

Llama 3: Unveiling the Open-Source LLM Powerhouse


Meta recently unveiled Llama 3, their most advanced open-source large language model (LLM) to date.
This new family of models boasts impressive capabilities across various tasks, including creative writing, code generation, and summarizing factual topics.
Llama 3 comes in two sizes: 8 billion and 70 billion parameters, making it suitable for a range of computing powers.
Both sizes offer pre-trained and instruction-tuned versions, allowing for customization towards specific tasks.
Additionally, all models can be run on regular consumer hardware thanks to advancements in quantization techniques.
Llama 3 is more than just an AI model; it’s an invitation to shape the future of AI together .
Table of Content
- What is Llama?
- Meta AI and Llama 3
- Llama 3: Architecture and Training
- Llama's Capabilities and Limitations
- Comparison of Llama 3, GPT-4, and Gemini in a Nutshell
- Benchmarking of Llama 3
- Conclusion
- Frequently Asked Questions
What is Llama?
Llama refers to a family of large language models (LLMs) created by Meta AI, first released in February 2023.
These models are designed to process and generate text, mimicking human-like language capabilities.
These are essentially powerful AI models trained on massive amounts of text data to be informative and comprehensive.
Llama comes in a variety of sizes, with the largest being 65 billion parameters.
Interestingly, the 13 billion parameter version of Llama has been shown to outperform even larger models from other companies, demonstrating that size isn't everything.
Llama is notable for being open-source, meaning researchers and developers can tinker with it and adapt it for new uses.
Here's a breakdown of Llama's key aspects:
Technical Specs
Autoregressive models: Llama uses an approach where the model predicts the next word in a sequence based on the previous ones.
Multiple Sizes: There are several variations, with the first generation offering sizes of 7, 13, 33, and 65 billion parameters.
The latest, Llama 3, comes in 8 billion and 70 billion parameter versions. More parameters generally indicate greater complexity and capability.
Open-Source Focus: Unlike some competitor models, Llama is open-source, allowing researchers and developers to freely access and modify it for various applications.
Meta AI and Llama 3
Meta AI, powered by the cutting-edge Llama 3 technology, stands as one of the world’s leading AI assistants.
Its capabilities extend far beyond mere language understanding. Meta AI empowers users to enhance their intelligence, streamline tasks, create content, and connect with others more effectively.
Whether you’re learning, working, or simply navigating life, Meta AI is your reliable companion.
The model’s versatility is underscored by its availability across multiple platforms, including AWS, Google Cloud, and Microsoft Azure. But that’s not all—Meta AI takes responsibility seriously.
Mark Zuckerberg CEO of Meta mentioned it is also integrating Google and Bing results directly into its AI assistant.
Instead of relying exclusively on training data or a single search engine, Meta's AI assistant intelligently selects and shows results from Google or Bing based on the query.
This integration ensures that users receive a more comprehensive and diverse range of information.
Whether you’re using Meta AI within Facebook, Instagram, WhatsApp, Messenger, or the newly launched Meta.ai desktop experience, you can access these real-time search results without switching platforms.
To learn more about what Mark said about Meta AI, you can check out the video below.
Llama 3: Architecture and Training
Meta's latest offering, Llama 3, pushes the boundaries of large language models (LLMs) with its impressive capabilities and open-source accessibility.
Let's delve into the technical aspects of its architecture and training process.
Architecture: A Foundation in Transformers
Llama 3, like its predecessors, utilizes the Transformer architecture.
This neural network design excels at handling sequential data like text, employing an encoder-decoder structure.
The encoder processes the input sequence, capturing its relationships and context. The decoder leverages this information to generate the output, one word at a time.
Key Architectural Tweaks
Grouped Query Attention (GQA): This innovation improves efficiency by strategically grouping similar elements within the input sequence.
This allows the model to focus on the most relevant parts, reducing computational overhead, particularly in the larger 70-billion parameter model.
Increased Context Length: Compared to Llama 2, Llama 3 doubles the context length to 8K tokens.
This grants the model access to a larger textual window, leading to potentially richer and more nuanced understanding during processing.
Training: A Data Odyssey
Training LLMs like Llama 3 is a complex task, requiring massive datasets and significant computational resources.
Here's a glimpse into Llama 3's training journey:
Massive Dataset: Llama 3 is trained on a dataset exceeding 15 trillion tokens, a significant leap from Llama 2's 2 trillion tokens.
This data consists diverse text formats, including code and multilingual content.
Data Filtering for Quality: Meta employs advanced text classifiers developed from earlier Llama iterations to ensure the training data is high-quality and relevant, minimizing noise and improving training efficiency.
Llama's Capabilities and Limitations
Llama, particularly the latest iteration, Llama 3, boasts a range of impressive features that empower it to tackle various natural language processing (NLP) tasks.
Here's a breakdown of what Llama can do and where it might encounter limitations:
Capabilities
Text Generation: Llama excels at generating different creative text formats, including poems, code, scripts, musical pieces, and email.
Question Answering: It can answer your questions in an informative way, drawing upon its vast knowledge base gleaned from training data.
Summarization: Llama can condense lengthy pieces of text into concise summaries, retaining the key points.
Translation: While not its primary focus, Llama can translate languages, although the accuracy might not be on par with specialized translation models.
Code Completion: For programmers, Llama can assist by auto-completing code or suggesting relevant functions and libraries.
Limitations & Where It Can slip
Factual Accuracy: While trained on a massive dataset, Llama can still generate outputs containing factual errors, especially on specific or niche topics. It's crucial to verify its claims through credible sources.
Bias and Fairness: Large language models like Llama are susceptible to inheriting biases present within their training data. It's essential to be aware of potential biases and exercise caution when interpreting outputs, particularly on sensitive topics.
Common Sense Reasoning: Llama struggles with tasks requiring real-world common sense or understanding social cues within language. Don't expect it to navigate complex social situations or provide nuanced advice.
Open-Ended or Subjective Prompts: Vague or subjective prompts can lead to nonsensical or irrelevant outputs. For optimal results, provide clear and specific instructions.
Comparison of Llama 3, GPT-4, and Gemini in a Nutshell
The Llama 3 shines with its impressive performance, despite being a smaller model compared to the GPT-4.
It excels at logical reasoning and can be run on regular hardware thanks to advancements in efficiency.
However, unlike the closed-source giants GPT-4 and Gemini, Llama 3 is open-source, allowing for customization and fostering a vibrant developer community.
GPT-4 boasts unmatched capabilities, while Gemini leverages Google's vast infrastructure for potential enterprise dominance.
Ultimately, the best choice depends on your needs - open-source flexibility with good performance (Llama 3), cutting-edge capabilities (GPT-4), or enterprise integration with a powerful backing (Gemini).
Benchmarking of Llama 3
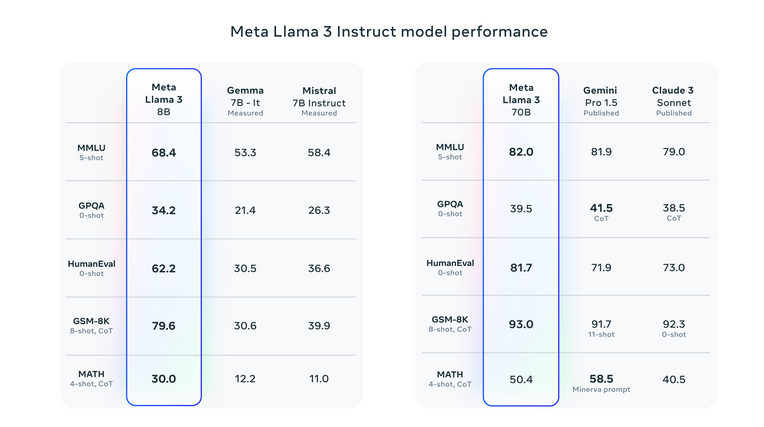
According to Meta, in several benchmarking studies, both versions of Llama 3 outperformed similarly sized models such as Google's Gemma and Gemini, Mistral 7B, and Anthropic's Claude 3.
Llama 3 8B outperformed Gemma 7B and Mistral 7B in the MMLU benchmark, which assesses general knowledge, whereas Llama 3 70B marginally outperformed Gemini Pro 1.5.
Conclusion
The Llama blog has delved into the fascinating world of Llama 3, Meta's latest open-source large language model.
Llama 3's true strength lies in its open-source nature. This fosters a vibrant developer community that continuously pushes the boundaries of the model's capabilities.
With multiple size and specialization options available (base and Instruct versions), users can choose the Llama 3 that best suits their needs.
As research progresses, we can expect Llama 3 to continue evolving, offering even more refined and powerful tools for developers and researchers alike.
Its open-source approach paves the way for a future where advancements in AI are not limited to a select few, but can be readily explored and utilized for the benefit of all.
The possibilities for the future of AI seem brighter than ever with Llama 3 at the forefront.
Frequently Asked Questions
Q1) What is Llama 3?
Llama 3 is an open-source large language model (LLM) developed by Meta AI. It excels at various natural language processing (NLP) tasks, including text generation, question answering, and summarization.
Q2) What are the different versions of Llama 3?
Llama 3 comes in two sizes: 8 billion and 70 billion parameters. Each size has two variations:
Base Model: Pre-trained on a massive dataset for general NLP tasks.
Instruct Model: Fine-tuned specifically for dialogue and chat applications, offering more informative and engaging responses.
Q3) What are the advantages of Llama 3?
- Open-Source: Freely accessible for research and commercial use.
- Strong Performance: Delivers impressive results across various NLP tasks.
- Multiple Sizes and Specializations: Choose the model that best fits your needs and computational resources.
- Accessibility: Runs on regular hardware thanks to advancements in quantization techniques (for the 8 billion parameter versions).

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
