

Life Insurance Risk Assessment Using Machine Learning


Table of Contents
- Introduction
- Machine Learning in Life Insurance Risk Assessment
- Advantages of Using ML in Life Insurance Risk Assessment
- Challenges
- Conclusion
- Frequently Asked Questions
Introduction
Life insurance plays a crucial role in securing the financial well-being of loved ones in the event of an unexpected passing.
However, determining the appropriate premium for each policyholder involves a complex risk assessment process. Traditionally, this process relies on human underwriters who analyze various factors like age, health history, and lifestyle.
While this approach has served its purpose, it can be time-consuming, subjective, and potentially prone to inconsistencies
In recent years, machine learning (ML) techniques has revolutionized the insurance industry, offering new opportunities to enhance the accuracy and efficiency of risk assessment processes.
Machine learning algorithms can analyze vast amounts of data, identify complex patterns, and generate insights to make more informed underwriting decisions.
By leveraging ML, insurers can streamline the underwriting process, reduce costs, and improve risk prediction accuracy, ultimately providing better coverage options for policyholders.
Machine learning in Life Insurance Risk Assessment
Machine learning offers a major shift in life insurance risk assessment by leveraging advanced algorithms to analyze vast amounts of data and uncover intricate patterns.
ML algorithms can process structured and unstructured data, including medical records, lifestyle habits, socio-economic factors, and even social media activity, to generate more accurate risk predictions.
One of the primary advantages of ML is its ability to adapt and learn from new data continuously. Unlike static actuarial models, ML models can evolve over time, refining their predictions based on emerging trends and updated information. This dynamic nature enables insurers to stay ahead of changing risk landscapes and adjust their strategies accordingly.
In this blog, we will be building our own Life Insurance Risk Assessment model using Random Forest classifier. We will be using kaggle dataset to train and test our model.
- Let’s import all the required modules
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns2. Next, we will read our datasets and see the columns present in them.
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
df_train.head()
3. Now Let’s see our target variable ‘Response’ and draw a count plot for it.
sns.countplot(x=df_train['Response'])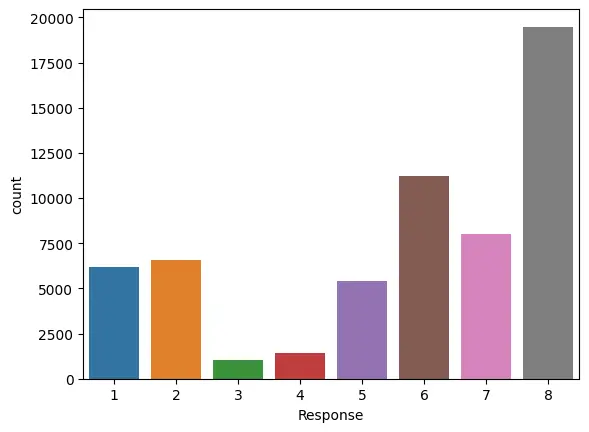
4. Class imbalance can be seen here. Also there 8 categories.
def modify_response(x):
if x <= 7 and x >= 0:
return 0
elif x == 8:
return 1
else:
return -1
df_train['Modified_Response'] = df_train['Response'].apply(modify_response)
sns.countplot(x=df_train['Modified_Response'])
5. Now we will calculate the percentage of Null values present in each column.
missing_val_count_by_column = df_train.isnull().mean()
high_missing_values = missing_val_count_by_column[missing_val_count_by_column > 0.4]
high_missing_values_sorted = high_missing_values.sort_values(ascending=False)
print(high_missing_values_sorted)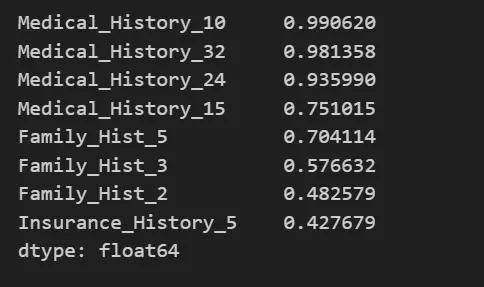
6. We will drop columns where the number of non-null values is less than 40% of the total number of rows in that column.
df_train = df_train.dropna(thresh=df_train.shape[0]*0.4, axis=1)
df_train.drop('Product_Info_2', axis=1, inplace=True)7. Now let’s divide our data. X is the independent variable or features and Y is our target variable. We will also fill rest of the null values with mean.
X = df_train.drop(labels='Modified_Response', axis=1)
Y = df_train['Modified_Response']X = X.fillna(X.mean())8. Now let’s build our model using Random Forest Classifier and print the classification report.
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_auc_score, confusion_matrix
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score,
recall_score, classification_report, confusion_matrix, r2_score
X_train, X_test, Y_train, Y_test = train_test_split(X, Y,test_size = 0.25,
random_state=43)
rf_classifier = RandomForestClassifier(random_state=43)
rf_classifier.fit(X_train, Y_train)
Y_pred = rf_classifier.predict(X_test)
print(classification_report(Y_test, Y_pred))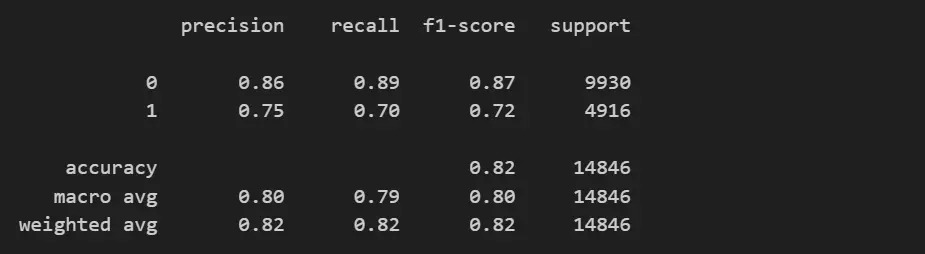
Advantages of using ML in Life Insurance Risk Assessment
Faster and More Efficient
ML algorithms can analyze data and generate risk assessments much quicker than traditional methods, streamlining the application process for customers.
By automating data collection, analysis, and risk assessment, ML models significantly reduce the time required for insures to evaluate applications.
Improved Accuracy
By processing larger and more diverse datasets, ML models can identify subtle patterns and correlations that might be missed by human underwriters, leading to more accurate risk assessments. This leads to more precise pricing of insurance policies, reducing the likelihood of adverse selection and improving the overall profitability of insurance portfolios.
Risk Mitigation
By identifying high-risk individuals more effectively, insurers can implement targeted interventions, such as wellness programs or preventive care initiatives, to mitigate risks and improve overall health outcomes.
Challenges
Data Quality and Privacy
ML models are only as good as the data they are trained on. Ensuring data quality and maintaining privacy and security standards are paramount to the success of ML initiatives in insurance.
Interpretability
The complexity of some ML algorithms, particularly deep learning models, can make them less interpretable. Insurers must balance accuracy with transparency to maintain trust and regulatory compliance.
Regulatory Compliance
ML-based risk assessment must adhere to regulatory guidelines and industry standards to ensure fairness, transparency, and ethical use of data.
Model Robustness
ML models must be robust enough to generalize to unseen data and adapt to changing market dynamics. Ongoing monitoring and model maintenance are essential to mitigate risks associated with model drift and bias.
Conclusion
In conclusion, ML offers immense potential to improve the life insurance risk assessment process. By embracing this technology responsibly, insurance companies can pave the way for a faster, fairer, and more efficient system that benefits both the industry and its customers.
However, realizing the full potential of ML in insurance requires careful consideration of data quality, privacy concerns, regulatory compliance, and model robustness.
Frequently Asked Questions
Q1) What is life insurance risk assessment using machine learning?
Life insurance risk assessment using machine learning involves the use of advanced algorithms and statistical models to analyze various factors and predict the likelihood of an individual's mortality or morbidity.
It helps insurance companies assess the risk associated with insuring a particular individual.
Q2) How does machine learning contribute to life insurance risk assessment?
Machine learning algorithms analyze large volumes of data, including demographic information, medical history, lifestyle factors, and more, to identify patterns and correlations that influence life expectancy and health outcomes.
These insights are then used to predict an individual's risk profile more accurately.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
