

How Nvidia CUDA Empowers Tech Giants to Achieve 10x Faster Model Training


What are Nvidia GPU and CUDA?
Nvidia GPUs are used in almost every laptop and PC to run computations. CUDA refers to (Compute Unified Device Architecture) is a software developed by Nvidia that helps users accelerate the computation power of GPUs using parallel computing.
CUDA is based on C and C++, and it allows us to accelerate GPU and their computing tasks by parallelizing them. This means we can divide a program into smaller tasks that can be executed independently on the GPU. This can significantly improve the performance of the program.
Why CUDA?
At Labellerr, while building the LabelGPT model we've encountered issues without CUDA to tackle the complexities of deploying state-of-the-art models like SAM (Segment Anything Model). These models, while impressive, pose a challenge due to their computational demands.
Running such large models on GPUs without CUDA leads to inefficient memory usage and sluggish performance. But why do we continue to rely on CUDA, even with pre-trained models?
The answer is speed. CUDA accelerates our predictions, delivering outputs swiftly, and meeting our need for rapid execution. Beyond speed, CUDA also offers scalability, effortlessly handling large data volumes for real-time, high-demand tasks.
In essence, our choice to use CUDA depends on the task's demands. For lighter workloads, we may choose a different approach. However, when it comes to production-level performance and real-time output needs, CUDA remains our go-to solution, transforming large models into a seamless, efficient experience.

What is CUDA?
The CUDA programming model is based on the concept of grids, blocks, and threads. A grid is a collection of blocks, and a block is a collection of threads. Each thread has a unique identifier, which determines which data it is executing.
The number of blocks and threads that we use in our program depends on the specific application. We need to carefully examine the application to determine the optimal number of blocks and threads.
To use CUDA, we need to first allocate the GPU memory for our program. We can then write our program using CUDA's parallel computing constructs. These constructs allow us to divide our program into smaller tasks and specify how they should be executed on the GPU.
GRIDs which has BLOCKS which contains THREADS . (Explained in Architecture of CUDA below)
Each thread has a unique identifier that determines what data is executed.
Let's take an example:
Companies worldwide have embraced CUDA in their daily operations, yielding tremendous benefits. For instance, industry leaders such as Tesla and other automotive giants leverage CUDA for training autonomous vehicles. Meanwhile, innovators like Netflix have taken a unique approach, crafting a neural network powered by GPU cores that harness CUDA's capabilities to enhance their recommendation engine.
But what led these Big tech companies to choose CUDA?
Why didn't they opt for traditional methods for training their neural networks?
What would be the processing time difference if CUDA wasn't utilized?
💡 Consider the example of Netflix, specifically in the training of their NRE (Netflix recommendation engine). Initially, it took over 20 hours for the company's engineers to "train" their neural network model. However, through brief optimization of the CUDA kernel, this time was dramatically reduced to a mere 47 minutes. This is precisely why major companies that harness GPUs opt for CUDA to supercharge their applications.

Deep learning Frameworks using CUDA
Many Frameworks which are the building blocks of today’s foundation models also use CUDA and cuDNN (for high-performance GPU acceleration).
Such as PyTorch, TensorFlow, Keras, and MXnet allow these libraries to accelerate the GPU performance.
There are mainly 3 GPU-accelerated libraries:
cuDNN - Used for mostly high-performance deep learning tasks such as training foundation models.
TensorRT - High-performance run time and inference optimizer also helps to calibrate low precision with high accuracy.
DeepStream- High-performance Video inference library.
CUDA Cores
Every NVIDIA graphic card has a certain number of cores that decide the power/processing speed of that GPU. The more the better as when there is a process there are more cores where we can run our process and with parallel computing, the tasks will get processed even faster.
In the case of performance obviously, other factors also come in But we are discussing how the number of cores affects performance
performance of GPU = number of cores * clock frequency * architecture multiplier
The number of cores that we have in our GPU directly affects our performance.
More the number of Cores means more data we can process parallelly.
Why does every Deep Learning engineer use Parallel computing and what is it?
Parallel Computing is a type of processing where the task is Divided or broken into further smaller computations and assigned to a thread to carry out the operation and the results are all combined using synchronized blocks to get the results which we got at least 50x times faster than CPU’s(Depends on the use case)
Embarrassingly parallel: tasks where little or no effort is needed to separate the problem into a number of parallel tasks.
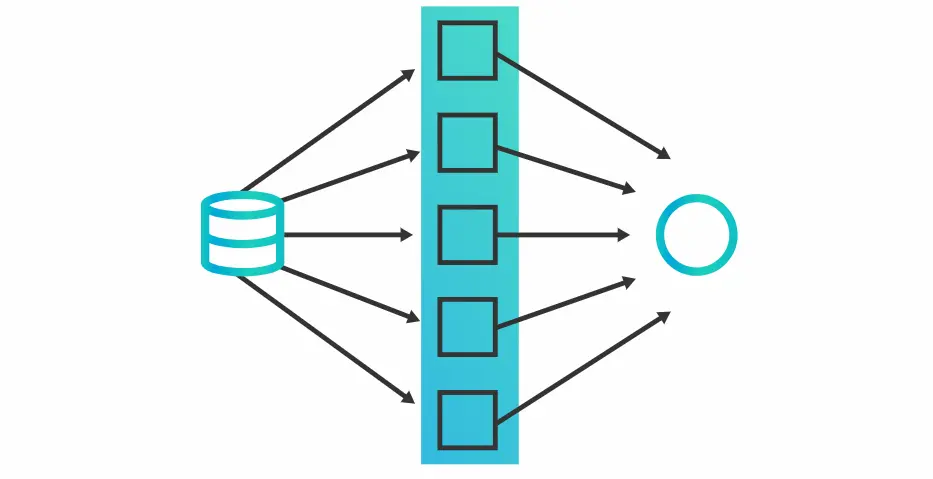
Image source
Why GPU’s are used so much in training neural networks?
Neural Network is also Embarrassingly parallel because computations for each node are generally independent of all other nodes so there will be no extra processing power used to separate the process and we could easily compute the neural networks and allow us to accelerate our task by using GPU’s.
This parallel computing is also used in CUDA explained in CUDA architecture below.
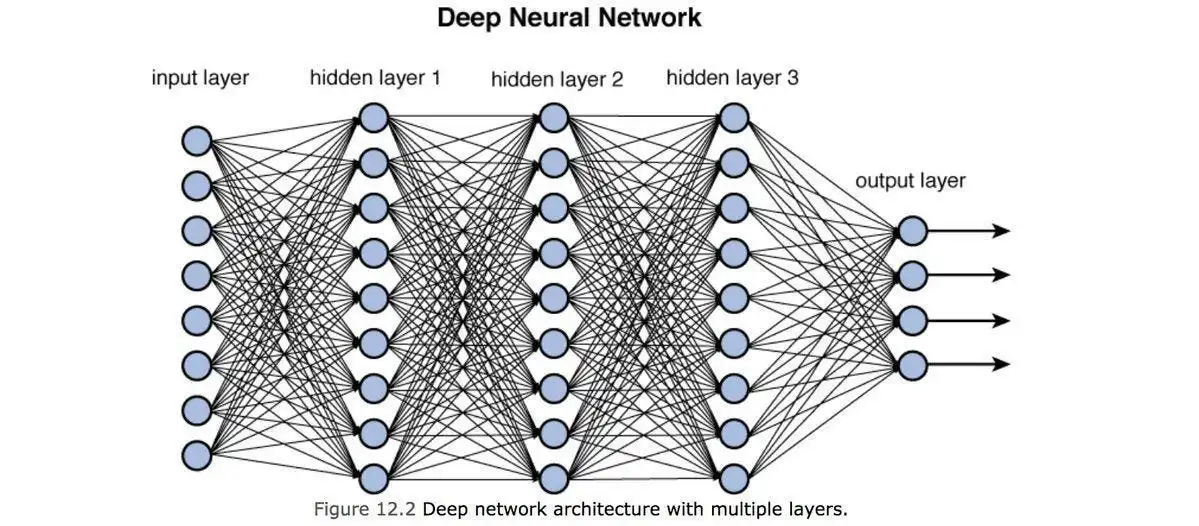
Source(This figure shows how nodes are parallel )
How does Cuda work and its Architecture?
Cuda lets you develop high-performance algorithms accelerated by thousands or lakhs of parallel threads running on GPUs. let's take a deeper dive into it’s architecture.
It basically works on the principle :
parallelism,compute , synchronization
One of the main benefits is CUDA give us it helps us to compute the blocks independently.
First let's understand what is GRID, BLOCK, and Threads.
GRID - It is a list of blocks
Blocks - A group of threads
Threads- The smallest unit of execution that is used to perform calculations
Shared memory - A block of shared memory distributed across threads.
Synchronization Barriers - It Enables multiple threads to wait until all threads have reached a particular point of execution before any thread continues.
💡 In GPU we have GRID of a Block of threads
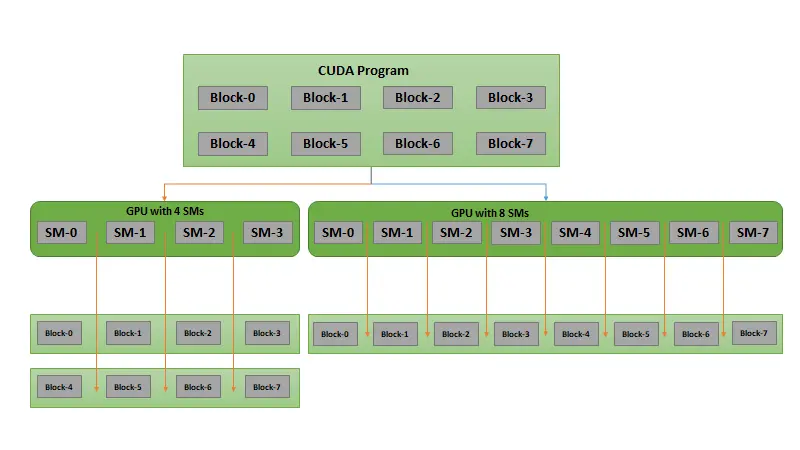
Figure P1
The GPU has a block such as in (Figure P1) which has threads, Thread numbers vary in multiple of 32 per block.
let's suppose we have one block and we want to run 256 threads on it so unlike CPU the GPU will run all of the threads in a block simultaneously and it will accelerate the time we get the output when we run it parallel.
CUDA under the HOOD:
When GPU receives a load through the runtime, it first goes into a GRID(group of blocks) in Figure P1 the program goes in 8 blocks named B0, B1, B2……. ,B7 during runtime these are allocated to SMs(Streaming multiprocessors) .
Then streaming multiprocessor distributes the blocks each block is assigned to a smaller problem, according to the need after the distributing of the block is done the block is assigned to the thread's task which is then processed by threads then when the task is done the synchronization barriers enables multiple threads to sync and converge at some point of the process completion.

What is NVIDIA cuDNN?
CUDA Deep Neural Networks, a GPU-accelerated library, revolutionizes the world of deep learning frameworks. Compatible with PyTorch, TensorFlow, MxNet, Caffe2, and more, it stands as a cornerstone for enhancing the performance of these frameworks.
This library boasts finely tuned implementations of essential operations, including forward and backward convolutions, pooling, normalization, and activation layers. Its true prowess shines through its ability to execute fast matrix multiplication (GEMM) while conserving precious memory resources, a feat that traditional methods struggle to achieve.
How cuDNN is helping in Foundational models?
cuDNN, the driving force behind this GPU acceleration, operates on the premise that GPU-based data is at its fingertips. Its API also extends its capabilities to host-based operations.
The significance of CUDA and cuDNN becomes evident when we consider the impact on the performance of cutting-edge models. State-of-the-art models like LabelGPT and SAM (Segment Anything Model), as well as large language and computer vision models, heavily rely on cuDNN for GPU acceleration. Without this dynamic duo, these models would not be able to train efficiently or perform at their best.
Moreover, cuDNN introduces caching mechanisms, establishing shared memory to optimize thread-based data storage and retrieval during GPU operations. This strategic approach elevates performance and fosters seamless data sharing among threads.
In essence, CUDA and cuDNN are the catalysts propelling the next generation of deep learning models, unlocking unprecedented levels of performance and efficiency across a spectrum of applications.

SAM(segment anything model) that we used in LabelGPT remarkable model seamlessly transformed a picture containing two dogs into a finely detailed segmented image of just one dog, Demonstrating how CUDA is helping to build what types of model just makes our life easier and helping in these advance kind of researches.
Conclusion:
"In summary, Nvidia GPUs combined with CUDA technology have revolutionized AI and deep learning. Their parallel computing capabilities and abundant CUDA cores enable swift and efficient processing, making them ideal for neural networks.
CuDNN, another vital component, optimizes operations and boosts performance for foundational models like LabelGPT and SAM. This dynamic duo is driving the future of deep learning, making breakthroughs in AI research and applications possible.
As AI continues to advance, Nvidia's CUDA and cuDNN will remain crucial, driving innovation and simplifying complex tasks. Thank you for exploring the world of AI acceleration with us!"
For more Blog like these explore: Blog section

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
