a license plate from a URL. You can uncomment and adapt the local image section.
Practical Uses for Qwen2.5-VL 7B (Local)
With your local Qwen2.5-VL 7B:
Document Analysis:
Extract data from invoices, forms, and charts.
Qwen VQA
Multilingual Text-in-Image Recognition:
Read text in various languages from signs or labels.
# vision_inference("What language is the text, and what does it say?", "https://faculty.weber.edu/tmathews/grammar/Rulfo.JPG")

multilingual understading
Detailed Visual Q&A:
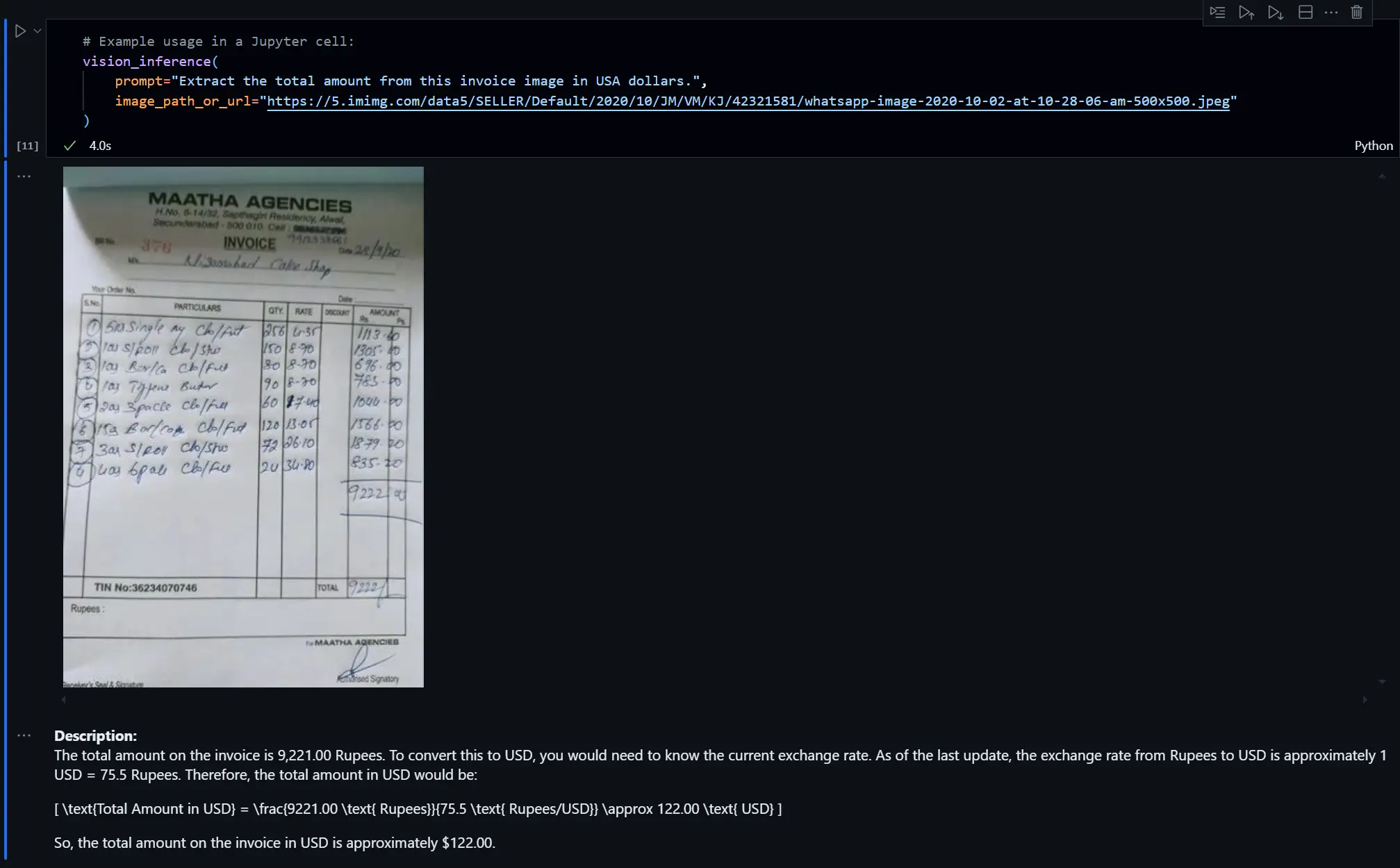
Answer specific questions about image content for e-commerce or education, leveraging its strong benchmark performance .python# qwen2_5vl_image_inference("How many red chairs are in this classroom photo?", "classroom.jpeg")
vision_inference(
prompt="How many coins are in this image? There are 51 coins",
image_path_or_url="https://coinageofindia.in/wp-content/uploads/2023/11/Image-4-5.jpg"
)

Object Counting
Strengths & Limitations: Qwen2.5-VL 7B via Ollama
Strengths:
- Strong Benchmark Performance: Competitive with other open and some closed VLMs (DocVQA, MathVista) .
- Dynamic Resolution & M-RoPE: Innovative architectural features for handling diverse images effectively.
- Multilingual Text-in-Image Capability: A key advantage.
- Open Source & Local: Accessible via Ollama for privacy and experimentation.
Limitations:
- Resource Needs: A 7B VLM still requires adequate local hardware (RAM/VRAM)(~12gb).
- Full Capability Nuances: Advanced features like precise bounding box generation or complex video analysis might be more robust in larger Qwen2.5-VL family models or require more intricate prompting/parsing.
- Safety Guardrails: May exhibit over-cautiousness common to LLMs.
Conclusion
Alibaba's Qwen2.5-VL 7B, when run via Ollama, brings a powerful and versatile open-source vision-language model to your local machine.
Its strengths in document analysis, multilingual capabilities, and general image understanding make it a valuable tool for developers and AI enthusiasts exploring multimodal applications.
References
{kind=link}
FAQs
Q1: What is Qwen2.5-VL 7B?
A: Qwen2.5-VL 7B is a 7-billion-parameter vision-language model developed by Alibaba Cloud. It excels in tasks like object recognition, OCR, chart interpretation, and UI understanding, making it suitable for various multimodal AI applications.
Q2: What are the hardware requirements for running Qwen2.5-VL 7B locally?
A: Recommended specifications include:
- GPU: NVIDIA GPU with at least 16GB VRAM
- RAM: Minimum 32GB; 64GB or more for vision-intensive tasks
- Storage: At least 50GB free space; SSD preferred for faster performance.
These requirements ensure smooth operation, especially when processing high-resolution images or videos.
Q3: What are some practical applications of Qwen2.5-VL 7B?
A: The model is adept at:
- Extracting text from scanned documents (OCR)
- Interpreting charts and tables
- Understanding and navigating user interfaces
- Analyzing complex layouts and graphics
These capabilities make it valuable for industries like finance, healthcare, and e-commerce.
Q4: Where can I find more resources or support for using Qwen2.5-VL 7B?
A: For detailed documentation and community support, visit the Qwen2.5-VL GitHub repository and the Ollama official
Q5: Can Qwen2.5-VL extract data from scanned PDFs?**
Yes! Use the script to process PDFs converted to images (e.g., via `pdf2image`). Example: python
vision_inference("Extract all invoice totals from this PDF page.", "invoice_page.jpg")
Q6: How accurate is multilingual text extraction?
For Latin/Asian scripts (English, Japanese, etc.), accuracy is ~85-90%. For cursive scripts (Arabic), use high-resolution images.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
