

Machine learning steps: A complete guide for beginner in ML
Explore essential steps in machine learning, from collecting data to model training, evaluation, tuning, and prediction. Discover how each phase refines models for accurate, data-driven insights in real-world applications.

A machine learning system learns from historical data, builds a predictive model, and predicts its output whenever new data is obtained. The accuracy of the predicted output depends on the amount of data. Massive amounts of data help build better models that more accurately predict the output.
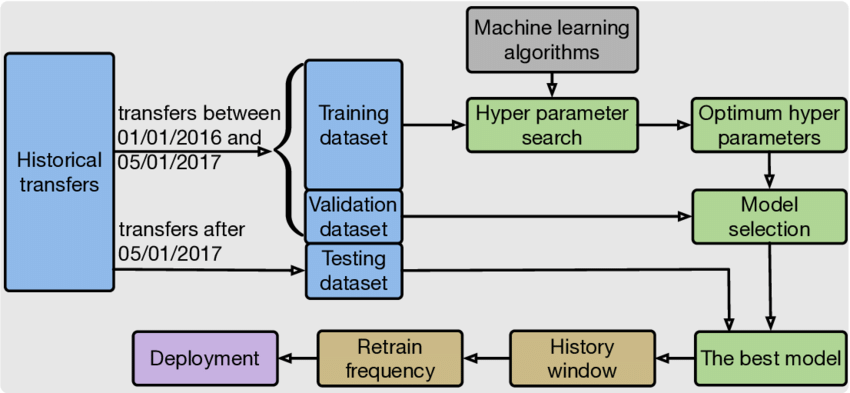
Suppose you have a complex problem that needs to be predicted. Instead of writing code, you can simply feed your data into common algorithms, and using these algorithms, your machine will build logic based on your data. and predict the output. Machine learning has changed the way we think about problems. The following block diagram shows how the machine learning algorithm works.
A Complete Guide to the ML process
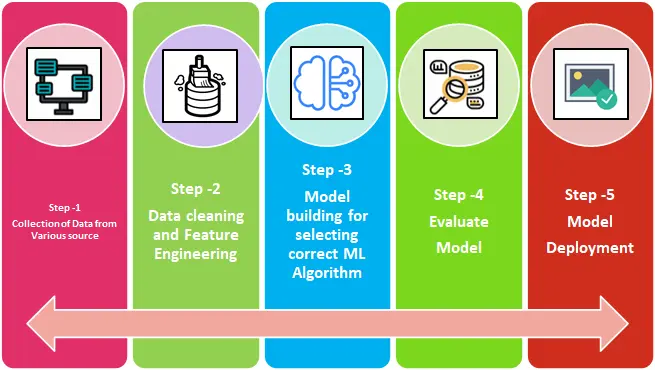
1. Collecting Data

The first step in the machine learning lifecycle is to transform raw data into clean data sets that are frequently shared and reused. If an analyst or data scientist has a problem with the data they receive, they need access to the original data and transformation scripts. There are many reasons why you might want to revert your model and data to an earlier version.
As you know, machines learn from the data they are given first. Collecting reliable data is paramount so that machine learning models can find the right patterns. The quality of the data you feed your machine determines the accuracy of your model. If you have inaccurate or outdated data, you will get irrelevant and inaccurate results or predictions. Make sure you are using data from a trusted source, as it directly influences the results of the model. Good data are relevant, have few missing or repeated values, and represent well the different subcategories or classes that are present.
2. Data Preparation
This data can come from various sources. B. enterprises, pharmaceutical companies, IoT devices, enterprises, banks, hospitals, etc. During the machine-learning phase, a large amount of data is provided. This is because as the amount of data increases, the machine adjusts itself to achieve the desired result. This output data can be used for analysis or fed as input to other machine learning applications or systems to train them. For students working on academic projects or research, it’s essential to ensure the data you’re using is reliable and original. To avoid issues with plagiarism or improper citation, consider running your data through a reliable free online plagiarism checker before using it in your machine learning model.
3. Model Selection
After completing the data-centric steps, the next step is to select the model type. These models were developed with different goals. For example, some models are better suited for processing text, while others are better suited for processing images. As for our model, a simple linear regression model works well to distinguish between fruits. In this case, fruit type is the dependent variable, and fruit color and shape are the two predictors or independent variables.
4. Model Training
Training involves passing prepared data to a machine-learning model to find patterns and make predictions. This allows the model to learn from the data and perform a set of tasks. Over time, training improves your model's predictions.
5. Evaluation
After training the model, we need to see how it works. This is done by testing the model's performance using previously unseen data. The hidden data used is the test set that we previously split the data into. If the test is run on the same data that was used to train, the model is already familiar with the data and is finding the same patterns as before, so you won't get the correct measurements. Test data allows you to accurately measure model performance and speed.
6. Parameter Selection
Selection of training-related parameters, also called hyperparameters These parameters control the effectiveness of the training process, and ultimately, model performance depends on them. These are particularly important for the successful creation of machine learning models.
7. Parameter Tuning
If the evaluation is successful, proceed to the hyperparameter tuning step. This step attempts to improve on the positive results obtained in the evaluation step. In this example, we will see if the model can be further improved for recognizing apples and pears. One of them is to revisit the training step and use multiple sweeps of the training data set to train the model.
This can lead to more exposure and better model quality with longer training periods, thus potentially improving accuracy. Another possibility is to refine the initial values given to the model. Random first values are refined over time by trial and error, which often leads to bad results.
However, finding a better initial value or starting the model with a distribution rather than a value may improve the results. There are other parameters that can be used to refine the model, but the process is more intuitive than logical, so there is no specific approach. Of course, if our model achieves that goal, why do we need hyperparameter tuning? This can be answered by looking at the competitiveness of machine learning-based service providers.
Customers have multiple options when looking for a machine-learning model to solve a particular problem. However, you are more likely to be tempted by the one that gives you the most accurate results. For this reason, hyperparameter tuning is a necessary step to ensure the commercial success of machine learning models.
8. Prediction
The ultimate step in the machine learning process is prediction. At this stage, the model is considered ready for use. Our fruit model should be able to answer the question of whether a given fruit is an apple or an orange. The model is independent of human intervention and draws its own conclusions based on the dataset and training. The challenge for models lies in their ability to outperform, or at least outperform, human judgment in a variety of relevant scenarios. The prediction step is what end users see when using a machine learning model in a particular industry.
The move highlights why many see machine learning as the future of various industries. Complex but well-executed machine learning models can improve the decision-making process of their owners. Humans can only process a limited amount of data and relevant factors when making decisions.
Machine learning models, on the other hand, can process and link copious amounts of data. These links supply unique insights into your model that are not revealed by the usual manual approaches. This frees valuable human resources from the burden of processing information and making decisions. By simply using machine learning models as tools, you can make better decisions with much less effort.
Summary
Machine learning is a highly interactive process of learning from experience. The key to machine learning is asking the right questions. Then you need good data to answer the question, and you start iterative testing until you have the model you want. To become a machine learning expert, you need to be trained in all these steps.
To know more such amazing information, stay tuned with us!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
