

Image Annotation Techniques - A Complete Guide For Training An AI Model
Learn why image annotation and data labeling are essential for AI models. Discover how high-quality datasets improve computer vision accuracy and performance. Find out how outsourcing your data labeling can save time and boost your AI projects.


Many artificial intelligence (AI) products and services that we employ on a daily basis are built around image annotation. Additionally, it is among the most significant activities in the process of creating training data for Computer Vision (CV) technologies.
Annotators utilize tags or metadata to identify the features of data so that an AI model can be trained to recognize images. The next stage is to train the computer to recognize these traits in new, unlabeled data using the labeled and tagged images.
In this blog, we have discussed in detail image annotation, its types, tasks that require Image Annotated data, and why you should choose the only training data platform with a smart feedback loop.
What is Image Annotation?
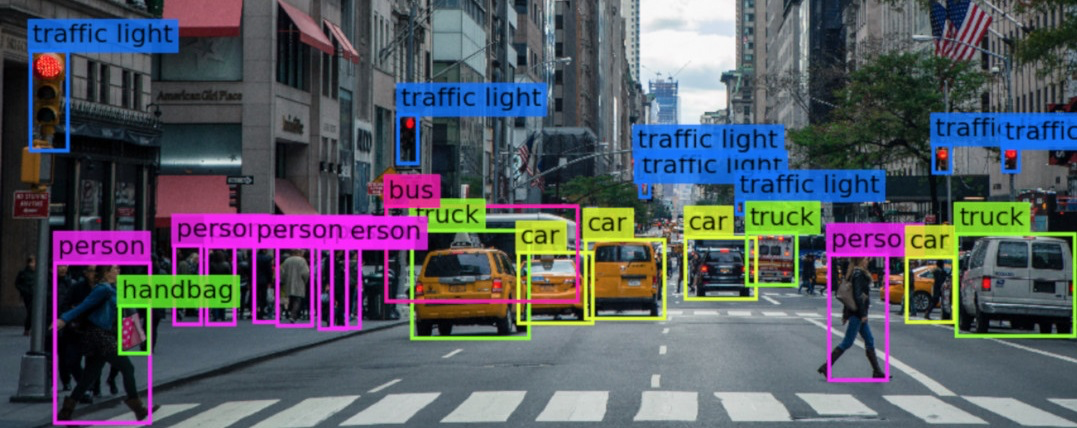
Example of Image Annotation
In order to train machine learning models, images in a dataset are labeled through the process of image annotation.
A machine learning or deep learning model processes tagged images after the manual annotation is finished in order to reproduce the annotations without human oversight.
Any errors in the labels are duplicated as well because image annotation establishes the criteria that the model strives to follow.
As a result, accurate image annotation is one of the most crucial computer vision jobs since it provides the framework for training neural networks. Model-assisted labeling is the term used to describe the practice of model labeling images on its own.
Why do you need annotated images for your AI Model?
The training data for supervised AI models are produced through image annotation. The way users label images predicts how the AI will behave once it has seen and learned from those images. As a result, bad annotation frequently shows up in training, which causes models to make bad predictions.
If we are addressing a novel issue and applying AI to a recently developed field, labeled data is specifically required.
Pre-trained models are frequently available for basic tasks like image segmentation and classification and these can be customized to particular use cases using the technique of Transfer Learning using minimal to no data.
However, creating a large amount of labeled data that is divided into the train, verification, and test sets is challenging and time-consuming when training an entire model from scratch.
On the other hand, unsupervised algorithms can be developed directly on the unprocessed obtained data since they don't need annotated training material.
How much time does Image Annotation require?
The quantity of data needed and the intricacy of the accompanying annotation both affect how long annotations take. It takes less time to process simple annotations with a small number of objects than complex annotations with objects from tens of thousands of classes.
Similar to this, annotations that only need the image to be labeled can be finished considerably more quickly than those that need to pinpoint numerous key points and objects.
Image Annotation Techniques
Manual Image Annotation: The Gold Standard
Manual image annotation is considered the gold standard in the field of image annotation. This approach involves human annotators labeling and describing images, offering a high level of accuracy. This section explores the characteristics and benefits of manual image annotation:
- Accuracy and Precision: Manual image annotation is known for its exceptional accuracy and precision. Human annotators can understand the context of images, leading to highly reliable annotations.
- Complex Tasks: This method is well-suited for complex tasks, such as object recognition, where human expertise is invaluable in distinguishing and labeling intricate details. This can include cases like in Medical domain, where we work at a very microscale and need high precision.
- Quality Control: Manual annotation allows for rigorous quality control. Annotators can review and refine annotations, ensuring that the data is of high quality.
- Subjectivity Handling: Human annotators can handle subjective elements within images, such as interpreting emotions or sentiments, which automated methods may struggle with.
- Challenges: However, manual annotation can be time-consuming and costly, making it less practical for large-scale datasets. It also relies on the expertise and consistency of annotators, which can introduce variability.
Semi-Automatic Annotation Tools and Best Practices
Semi-automatic annotation tools aim to strike a balance between manual and fully automated approaches. They typically involve the use of software and algorithms to assist human annotators in the annotation process. This section explores various aspects of semi-automatic image annotation:
- Workflow Optimization: Semi-automatic tools help streamline the annotation process by automating repetitive or time-consuming tasks, such as object detection or image segmentation.
- Efficiency and Accuracy: These tools can significantly improve annotation efficiency and accuracy, making it easier to handle large datasets. However, they still require human oversight to ensure quality.
- Best Practices: The section discusses best practices for using semi-automatic annotation tools, including guidelines for choosing the right tool, integrating it into the annotation workflow, and maintaining data quality.
Automatic Image Annotation: Pros, Cons, and Tools
Automatic image annotation refers to fully automated methods of adding labels or metadata to images without human intervention. This section examines the advantages and limitations of automatic image annotation:
- Pros: Automatic annotation is highly efficient and can handle large-scale datasets quickly. It's particularly useful for tasks where human annotation would be impractical or cost-prohibitive.
- Cons: Despite its efficiency, automatic annotation may lack the nuance and accuracy of human annotation. It can struggle with complex or ambiguous images, leading to errors.
- Tools: This section introduces various tools and algorithms used for automatic image annotation, including machine learning models, computer vision techniques, and deep learning approaches. Labellerr is one such automatics image annotation tool that help ML teams to mitigate all the risks and create high quality annotations with speed.
Crowdsourcing for Image Annotation: Tips and Pitfalls
Crowdsourcing involves outsourcing the image annotation task to a distributed group of remote workers or "crowd." This section delves into the intricacies of crowdsourcing for image annotation:
- Advantages: Crowdsourcing offers scalability and cost-effectiveness, making it suitable for tasks that require a large number of annotations. It can be used to process vast amounts of data quickly.
- Pitfalls: However, crowdsourcing comes with challenges, such as maintaining annotation consistency, handling quality control, and addressing issues related to worker reliability and expertise.
- Tips: The section provides guidance on how to effectively use crowdsourcing for image annotation, covering topics like task design, worker recruitment, quality assurance, and payment structures.
Types of Image Annotations
Before being utilized as training data for AI applications, images, which are typically referred to as raw datasets, can be displayed in a variety of ways utilizing various data annotation and labeling approaches. Cogito's in-house annotation specialists have unrivaled proficiency in a range of Image annotation techniques, including the following:
1. 2D Bounding Boxes
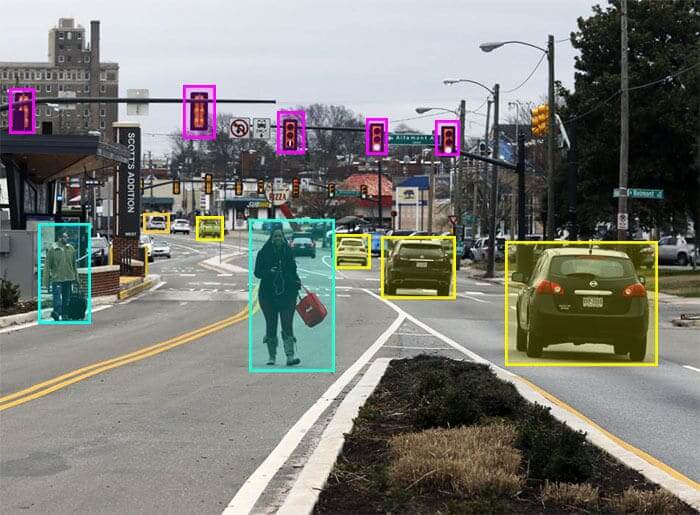
2D bounding boxes make it easier to calculate attributes for models based on computer vision and help with environment recognition in real-world situations.
2. 3D Cuboid Annotation
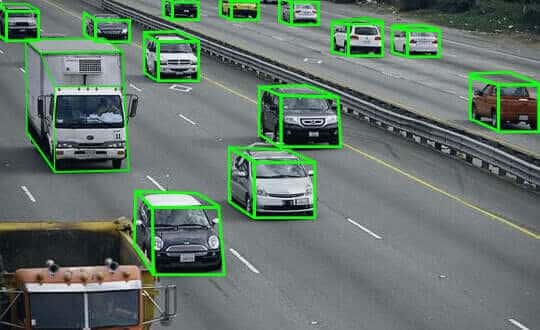
To assist machines in determining the depth of elements like vehicles, people, buildings, etc., cuboid annotation converts 2D visual data into a 3D simulated reality.
3. Key Point Annotation

Dot annotation, often referred to as key point annotation, is the process of joining several dots to identify facial expressions, postures, and emotions.
4. Splines and Lines

The lines and splines annotation technique, which is frequently used for boundary recognition in several industries, entails drawing lines to separate specific areas of photographs.
5. Text Annotation
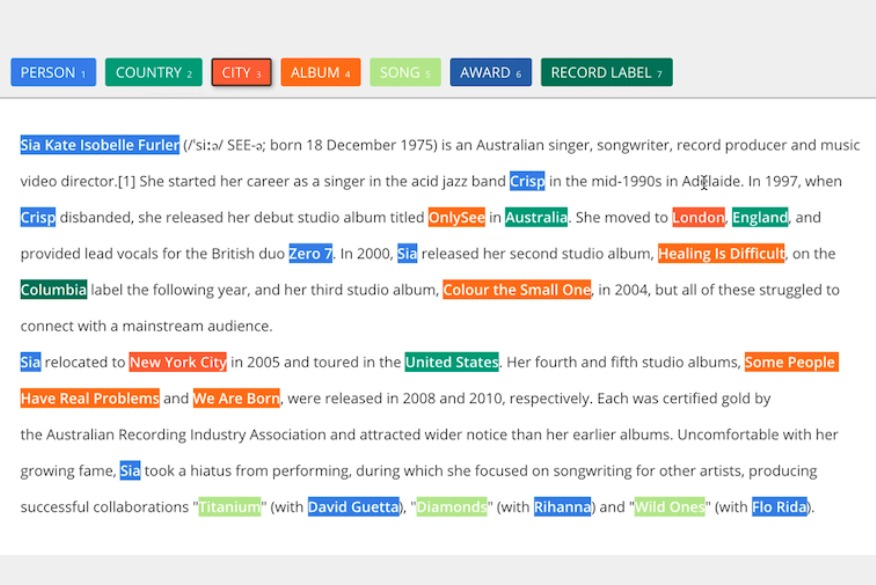
According to numerous criteria based on industrial or commercial usage, labels such as appropriate identities, emotions, and intentions are applied to a text-in-text annotation.
6. Polygon annotation

When precise annotations are required for photos with erratic dimensions and lengths, like traffic and overhead images, polygon annotation techniques are used.
7. Semantic Segmentation

Semantically segmenting an image dataset enables the search for all classes & categories. This makes it possible to accurately recognize and comprehend an image at the pixel level.
8. 3D Point Cloud Annotation
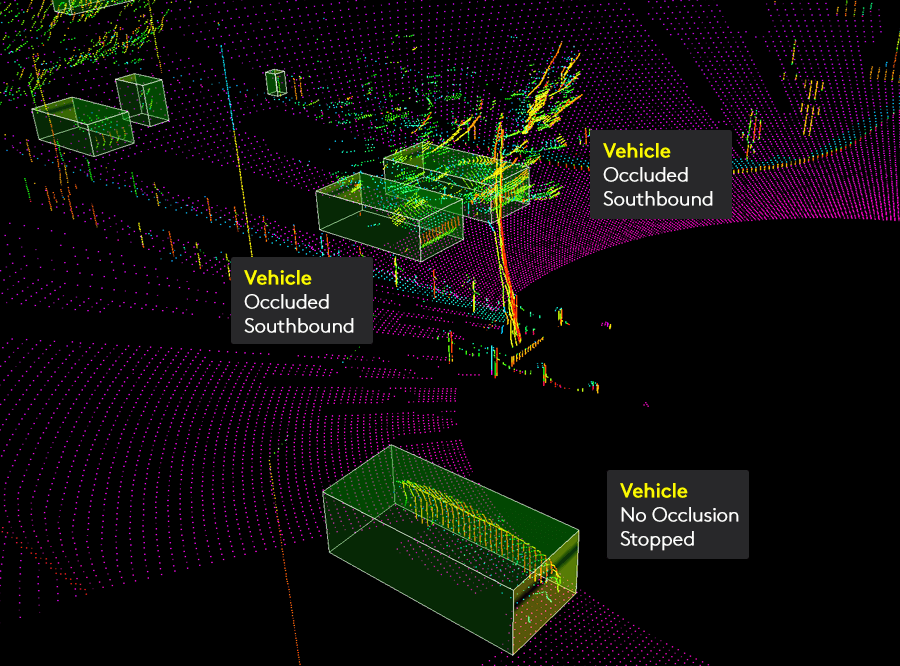
The 3D point cloud annotation method enables visual interpretation of objects to more correctly recognize and categorize them, as well as to better grasp their dimensions.
Computer Vision Tasks that require Annotated Image data
Check out the list of tasks for computer vision that require annotated image data now.
1. Image Classification
A tag or label must be given to an image in order for it to be classified. For Image Classification tasks, supervised deep learning algorithms are typically utilized, and they are trained on images annotated with labels selected from a fixed set of predefined labels.
To annotate an image, one can use basic text labels, classification numbers, or one-hot encodings, which create a zero list of all possible unique IDs and set a specific entry on the list to one based on the class label.
Read here What is an image classification AI model and how to build it?
2. Object detection and recognition
Finding items in an image is the task of object detection, which is also known as object recognition.
The ground truth for these jobs is set using the extreme bounding box coordinates and the class ID, which are used as the annotations in the format of bounding boxes and class identifiers.
The network determines the bounding box coordinates of every object and its matching class labels to do this detection in the form of bounding boxes.
3. Image Segmentation
The process of identifying areas of an image as pertaining to a certain class or label is known as image segmentation.
This can be viewed as a more convenient format of object detection in which we must describe the precise object border and surface rather than only approximate the object's outline in a bounding box.
Object segments from the picture that are projected onto the binary mask are indicated by the relevant class ID, and the remaining region is marked as zero.
These annotations for image segmentation take the form of segment masks or binary masks having the same shape as the image. For algorithms to function successfully, annotations for picture segmentation frequently require the utmost precision.
4. Semantic segmentation
In the process of semantic segmentation, an algorithm attempts to divide a picture into pixel regions according to categories.
For instance, a semantic segmentation algorithm would classify a group of individuals as belonging to the category human, producing a single overlay for each category.
This type of segmentation is frequently referred to as the easiest segmentation task because it does not differentiate between distinct instances or objects belonging to the same category.
5. Instance segmentation
Instance segmentation is a type of segmentation where even the goal is to delineate and divide individual instances of objects from the image. Instance segmentation algorithms search for and separate related objects from groups rather than focusing on the image's categories.
6. Panoptic segmentation
Semantic and instance segmentation are combined in panoptic segmentation, where the algorithm must segment both types of objects while paying close attention to instance-level sections.
By doing this, it is made sure that each category and each instance of the item receive its own segment map. Since the network must regress a significant quantity of data, it goes without saying that this segmentation function is frequently the most challenging of the three.
Why should you select us for annotating your data?
We, at Labellerr, are the only training data platform that offers a smart feedback loop. By putting automation in place, the smart feedback loop will operate on a variety of pre-trained models and ML techniques, reducing the effort put forward by the ML team.
The expense, time, and likelihood of human error will all be decreased thanks to this assistive technology. It provides ML teams enough room to try out more innovative techniques and concepts.
We offer high-quality data for multiple use cases. We use the best practices of data protection and privacy along with IAM (Identity and access management) provided by third-party cloud providers.
If you are interested in getting professional help for your data, then we also offer Highly curated and trained professional annotators at scale. You do not have to worry about the ease of use.
Since we have a highly intuitive user interface with annotation job templates and we provide 24/7 support for your urgent needs as well.
Our platform provides users the power to manage and govern the training data project in a single view. We are currently dealing in providing services to serve these industries:
- Automotive
- Security & Surveillance
- Retail
So, Collect, Curate, and Annotate to boost your Model’s productivity.
If you are interested in getting high-quality image Annotation services, then contact us!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
