

Mask2Former: Hands-on Tutorial Guide
Learn how to perform semantic, instance, and panoptic segmentation using Mask2Former-a universal, efficient, and accurate model that streamlines image segmentation tasks across diverse applications.


Have you ever been exhausted by the sheer complexity of deploying multiple specialized models for different segmentation tasks?
If your team has struggled to manage different architectures, training setups, and deployment pipelines for each task, you know how much time and effort it can take.
The core question is: must comprehensive image understanding always be this fragmented and resource-intensive?
Think about this: industry benchmarks and research keep pushing progress in all segmentation types.
In the past, getting top results in semantic segmentation (labeling every pixel with a class like "road" or "sky") usually required a different model and method than for instance segmentation (finding and outlining each individual "car" or "person").
Panoptic segmentation, which combines both, added even more complexity.
This split approach often forces teams to spend up to three times more effort on managing models, fine-tuning, and integrating everything into a full scene understanding system.
Meet Mask2Former. This innovative model from Meta AI (FAIR) isn’t just a small upgrade; it changes the game.
It solves the problem of using separate models by offering one universal architecture that handles all segmentation types with state-of-the-art performance.
Mask2Former simplifies everything by rethinking how queries work and using masked attention to deliver a powerful, efficient solution.
If you're a computer vision researcher, an ML engineer wanting smoother MLOps, or someone looking to build strong and flexible segmentation systems with less complexity, this deep dive into Mask2Former is for you.
Let’s see how well it performs in real-world cases.
What is Segmentation?
In computer vision, image segmentation is the process of partitioning a digital image into multiple segments (sets of pixels, also known as image objects or regions).

Segmentations using Mask2Former
The goal of segmentation is to simplify and/or change the representation of an image into something more meaningful and easier to analyze.
Essentially, instead of just knowing what is in an image (like in image classification) or where objects are in a general sense (like in object detection with bounding boxes), segmentation aims to assign a label to every single pixel in the image.
Each pixel belonging to the same object or region gets the same label. The output is typically a segmentation mask, which is an image where each pixel's value corresponds to its assigned class or instance.
Types of Image Segmentation
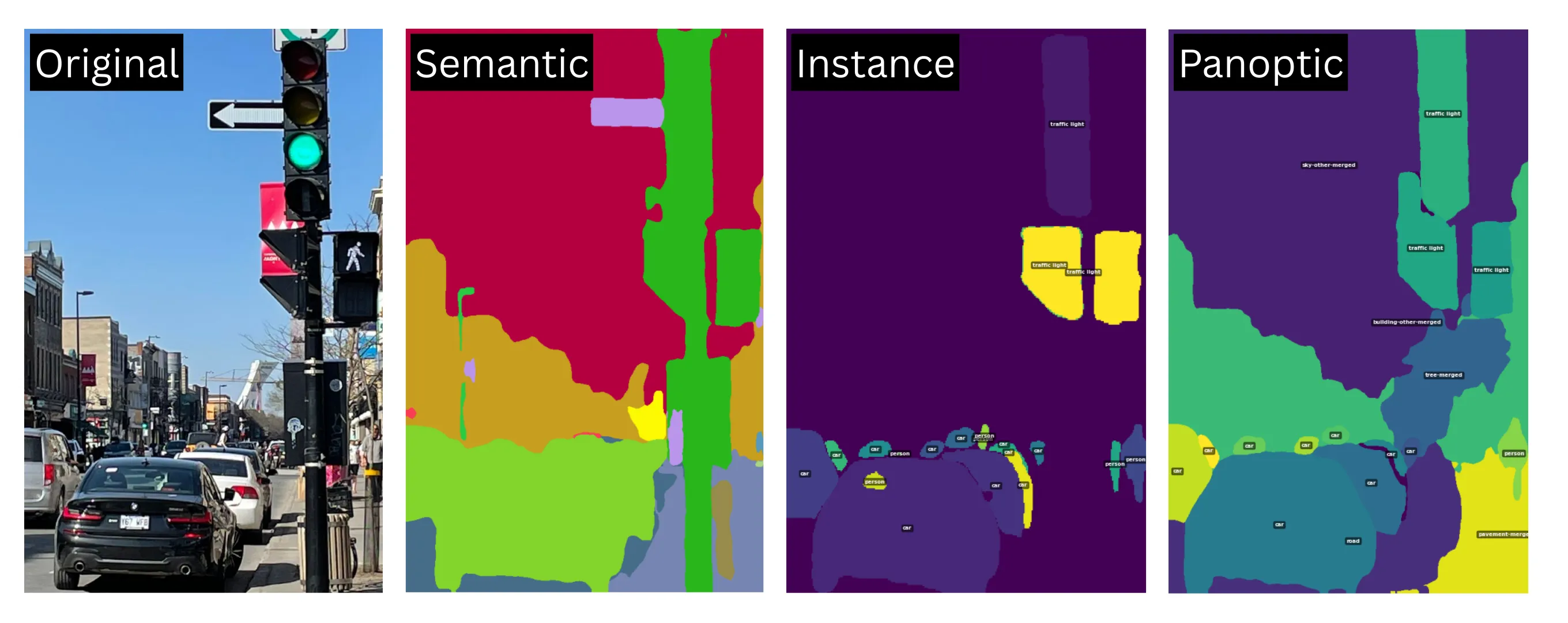
Different types of segmentation
There are three main types of image segmentation, each addressing a different level of detail:
- Semantic Segmentation:
- Goal: To classify each pixel in the image with a semantic label corresponding to a class (e.g., "road," "sky," "building," "car," "person").
- Key Characteristic: It treats all instances of the same object class as one entity. For example, all cars in an image will be labeled as "car," without distinguishing between individual cars.
- Output: A mask where each pixel is colored or valued according to its class.

semantics segmentation
- Instance Segmentation:
- Goal: To detect and delineate each distinct object instance in an image. It combines object detection (locating objects) with semantic segmentation (classifying them at the pixel level).
- Key Characteristic: It distinguishes between different instances of the same class. For example, if there are three cars, it will identify and segment "car_1," "car_2," and "car_3" separately.
- Output: A set of masks, one for each detected object instance, along with their class labels.

Instance segmentation
- Panoptic Segmentation:
- Goal: To provide a comprehensive, unified understanding of the scene by performing both semantic segmentation for all pixels and instance segmentation for "object" classes (countable objects like cars, people).
- Key Characteristic: Every pixel in the image is assigned a semantic label and, if it belongs to a "object" class, an instance ID. Pixels belonging to "stuff" classes (amorphous regions like sky, road, grass) only get a semantic label. It ensures there are no overlapping segments.
- Output: A single mask where each pixel has a class label, and "thing" pixels also have a unique instance ID.
Panoptic segmentation
What is Mask2Former?
Mask2Former is a universal image segmentation architecture introduced by Meta AI Research in 2022.
Unlike traditional segmentation models that are tailored for specific tasks-like semantic, instance, or panoptic segmentation-Mask2Former is designed to handle all these tasks within a single framework.
It builds upon the DETR (DEtection TRansformer) architecture and leverages a transformer decoder to predict segmentation masks for each object in an image
What Makes Mask2Former Different from Other Segmentation Models?
Mask2Former stands out from earlier segmentation models due to two core innovations:
1. Masked Attention Mechanism
- Traditional transformer-based models use cross-attention, allowing the decoder to attend to all pixels in an image, including background regions. This can introduce noise and reduce segmentation accuracy, especially for instance segmentation.
- Mask2Former introduces a masked attention mechanism, restricting the decoder’s focus to only the foreground regions of each object. By masking out the background in the attention weights, Mask2Former can better isolate relevant features, leading to more precise segmentation and improved efficiency.
2. Multi-Scale Decoder
- Many earlier architectures struggle with detecting objects of varying sizes, particularly small objects.
- Mask2Former addresses this with a multi-scale decoder, enabling it to process features at different resolutions. Each transformer decoder layer works with features at a specific scale, allowing the model to capture both fine details and broader context. This significantly enhances its ability to segment both small and large objects accurately.
3. Universal Segmentation Architecture
- Previous models often required separate architectures or specialized knowledge for each segmentation task, making development and deployment complex and resource-intensive.
- Mask2Former’s universal design means a single model can be trained and deployed for semantic, instance, and panoptic segmentation, streamlining workflows and reducing the need for task-specific models.
4. Improved Efficiency
- The combination of masked attention and transformer decoders makes Mask2Former not only more accurate but also more computationally efficient compared to traditional convolutional neural network (CNN) approaches.
How to implement various segmentations using Mask2Former?
We can perform segmentation using Mask2Former by Huggingface's transformer library.
There are various open-source models available to use: Mask2Former Models
Let's implement it type-wise:
First, we have to install the required libraries in our environment,
!pip install transformers torch scipy matplotlib opencv-python pillow scikit-image
Import those modules into our environment,
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
import torch
from PIL import Image
import requests
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from skimage.measure import regionprops
We need to create some helper functions to visualize our detections,
def visualize_segmentation(results, image, model, alpha=0.4):
"""
Visualizes segmentation results with object names.
"""
segmentation = results['segmentation'].numpy()
segments_info = results['segments_info']
height, width = segmentation.shape
color_mask = np.zeros((height, width, 3), dtype=np.uint8)
# Assign random color to each instance
instance_colors = {
segment['id']: np.random.randint(0, 255, size=3)
for segment in segments_info
}
for segment in segments_info:
mask = segmentation == segment['id']
color_mask[mask] = instance_colors[segment['id']]
# Overlay mask on image with alpha blending
image_np = np.array(image).astype(np.uint8)
overlay = (1 - alpha) * image_np + alpha * color_mask
overlay = overlay.astype(np.uint8)
plt.figure(figsize=(12, 8))
plt.imshow(overlay)
ax = plt.gca()
plt.axis('off')
# Draw color lines and names on the right edge
line_height = 25
spacing = 10
y0 = spacing
for segment in segments_info:
label_name = model.config.id2label[segment['label_id']]
color = instance_colors[segment['id']] / 255
# Draw color line
rect = mpatches.Rectangle(
(width - 30, y0), 20, line_height,
linewidth=0, edgecolor=None, facecolor=color, alpha=1.0, transform=ax.transData, clip_on=False
)
ax.add_patch(rect)
# Draw label text
ax.text(
width - 35, y0 + line_height / 2,
f"{label_name} ({segment['score']:.2f})",
va='center', ha='right', fontsize=11,
color='white' if np.mean(color) < 0.5 else 'black',
bbox=dict(facecolor=(0, 0, 0, 0.2), edgecolor='none', boxstyle='round,pad=0.2')
)
y0 += line_height + spacing
plt.show()
def draw_binary_mask(results, model):
segmentation = results['segmentation']
segments_info = results['segments_info']
seg_np = segmentation.numpy() if hasattr(segmentation, 'numpy') else np.array(segmentation)
plt.figure(figsize=(15, 10))
plt.imshow(seg_np)
ax = plt.gca()
# Map segment id to label id
segment_to_label = {segment['id']: segment['label_id'] for segment in segments_info}
# For each segment, find centroid and plot label
for segment in segments_info:
segment_id = segment['id']
label_id = segment['label_id']
label_name = model.config.id2label[label_id]
mask = (seg_np == segment_id)
props = regionprops(mask.astype(np.uint8))
if props:
y, x = props[0].centroid
ax.text(
x, y, label_name,
color='white', fontsize=8, weight='bold',
ha='center', va='center',
bbox=dict(facecolor='black', alpha=0.5, boxstyle='round,pad=0.2')
)
plt.axis('off')
plt.show()
def visualize_semantic_map(predicted_map, original_image, model, alpha=0.5):
"""
Visualizes the semantic segmentation map over the original image.
The alpha parameter controls the transparency of the mask (0=transparent, 1=opaque).
"""
import torch
import numpy as np
import matplotlib.pyplot as plt
# Generate a random color palette
color_palette = np.random.randint(0, 255, size=(len(model.config.id2label), 3))
color_seg = np.zeros((predicted_map.shape[0], predicted_map.shape[1], 3), dtype=np.uint8)
for label in torch.unique(predicted_map):
color_seg[predicted_map == label] = color_palette[label]
# Blend the original image and the color mask using the alpha parameter
img = np.array(original_image) * (1 - alpha) + color_seg * alpha
img = img.astype(np.uint8)
plt.figure(figsize=(15, 10))
plt.imshow(img)
plt.axis('off')
plt.show()
Now let's perform segmentation type-wise. I will create a function for each type.
Semantics Segmentation
def run_semantic_segmentation(image_path):
"""Performs semantic segmentation"""
# Load model and processor
checkpoint= "facebook/mask2former-swin-large-ade-semantic"
processor = AutoImageProcessor.from_pretrained(checkpoint)
model = Mask2FormerForUniversalSegmentation.from_pretrained(checkpoint)
# Load image
if image_path.startswith('http'):
image = Image.open(requests.get(image_path, stream=True).raw)
else:
image = Image.open(image_path)
# Process and predict
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# Post-process
predicted_map = processor.post_process_semantic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
return predicted_map, image, model
Instance Segmentation
def run_instance_segmentation(image_path):
"""
Runs instance segmentation on an image
"""
# Load model and processor
checkpoint = "facebook/mask2former-swin-large-coco-instance"
processor = AutoImageProcessor.from_pretrained(checkpoint)
model = Mask2FormerForUniversalSegmentation.from_pretrained(checkpoint)
# Load image
if image_path.startswith('http'):
image = Image.open(requests.get(image_path, stream=True).raw).convert("RGB")
else:
image = Image.open(image_path).convert("RGB")
# Preprocess and inference
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# Post-process
results = processor.post_process_instance_segmentation(
outputs, target_sizes=[image.size[::-1]]
)[0]
# Visualize
return results, image, model
Panoptic Segmentation
def run_panoptic_segmentation(image_path):
"""Performs panoptic segmentation"""
# Load model and processor
checkpoint = "facebook/mask2former-swin-base-coco-panoptic"
processor = AutoImageProcessor.from_pretrained(checkpoint)
model = Mask2FormerForUniversalSegmentation.from_pretrained(checkpoint)
# Load image
if image_path.startswith('http'):
image = Image.open(requests.get(image_path, stream=True).raw)
else:
image = Image.open(image_path)
# Process and predict
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# Post-process
results = processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
return results, image, model
Visualizing the Segmentation
To perform and visualize, we just use this code
Semantic Segmentation
predicted_map, image, model = run_semantic_segmentation(url)
# Visualize
visualize_semantic_map(predicted_map, image, model, alpha=0.6)
visualize_semantic_map(predicted_map, image, model, alpha=1)

result of Semantic Segmentation
Instance Segmentation
instance_results, image, model = run_instance_segmentation(url)
# visualize
draw_binary_mask(instance_results, model)
visualize_segmentation(instance_results, image, model, alpha=0.5)
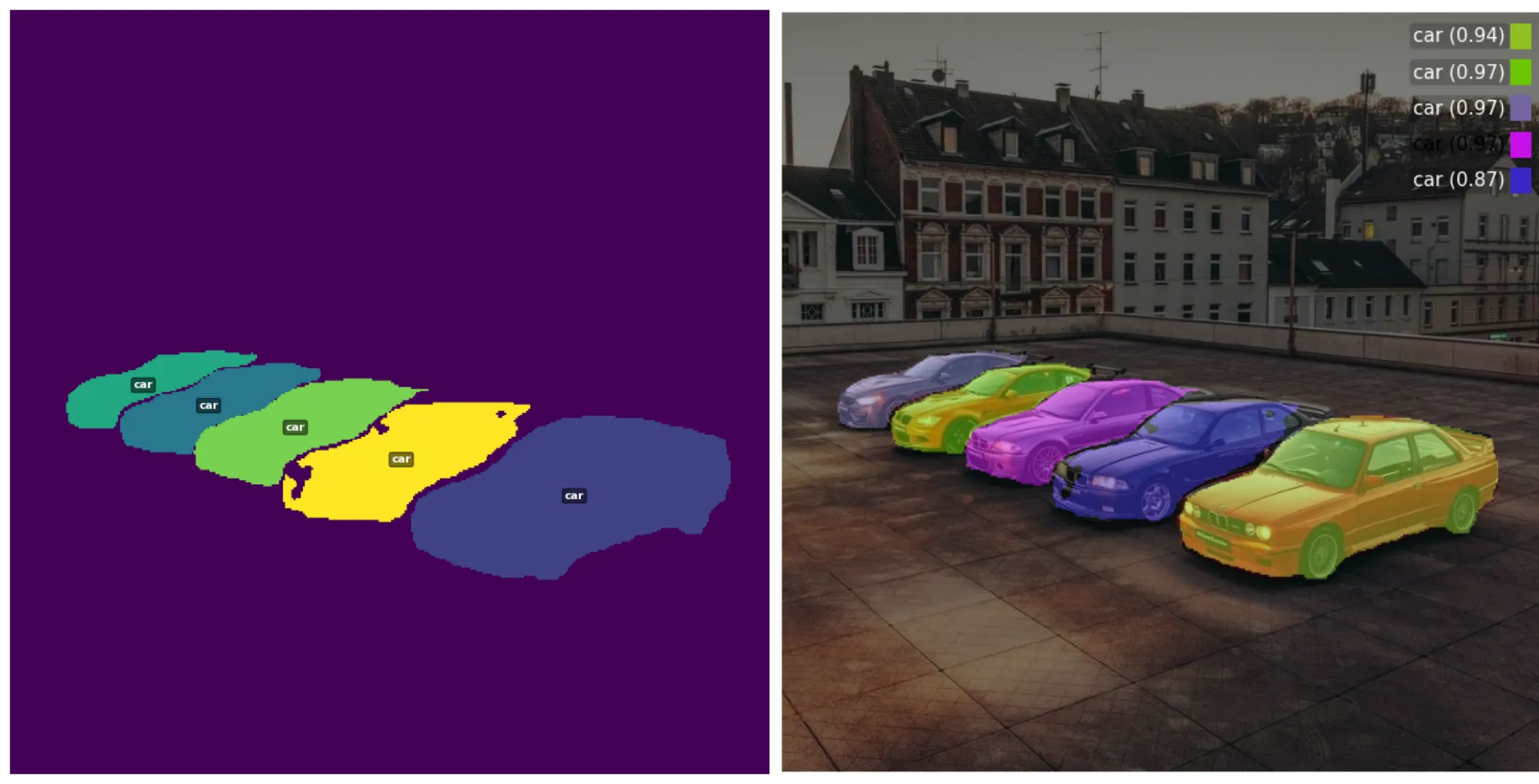
result of Instance Segmentation
Panoptic Segmentation
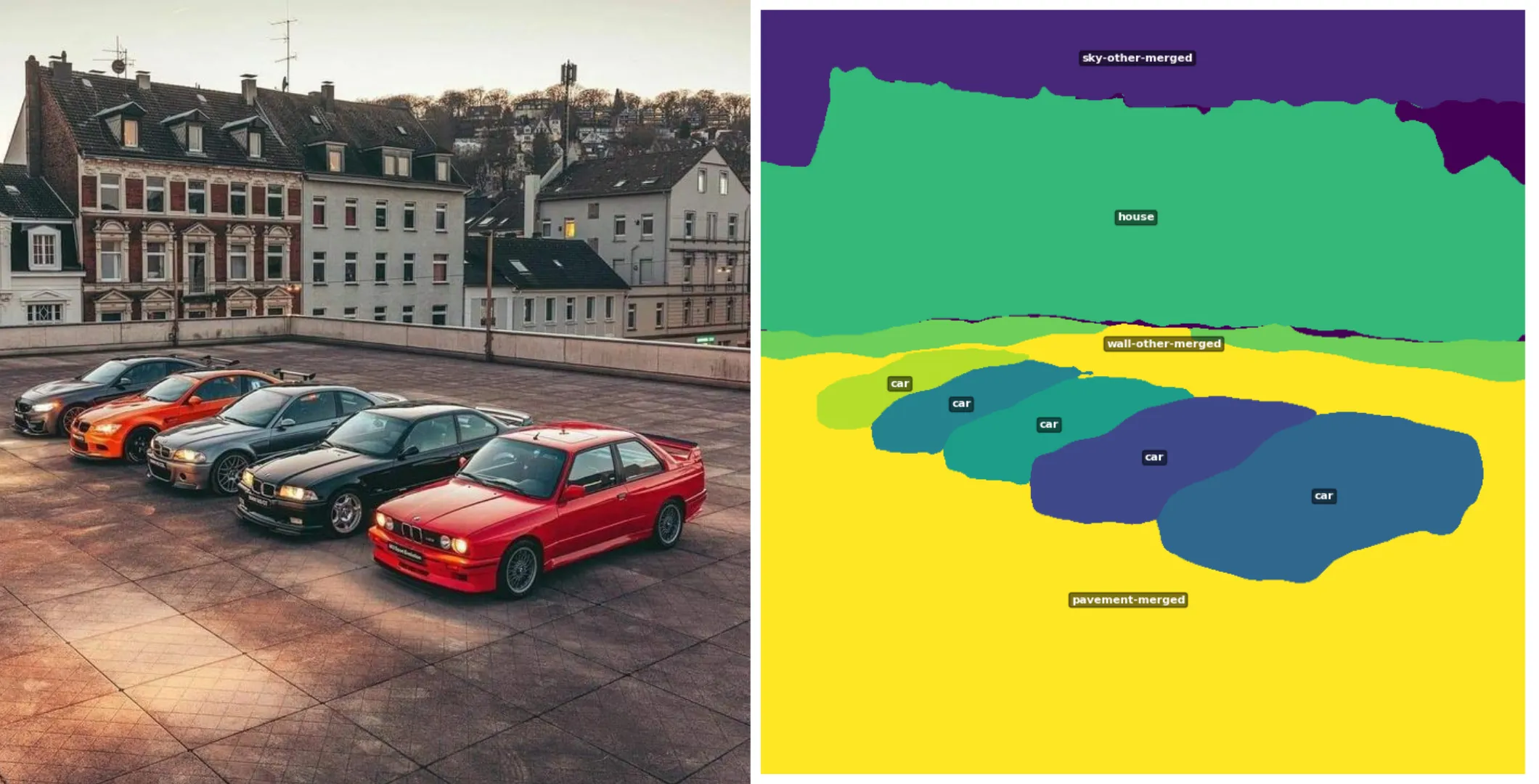
panoptic_results, image, model = run_panoptic_segmentation(url)
# Visualize
draw_binary_mask(panoptic_results, model)
visualize_segmentation(panoptic_results, image, model, alpha=0.6)

result of Panoptic Segmentation
Use cases of Mask2Former in different fields.
Mask2Former’s universal segmentation capabilities make it a powerful tool across a wide range of industries.
Here are some of the most prominent use cases:
1. Autonomous Vehicles
Mask2Former is used to segment and identify objects such as cars, pedestrians, traffic signs, and road lanes in real time, enhancing the perception systems of self-driving cars and advanced driver-assistance systems.
2. Medical Imaging
Mask2Former can accurately delineate tumors, organs, or lesions in radiology images, supporting diagnosis and treatment planning.
3. Robotics
Robots use Mask2Former to identify and separate objects in cluttered environments, improving object manipulation and grasping tasks.
Conclusion
Mask2Former has redefined the landscape of image segmentation by providing a unified, efficient, and highly accurate framework for semantic, instance, and panoptic segmentation tasks.
Throughout this blog, we explored not only what makes Mask2Former unique-such as its masked attention mechanism, multi-scale feature processing, and efficient training strategies-but also demonstrated how to implement various segmentation tasks using this architecture.
With simple preprocessing, flexible configuration, and streamlined post-processing functions, Mask2Former enables practitioners to tackle diverse segmentation challenges without switching between multiple models or pipelines.
Whether you are segmenting everyday objects, medical images, or satellite data, Mask2Former’s universal approach and robust performance make it a go-to solution for both research and real-world applications.
By following the practical steps and examples provided, you can now leverage Mask2Former to perform state-of-the-art segmentation across your own datasets and projects, unlocking new possibilities in computer vision workflows.
FAQs
What segmentation tasks can Mask2Former perform?
Mask2Former supports semantic, instance, and panoptic segmentation within a single unified framework.
How is Mask2Former different from traditional segmentation models?
It uses masked attention and a multi-scale decoder, enabling more accurate and efficient segmentation across diverse tasks.
Is Mask2Former easy to use for custom datasets?
Yes, Mask2Former can be fine-tuned on custom datasets using standard preprocessing and postprocessing steps, making it accessible for various applications.
References

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
