

A Hands-On Guide to Meta's Llama 3.2 Vision
Explore Meta’s Llama 3.2 Vision in this hands-on guide. Learn how to use its multimodal image-text capabilities, deploy the model via AWS or locally, and apply it to real-world use cases like OCR, VQA, and visual reasoning across industries.

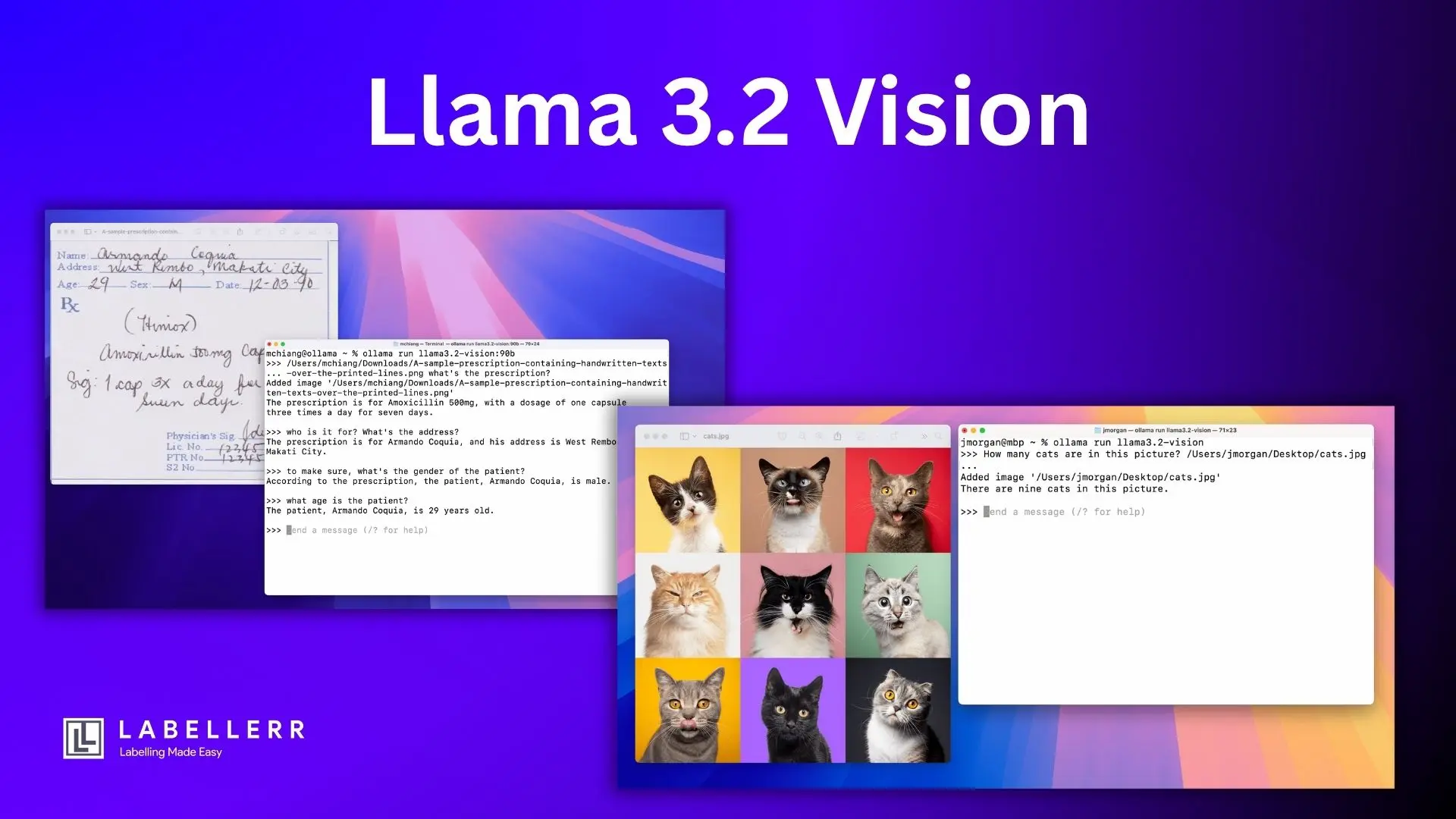
Artificial Intelligence (AI) now masters text, but to truly grasp our world, it must also see. Adding vision to powerful language models like Meta's Llama series is challenging. Building multimodal AI (text + images) from scratch often leads to technical hurdles like instability or scaling issues.
Meta's Llama 3.2 Vision tackles this differently. It builds on the strong Llama 3.1 text model by adding a specialized "vision adapter." This adapter, trained to understand images, feeds visual information into the language model, enabling it to "see" without a complete redesign. For those interested in fine-tuning Llama 3.2 Vision for specific tasks, there are specialized approaches available.
This article provides a hands-on guide to using the Llama 3.2 Vision 11B model through Ollama. We'll cover setup, code, explore its capabilities with examples, and discuss its strengths and limitations. Ollama simplifies running powerful AI like this on your own computer, giving you control and offline capabilities.
Key Technical Features
- Multimodal AI: Processes images and text to generate text responses.
- 11B Parameters: A powerful yet manageable size for local use, compared to its 90B sibling. Parameters are internal values the AI uses to "think."
- Architecture: Based on the Llama 3.1 text transformer, augmented with a vision adapter (image encoder + cross-attention layers).
- Training: Trained on 6 billion image-text pairs; knowledge current up to December 2023.
- Context Window: Handles up to 128,000 tokens (words/parts of words), allowing for rich prompts.
- Core Capabilities (11B): Image understanding, captioning, Visual Question Answering (VQA), basic document element identification.
- Image Support: Works with GIF, JPEG, PNG, WEBP formats, up to 1120x1120 pixels (larger images are scaled down).
- Output Length: Generates up to 2048 tokens.
Setup: Llama 3.2 Vision 11B with Ollama
Prerequisites:
Python installed.
- Ollama installed (from ollama.com for macOS, Windows, Linux).
- Sufficient RAM and VRAM (Ollama notes at least 8GB VRAM for Llama 3.2 Vision 11B).
Download Model via Ollama:
Open your terminal and run:
# Download the Llama 3.2 Vision 11B model using Ollama
ollama pull llama3.2-vision:11b
Verify with ollama list.
Install Python Libraries:
# Install the required python libraries using pip
pip install ollama requests Pillow
(Pillow is for creating a test image if needed).
How to do inference on Llama 3.2 Vision Model?
This script demonstrates loading images and performing inference.
Image Loading Function:
import requests import ollama def load_image(image_path_or_url): """Load image bytes from a local path or URL.""" if image_path_or_url.startswith('http://') or image_path_or_url.startswith('https://'): print(f"Downloading image from: {image_path_or_url}") response = requests.get(image_path_or_url) response.raise_for_status() # Ensure download was successful return response.content else: print(f"Loading image from local path: {image_path_or_url}") with open(image_path_or_url, 'rb') as f: return f.read()
This function fetches image data as bytes, either from a URL or a local file.
Vision Inference Function:
def vision_inference(prompt, image_path_or_url, model='llama3.2-vision:11b'): try: image_bytes = load_image(image_path_or_url) print(f"\nSending prompt to Llama 3.2 Vision ({model}): '{prompt}'") response = ollama.chat( model=model, messages=[ { 'role': 'user', 'content': prompt, 'images': [image_bytes], # Image bytes are passed here } ] ) if 'message' in response and 'content' in response['message']: print(f"\nLLaMA 3.2 Vision Says:\n{response['message']['content']}") else: print(f"Unexpected response format from Ollama: {response}") except Exception as e: print(f"An error occurred: {e}")
The vision_inference function sends the prompt and image bytes to the Llama model via ollama.chat() and prints the AI's text output.
Example Usage:
Save the above functions into a Python file (e.g., run_llama_vision.py).
if __name__ == "__main__": print("--- Example 1: Describing a Local Image ---") local_image_path = "example_scene.jpg" # Replace with your image path try: # Create a dummy image if 'example_scene.jpg' doesn't exist for testing from PIL import Image as PImage try: PImage.open(local_image_path) except FileNotFoundError: img = PImage.new('RGB', (600, 400), color = 'red'); img.save(local_image_path) print(f"Created dummy '{local_image_path}'. Replace with your own image for meaningful results.") vision_inference( prompt="Describe this image in detail. What are the main objects and activities?", image_path_or_url=local_image_path ) except Exception as e: print(f"Error with local image: {e}. Ensure '{local_image_path}' exists.") print("\n--- Example 2: Analyzing a URL Image ---") url_image_path = "https://acko-cms.ackoassets.com/fancy_number_plate_bfbc501f34.jpg&cs=tinysrgb&w=1260&h=750&dpr=1"
# Example Car Number Plate image vision_inference( prompt="What is the make and color of the car in this image? Describe its surroundings.", image_path_or_url=url_image_path )
Llama 3.2 Vision 11B: Practical Uses with Ollama
Here are some things you can do with your local Llama 3.2 Vision 11B:
A. Image Captioning:
Automatically create alt text for web images or describe products
# vision_inference("Write a short, descriptive caption for this product image.", "product_image.png")
image-captioning-llama-3-2
B. Visual Question Answering (VQA):
Ask questions about objects or scenes in your personal photos.
# vision_inference("What color is the cat sitting on the sofa in this picture?", "living_room_cat.jpg")

vqa-llama-3-2
C. Basic Document Element ID:
Identify if a document image contains a chart or logo (the 11B model might struggle with complex OCR).
# vision_inference("Does this document page contain a logo in the top-right corner?", "document_scan.jpg")
document-understading-llama
D. Creative Inspiration:
Generate story ideas or descriptive text based on an image.
# vision_inference("Write a mysterious story intro based on this foggy landscape image.", "foggy_landscape.jpeg")

creative-thinking-llama
Strengths & Weaknesses
Strengths:
- Accessible: Ollama simplifies running a powerful 11B vision model locally.
- Open Source: Benefits from community input and allows offline, private processing.
- Good General VQA & Captioning: Handles common image understanding tasks well.
- Decent Context Window: Processes reasonably long prompts.
Limitations:
- Resource Needs: Requires good RAM/VRAM (at least 8GB VRAM).
- Slower Inference: Generally slower than cloud AI services.
- Complex Visual Tasks: The 11B model may not match larger or top-tier closed models on very nuanced visual reasoning, fine-grained OCR, or extremely challenging object detection.
- Mathematical/Logical Reasoning with Visuals: Room for improvement.
- Knowledge Cutoff: December 2023.
- Safety Over-Correction: Can sometimes be overly cautious.
The Future for Llama Vision
Expect ongoing improvements from Meta and the community, better accessibility for larger models locally, broader language support, and wider integration into developer tools. Open source models like this drive innovation.
Conclusion
Llama 3.2 Vision 11B, run via Ollama, offers an exciting way to bring AI that understands text and images to your local machine. It's a powerful tool for image description, visual Q&A, and basic document understanding.
Try the code, experiment with your images, and explore the possibilities of local, open-source vision AI! While it has limits, Llama 3.2 Vision 11B shows how fast open multimodal AI is progressing.
References
FAQs
Q1: Who should use Llama 3.2 Vision?
A: Developers, researchers, and data scientists seeking to build image captioning, OCR, VQA, or multimodal search tools can benefit from using Llama 3.2 Vision.
Q2: How do I start using Llama 3.2 Vision?
A: You can begin by accessing the model via Amazon Bedrock or SageMaker JumpStart, or run it locally with tools like Ollama. Integration guides are available in official documentation.
Q3: What are some hands-on use cases demonstrated in this guide?
A: Use cases include generating captions from medical images, extracting text from scanned documents, answering questions about charts, and automating report generation.
Q4: What libraries or tools are recommended in this guide?
A: The guide demonstrates using Llama 3.2 Vision with PyTorch, Hugging Face Transformers, Ollama CLI, and AWS services for scalable deployment.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
