

Labellerr Product Update Aug 2023: Guide To New Features

Efficiently managing and maintaining high-quality training data is a cornerstone of machine learning success. To achieve this, the systematic measurement of labeling quality becomes paramount.
Labeling quality encompasses the precision, uniformity, and dependability of annotations, whether generated by human labelers or automated labeling models.
Keeping that in mind we have launched 3 new features to help ML teams to get accurate labels with lesser effort and in short time. These features are thoughtfully divided into three distinct components: Throughput, Efficiency, and Quality. Each component serves as a critical gauge in comprehending the entirety of your labeling operations.
Throughput functions as a performance indicator, quantifying the speed and progress of your labeling endeavors. Efficiency, akin to a fine-tuned instrument, steers your team toward the most resource-efficient labeling pathways. Lastly, Quality stands as the gold standard, encapsulating the unwavering accuracy, consistency, and reliability of your annotated data.
Guarantee annotation quality improved through features which allowed collaboration, and communication
Labellerr has introduced three new feature updates in its product - Search by remarks , real-time smart feedback and export of visualization.
The primary aim of these features has been to reduce the time taken by all parties in annotation, improving consensus among all parties and improving the quality of annotations.
What is new?
Low level of remark utilization led to greater number of iterations in annotating files ( 3-5 iterations ) to reach 95 % acceptance level by client. Also, it led to maintenance of log sheet, more doubt clearing sessions decreasing productivity for clients.
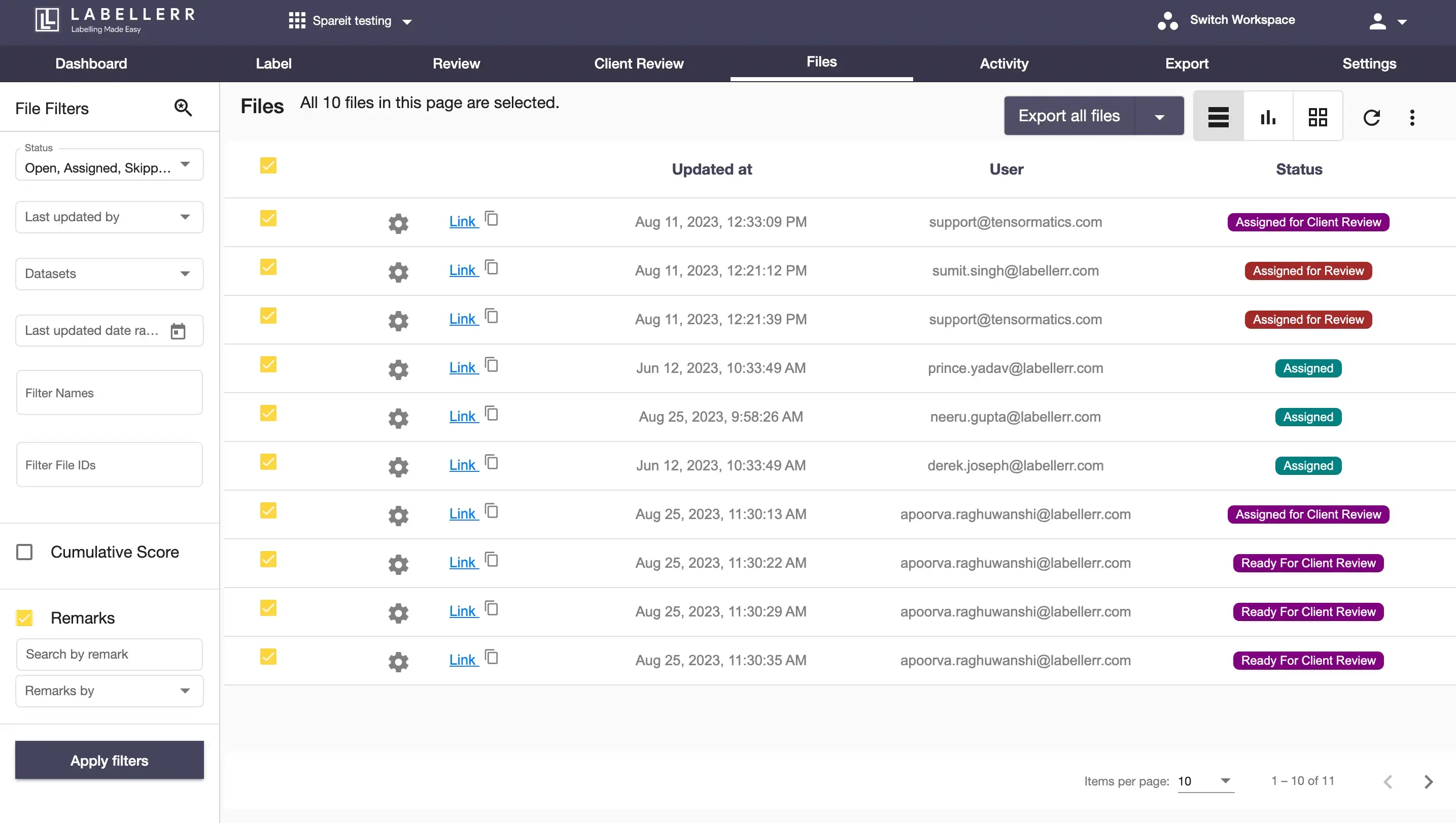
After implementing search data by remarks feature : The acceptance level increased to 95 % in 3x faster thus increasing efficiency.No multiple sessions were required to achieve this required quality level.
Subjectivity in Annotation Guideline is a problem
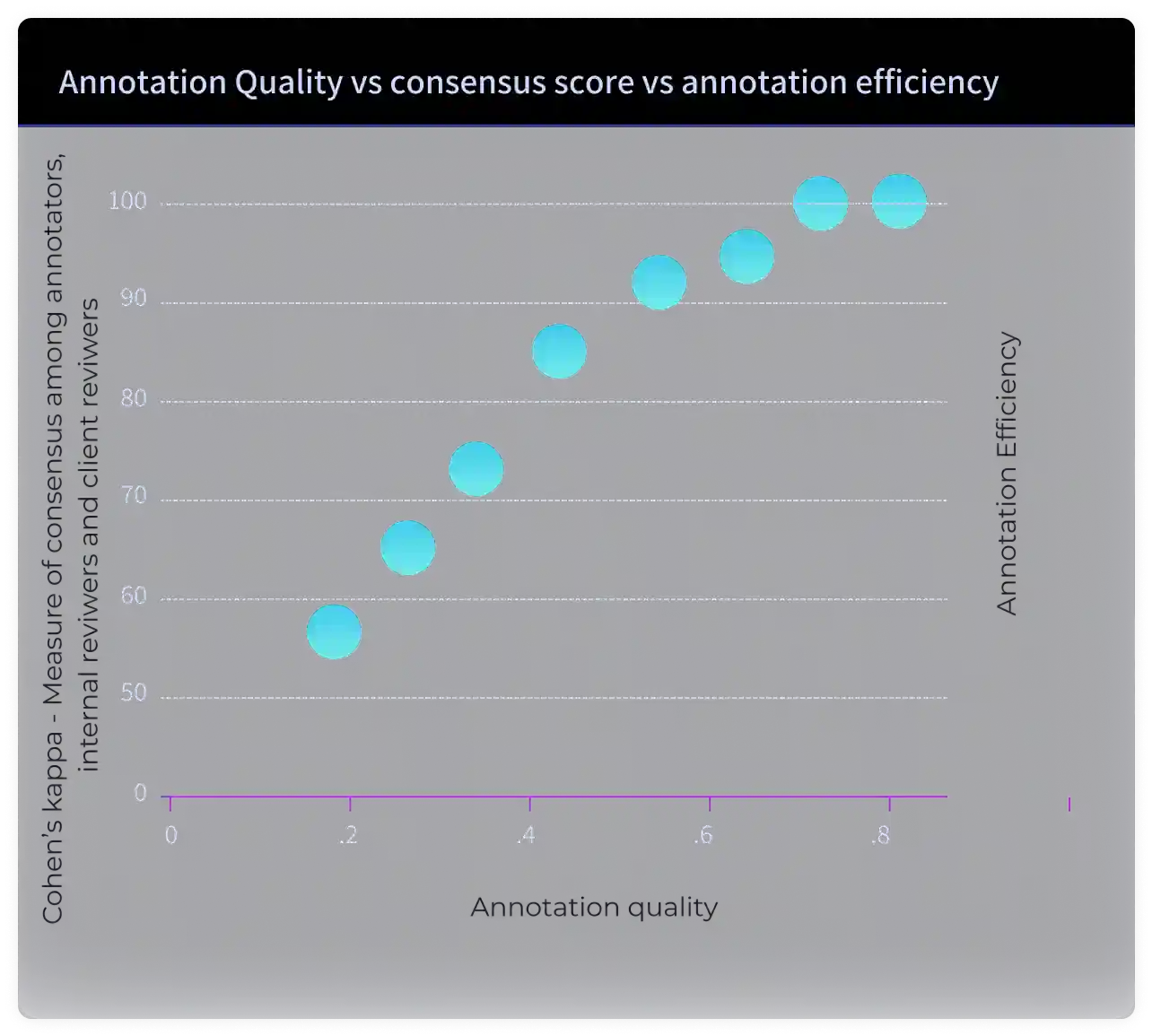
Annotation Consistency (Cohen's Kappa) : 0.45 Moderate agreement among annotators, internal reviewers, and client reviewers led to more doubt clearing sessions and maintenance of data around annotation benchmarks and mistakes.
Annotation Efficiency Metrics:5 iterations were required to achieve the acceptance levels of 95 % by client.
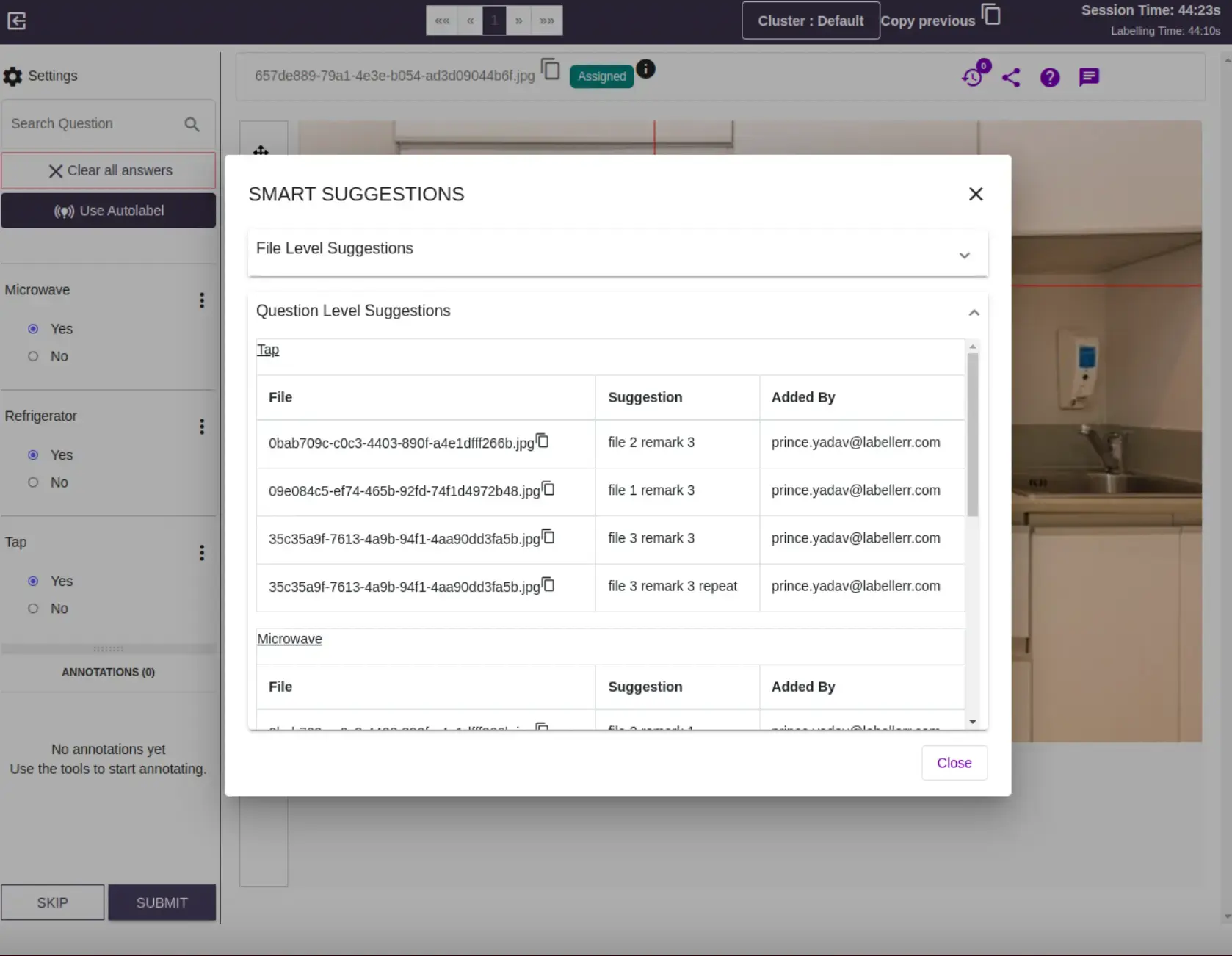
After implementing real-time smart feedback :Annotation Consistency (Cohen's Kappa): 0.75Past data could be used to guide the parties in the annotations process. Users had access to similar images which gave relevant suggestions on annotations being done ( in real time ). Doubt clearing sessions are not required.
Improved Annotation Efficiency Metrics : Start from 1st iteration itself
Directly Export of Visualizations in cloud bucket
These is the most unique feature allowing ML teams in experimentation or prototype phase to directly use the annotation done by human labelers in their downstream apps.
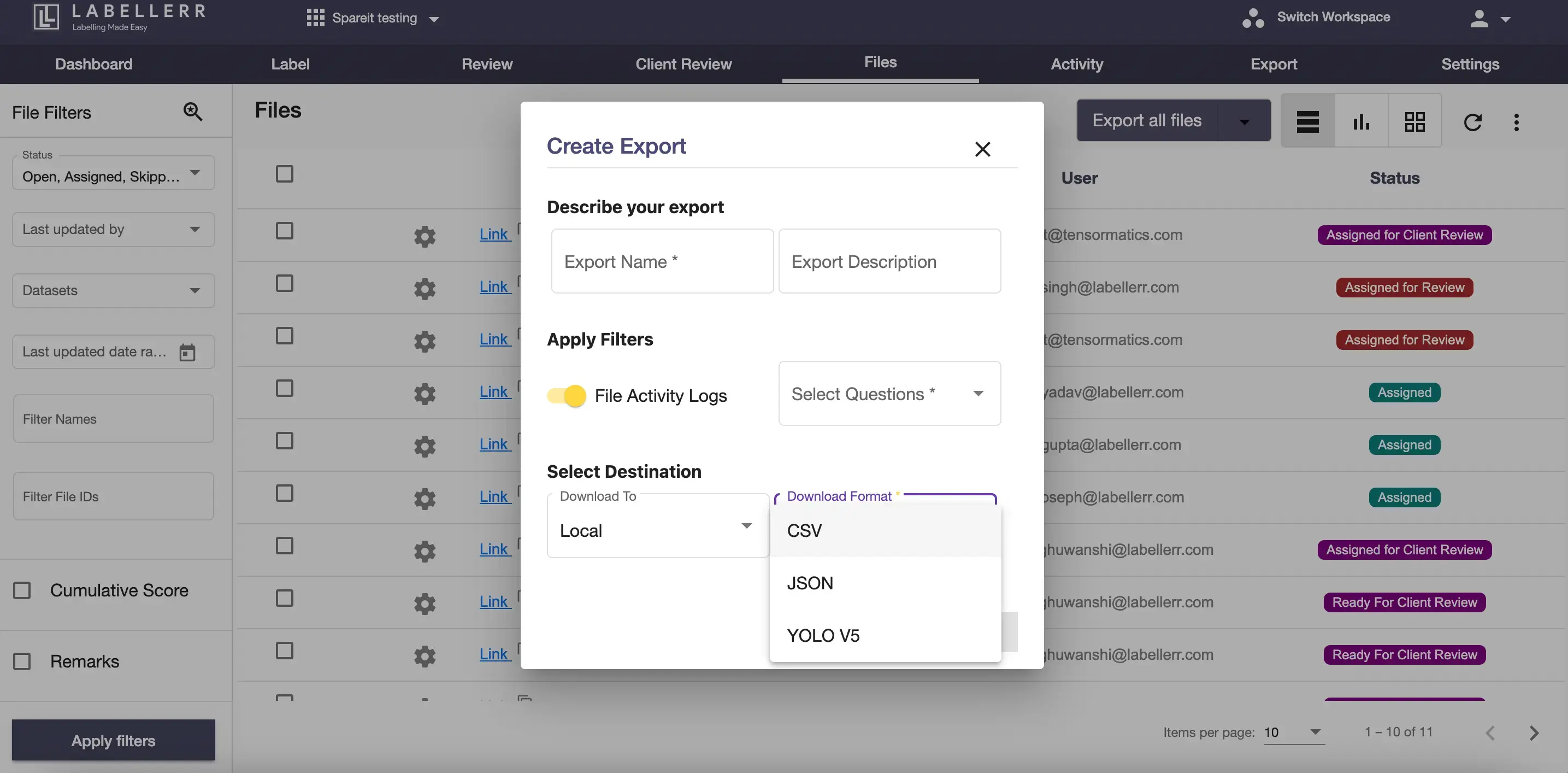
This feature allows them to get early validation from customers and investors without worrying about model training and deploying them to get the feedback of usability of the use case. Save time and cost before seeing the value of computer vision models performance in real time.
We roll out these improvements across our user base, we encourage you to leverage our dashboard for better insights.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
