

MiniMax‑M1: 1M‑Token Open‑Source Hybrid‑Attention AI
Meet MiniMax‑M1: a 456 B‑parameter, hybrid-attention reasoning model under Apache 2.0. Thanks to a hybrid Mixture‑of‑Experts and lightning attention, it handles 1 M token contexts with 75% lower FLOPs—delivering top-tier math, coding, long‑context, and RL‑based reasoning.


MiniMax is a leading artificial intelligence company based in Shanghai, with a significant presence in Singapore, specializing in the development of large language models (LLMs) and multimodal AI systems. To learn more about selecting the appropriate language model, see our guide on Choosing the Right LLM.
Recently, MiniMax has released a powerful new AI model called MiniMax-M1. It is the world's first open-weight, large-scale reasoning model built with a unique hybrid-attention architecture.
"Open-weight" means its core components are available for developers to use and build upon.
The main goal of MiniMax-M1 is to solve one of the biggest challenges in AI today: how to process incredibly long amounts of information like entire books or large codebases efficiently and without losing track of important details.
In this article, we will explore the new technology behind MiniMax-M1, look at its key features, see how it performs on real-world tests, and discuss who can benefit most from using it.
What's New? The Technology Behind MiniMax-M1
MiniMax-M1 introduces several groundbreaking technologies that set it apart.
1. The Hybrid MoE + Lightning Attention Architecture
MiniMax-M1 uses a smart design that combines two key technologies:
- Mixture-of-Experts (MoE): Think of this like a team of specialists. The model has a massive total size of 456 billion parameters, but for any given task, it only uses a fraction of that 45.9 billion active parameters. This means only the most relevant "expert" parts of the model work on a problem, making it very efficient.
- Lightning Attention: This is the game-changer. Traditional "attention" mechanisms in AI become very slow and require a lot of computing power when dealing with long texts.
Lightning Attention is a new, highly efficient method that allows the model to process huge amounts of data with far less power.
In fact, at a generation length of 100,000 tokens, MiniMax-M1 uses only 25% of the computing power (FLOPs) compared to other advanced models like DeepSeek-R1.
2. A Massive 1 Million Token Context Window
MiniMax-M1 can handle a 1 million token context window. To put that into perspective:
- A "token" is like a word or part of a word.
- 1 million tokens is roughly equal to 750,000 words, or the entire Lord of the Rings trilogy.
- This is 8 times the context size of other leading long-context models like DeepSeek-R1.
This massive context window means MiniMax-M1 can read and analyze entire books, research papers, or large code repositories at once, without forgetting what it read at the beginning.
3. The CISPO Reinforcement Learning Algorithm
AI models are trained using methods like Reinforcement Learning (RL) to improve their reasoning. MiniMax developed a new, more efficient RL algorithm called CISPO.
This algorithm helped them train the massive M1 model in just three weeks using 512 H800 GPUs, a remarkable achievement that shows how efficient their training process is.
Key Features of the model
MiniMax-M1 is designed to excel in three main areas:
- Advanced Long-Context Reasoning: The model can read and analyze vast amounts of information at once.
It can find specific details ("needles in a haystack") and connect ideas across multiple long documents without getting lost. - Robust Tool Use Capabilities: MiniMax-M1 is built to be an excellent base model for AI Agents.
It can understand and use external tools like calculators, web search, or booking APIs to complete complex, multi-step tasks while following specific rules. - High-Level Problem Solving: The model is made for "production-level" coding tasks and can solve difficult, competition-grade mathematical problems, which shows its strong logical reasoning abilities.
Our Hands-On Evaluation
We tested the MiniMax-M1-80K model (the more powerful version) on five scenarios designed to check its core claims.
Scenario 1: Long-Context Document Analysis
This test checks the 1 million token context window.
Analyze these 4 research papers (with a very long text context) and compare their neural architecture innovations.
1. How do their attention mechanisms differ?
2. What efficiency claims are verified?
3. Identify unsolved challenges mentioned across all papers.
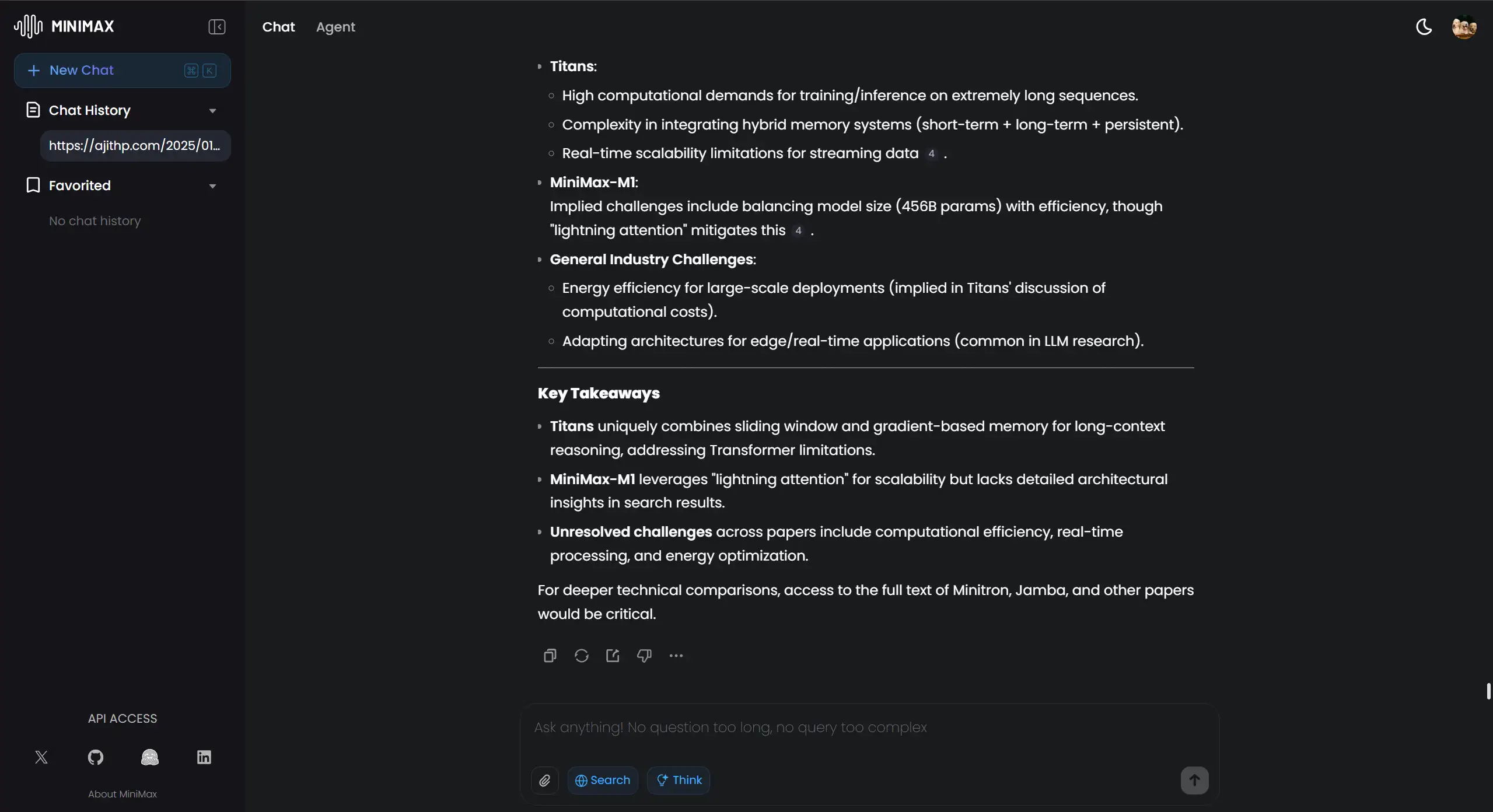
minimax m1 long context
What We Looked For: Did it accurately find and compare details from all four documents? Did it maintain consistency throughout its analysis?
Scenario 2: Agentic Tool Use
This tests its ability to act as an AI agent following rules.
Browse this website https://huggingface.co/models I am building a voice assistant that can take input as a voice and use asr model to convert it to text and understand the query via llm and then return me the output via a tts model I want to know the best 1. ASR model 2. LLM 3. TTS model Give me atleast 5 combos and also my vram size is 12gb so be mindful of that. Create a report on this and how can I build something like this. I also want to create AI agents, vision AI Agent(that can perform vision tasks like image classification, object detection, segmentation) from this and connect MCP with this llm so choose wisely.
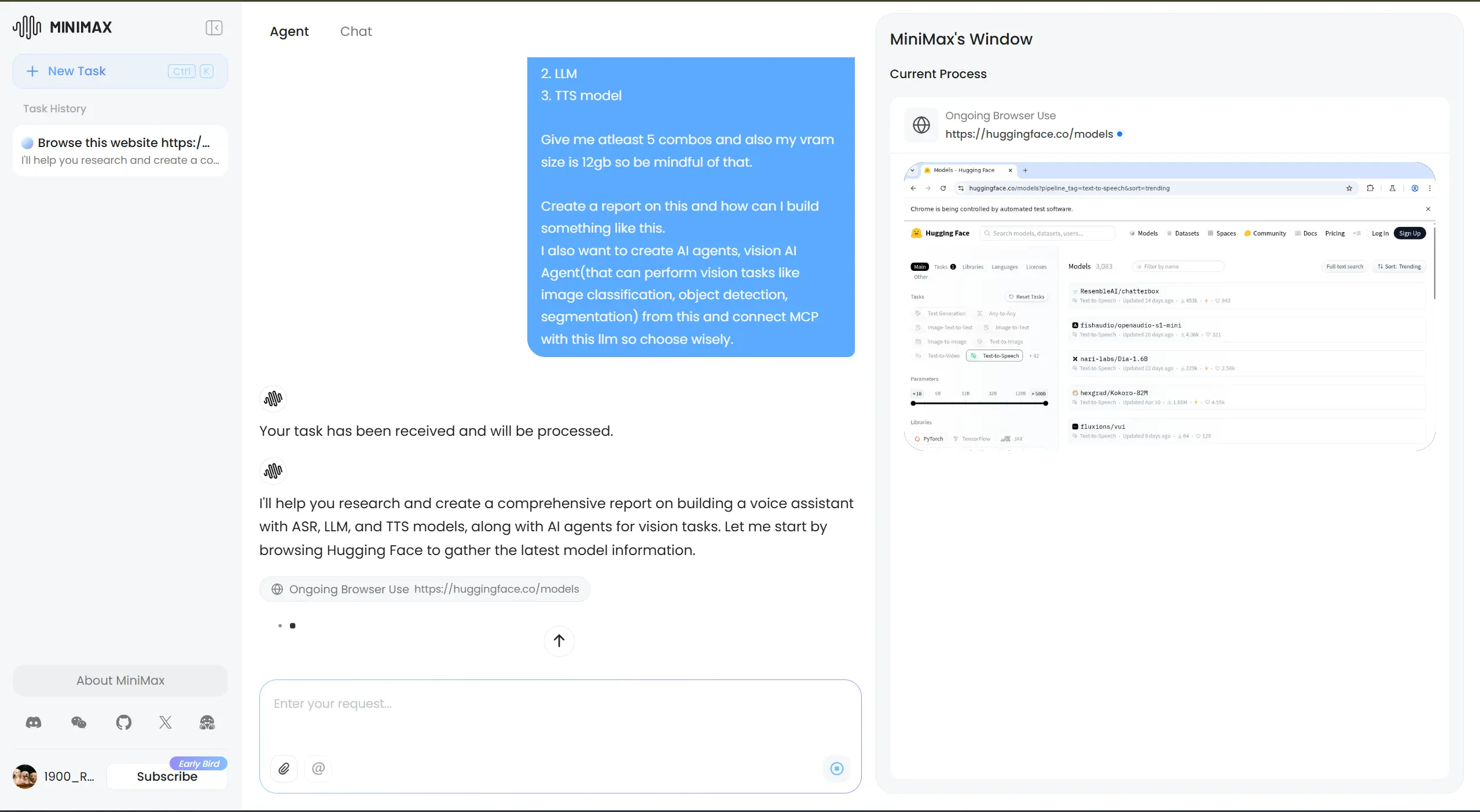
Agentic use of Minimax
What We Looked For: Did it correctly apply all rules? Was its proposed sequence of tool calls logical and accurate?
Scenario 3: Software Engineering
This tests its real-world coding and problem-solving skills.
Fix this Python bug:
def calculate_stats(data):
return {'mean': sum(data)/len(data), 'std': (sum([(x-mean)**2 for x in data])/len(data))**0.5}
# The code fails on empty lists. Add proper NaN handling and write test cases to verify the fix.
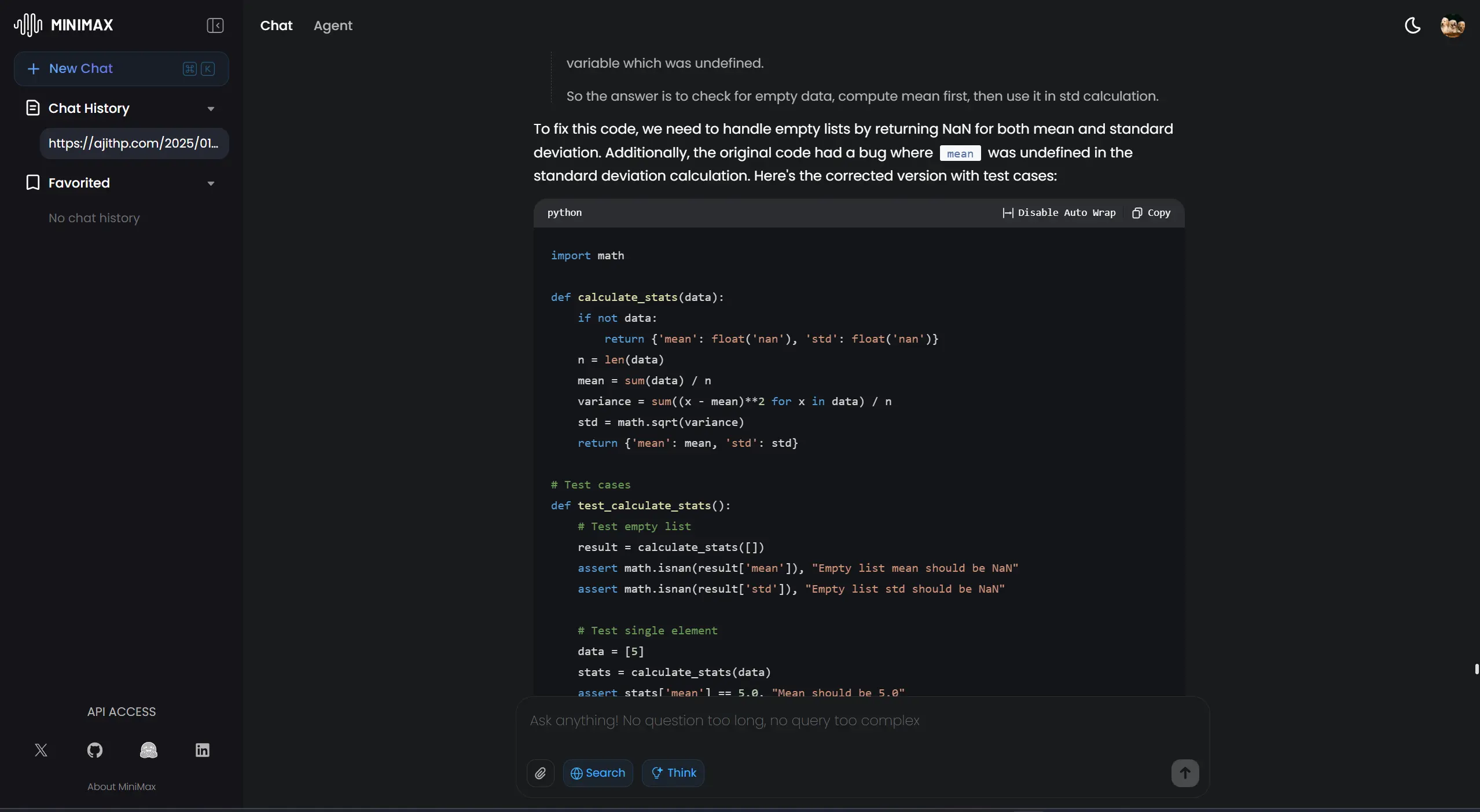
Software Engineering Minimax
What We Looked For: Did it produce correct, runnable code? Did it handle the specific error case? Were the test cases it created good enough to verify the fix?
Scenario 4: Mathematical Reasoning
This tests its ability to build a formal, logical proof.
"Prove that for all integers n ≥ 1, the expression 7^n + 3^n - 2 is divisible by 8. Use mathematical induction, showing the complete base case, inductive hypothesis, and inductive step."
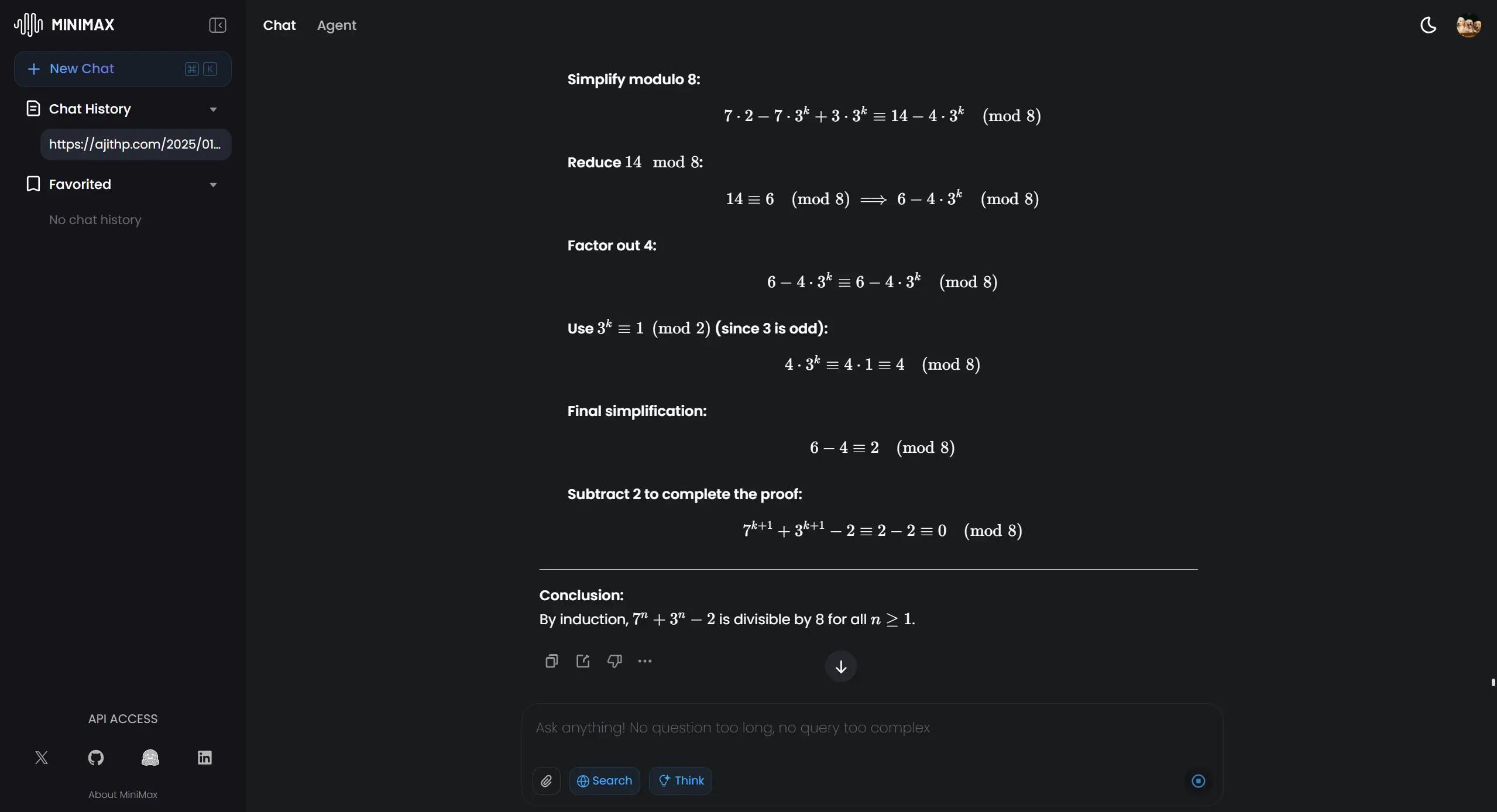
Mathematical Reasoning Minimax
What We Looked For: Was the proof mathematically correct? Were all the required steps of the induction present and clearly explained?
Scenario 5: Competitive Programming
This tests its ability to create highly optimized algorithms.
"Write a Python function that finds the longest palindromic substring in a given string 's'. The solution must have a time complexity of O(n). Constraints: - Input: string s (1 ≤ len(s) ≤ 10^5) - Output: the longest palindromic substring Include handling for edge cases like an empty string, a single-character string, and a string that is a full palindrome."
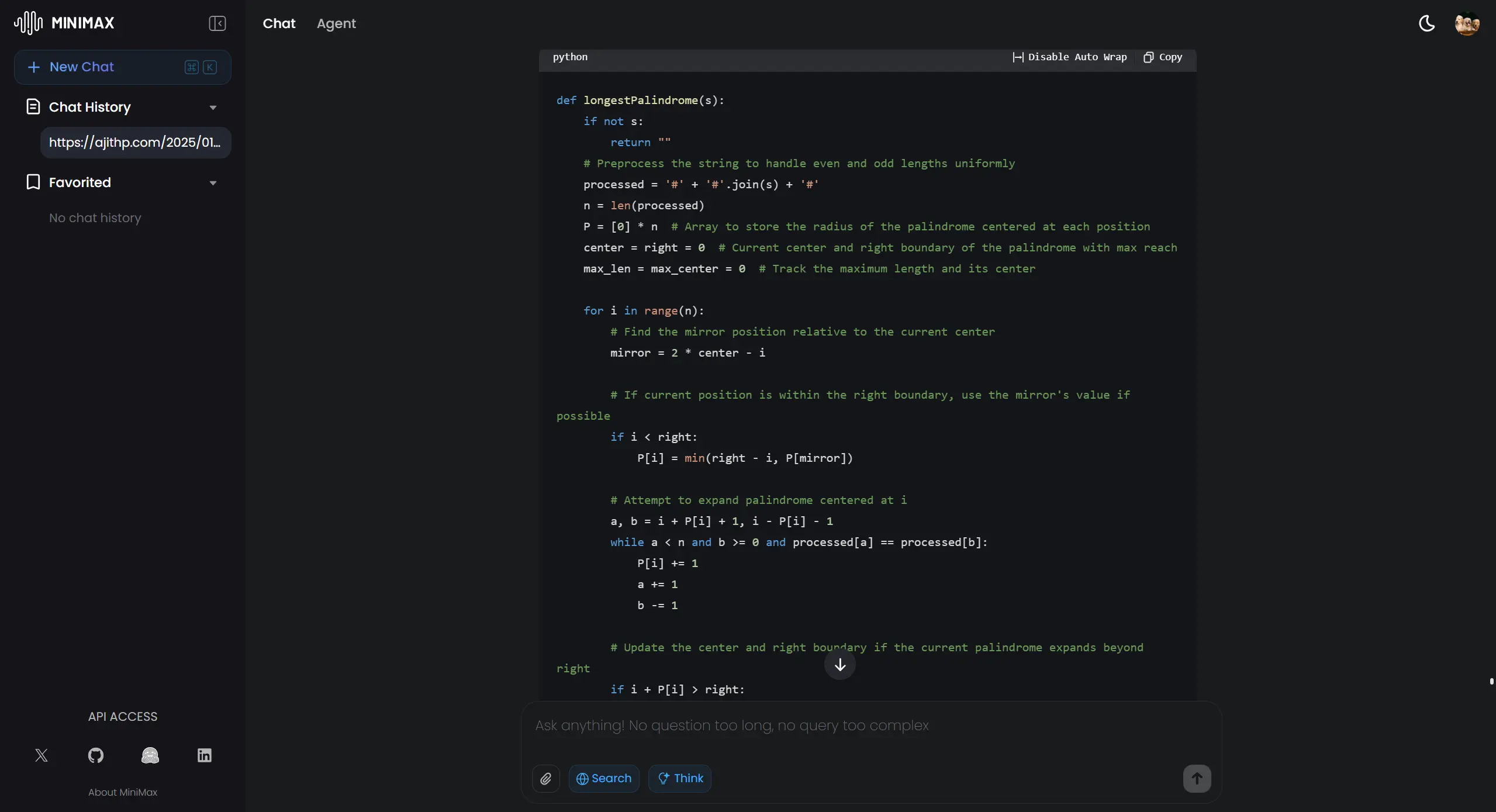
Competitive Programming Minimax
What We Looked For: Did the algorithm meet the strict O(n) time requirement? Did it handle all specified edge cases correctly?
Where Can You Use MiniMax-M1?
MiniMax-M1 is a powerful tool for a range of professional applications.
- For Enterprises: You can use it to automate complex workflows, such as analyzing long legal contracts, financial reports, or technical manuals. It is also great for building internal search tools that can read an entire company's documentation at once.
- For Scientific Researchers: You can speed up literature reviews by having the AI read and summarize hundreds of research papers. It can also help you find patterns and connections across massive datasets.
- For AI Developers: You can build sophisticated AI agents that use multiple tools to help customers, manage logistics, or perform complex online tasks.
- For Software Engineers: You can use it as an advanced coding assistant for debugging complex codebases, modernizing old systems, or generating highly optimized code.
Is MiniMax-M1 Consumer-Friendly?
So, who is this model really for?
- For AI Developers and Researchers: Yes, absolutely. MiniMax-M1 is a fantastic tool. Because it is open-weight, you can inspect it and build on top of it.
Its efficiency means lower computing costs for your research and development. The 1 million token context opens up new possibilities for applications that were previously impossible. - For the Everyday Consumer or Hobbyist: Not directly. Running a model of this size requires a lot of computing power, including powerful GPUs with a lot of VRAM.
Most consumers will experience MiniMax-M1's power through the apps and services that developers build with it, rather than running it on their own computers. - For Businesses: Yes, with the right setup. For companies that can invest in the necessary hardware, MiniMax-M1 offers a powerful, self-hostable alternative to relying on third-party APIs. This gives you more control, privacy, and customization over your AI.
Conclusion
MiniMax-M1 marks a major step forward for open-weight AI. Its innovative hybrid-attention architecture and Lightning Attention mechanism have solved a major challenge, delivering an AI model that can handle a massive 1 million token context with incredible efficiency.
Our tests confirm that MiniMax-M1 excels in the areas it was designed for: it skillfully handles complex tool-use scenarios, shows a deep understanding of long documents, and provides solid solutions for real-world software engineering problems.
While it may not be the absolute best in every single category (like competitive math), its unique combination of extreme context length, efficiency, and strong reasoning makes it one of the most exciting and practical models available for building the next generation of AI agents and enterprise solutions.
Ready to try it yourself?
- Hugging Face Model: MiniMaxAI/MiniMax-M1-40k
- Online Demo: chat.minimax.io
- Research Paper: arXiv:2506.13585
FAQs
Q1: What makes MiniMax‑M1 unique?
MiniMax‑M1 is the first open-source model combining Mixture‑of‑Experts with lightning attention—handling extremely long contexts efficiently under Apache 2.0.
Q2: How cost-effective is its training?
Thanks to CISPO RL and hybrid architecture, the model was trained at ~1/20th the cost of DeepSeek‑R1 or GPT-4—only ~$535K.
Q3: What can it do best?
It excels at long-context tasks (1 M tokens), advanced math, coding, software engineering, and agentic tool use.
Q4: Is it ready for real-world deployment?
Yes—checkpoints are on GitHub/Hugging Face, works with vLLM/Transformers, and supports efficient function calling and API integration.
Q5: How is it licensed?
Released under the permissive Apache‑2.0 license with open weights—ideal for commercial and research use.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
