

GLM-4.5 by Zhipu AI: Model for Coding, Reasoning, and Vision
GLM-4.5 delivers state-of-the-art open-source capabilities across language, code, and multimodal vision. Combining a 355B-parameter Mixture-of-Experts architecture, dual-mode reasoning, and native tool use, it sets new standards for coding, agentic, and multilingual tasks.


Imagine an AI that can not only write code for a new app but also design its user interface from a sketch, analyze user feedback from a video, and reason about market trends from a dense report.
This isn't science fiction; it's the unified intelligence that developers have been striving for. For years, the AI landscape has been fragmented, with specialized models that excel at one task but fail at others.
This creates a bottleneck for building truly intelligent, autonomous agents.
Now, Zhipu AI (Z.ai) is breaking down these silos. They have released the GLM-4.5 family, a powerful set of open-source models designed to unify reasoning, coding, and vision into a single, cohesive intelligence.
Introducing the GLM-4.5 Family
GLM 4.5
Z.ai has open-sourced the GLM-4.5 series under the permissive MIT license, allowing anyone to use it for commercial and secondary development—a massive contribution to the open-source community. The family includes two core models:
- GLM-4.5: The flagship model, built with 355 billion total parameters and 32 billion active parameters, designed for maximum performance.z
- GLM-4.5-Air: A more compact and efficient version with 106 billion total parameters and 12 billion active parameters, offering competitive performance with lower resource requirements.z
At the heart of these models is a core innovation: the "thinking mode". This allows the models to dynamically switch between a fast, immediate response for simple queries and a slower, more deliberate reasoning process for complex tasks.
The Architecture of GLM-4.5
GLM-4.5 isn't a monolithic giant. It uses a Mixture-of-Experts (MoE) architecture, where only a fraction of its total parameters (the "active" ones) are used for any given task. This makes it incredibly efficient without sacrificing power.
When a user enables "thinking mode," the model engages in a form of Chain-of-Thought reasoning. It explicitly breaks down a problem, uses tools, and shows its work before providing a final answer. This dramatically improves accuracy on complex tasks and makes the model's reasoning process transparent.
Designed for intelligent agents, the models can natively use tools in an OpenAI-style format. Key components like the reasoning_parser and tool_call_parser allow them to automatically choose the right tool for the job. On industry benchmarks, GLM-4.5 achieves a score of 63.2, placing it third among all models, while GLM-4.5-Air scores a competitive 59.8.
There is yet Another Model: GLM-4.5V
GLM 4.5v
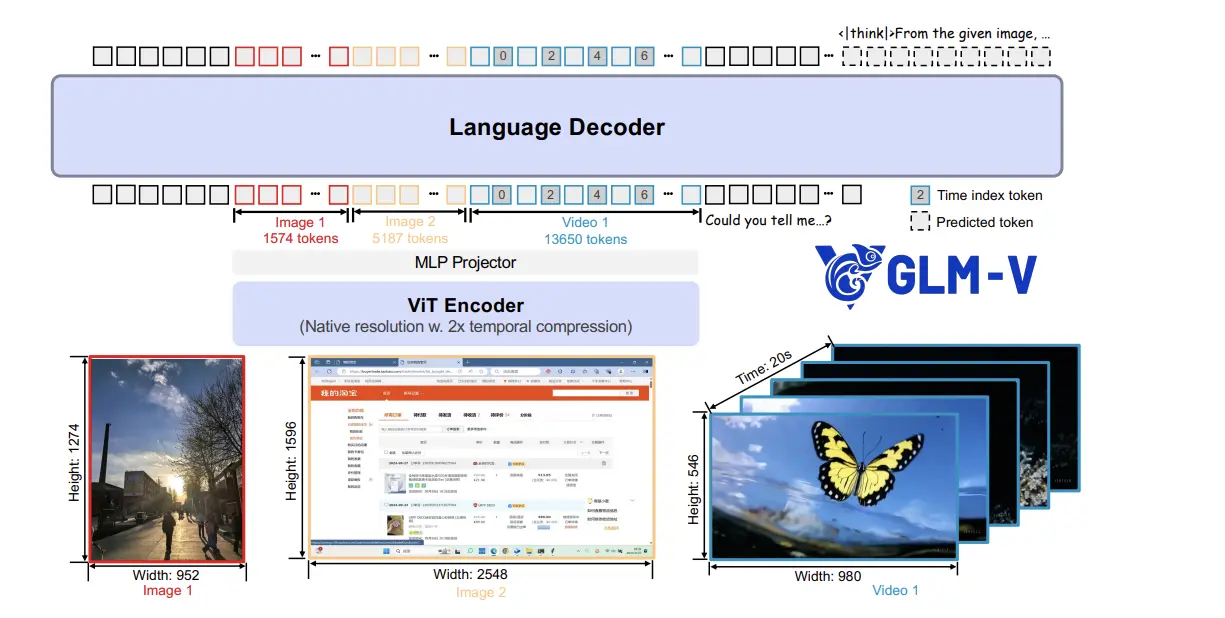
Building on the efficient GLM-4.5-Air architecture, GLM-4.5V is the vision-language model (VLM) of the family. It inherits the powerful reasoning capabilities of its sibling and adds a sophisticated vision system, making it one of the top-performing open-source VLMs available.
GLM-4.5V's ability to "see" is more than just describing an image; it's about deep comprehension. Its key vision capabilities include:
- Advanced Image and Video Reasoning: It can understand complex scenes, analyze multiple images at once, and recognize events in long videos.
- GUI Agent Tasks: It can read a computer screen, identify icons, and assist with desktop operations, making it perfect for automation.
- Document and Chart Parsing: It can analyze research reports and extract precise information from complex charts.
- Precise Grounding: It can accurately identify the location of specific objects within an image or video, providing bounding box coordinates.
To achieve this, GLM-4.5V uses technical innovations like 3D Rotated Positional Encoding (3D-RoPE) to better understand 3D spatial relationships.
Running the Models: A Complete Guide for Developers
These powerful models come with demanding hardware requirements, but understanding exactly what you need and how to optimize your setup can make the difference between a successful deployment and endless frustration. Here's everything you need to know to run GLM-4.5 and GLM-4.5-Air locally.
Hardware Requirements:
GLM-4.5 Full Model:
- FP8 Precision (Recommended): 8x H100 (80GB) or 4x H200 (141GB)
- BF16 Precision: 16x H100 (80GB) or 8x H200 (141GB)
- For Full 128K Context: 16x H100 or 8x H200 in FP8
- System RAM: Minimum 1TB to handle model loading and memory buffers
- VRAM Usage: ~945GB in FP16 for batch size 1, scaling up to 1.7TB for larger batches
GLM-4.5-Air (Efficient Variant):
- FP8 Precision: 2x H100 (80GB) or 1x H200 (141GB)
- BF16 Precision: 4x H100 (80GB) or 2x H200 (141GB)
- For Full 128K Context: 4x H100 or 2x H200 in FP8
- VRAM Usage: ~289GB in FP16 for batch size 1, scaling up to 532GB for larger batches
Fine-tuning Hardware Requirements
Using LoRA (Low-Rank Adaptation):
- GLM-4.5: 16x H100 GPUs with batch size 1 per GPU
- GLM-4.5-Air: 4x H100 GPUs with batch size 1 per GPU
Using Full Fine-tuning:
- GLM-4.5: 128x H20 (96GB) GPUs for SFT/RL training
- GLM-4.5-Air: 32x H20 (96GB) GPUs for SFT/RL training
Memory Optimization Strategies
CPU Offloading for Smaller Setups
When you don't have the full recommended GPU setup, you can use CPU offloading, though this comes with significant performance penalties:
--cpu-offload-gb 16
Quantization Options
- FP8: Reduces memory by ~50% compared to BF16, requires H100/H200 GPUs
- INT4: Further reduction possible with custom implementations
- Mixed Precision: Automatic optimization based on operation requirements
Installation and Environment Setup
System Prerequisites
# Update system and install CUDA 12.4+ sudo apt update && sudo apt upgrade -y sudo apt install nvidia-driver-560 nvidia-cuda-toolkit # Verify CUDA installation nvidia-smi nvcc --version
Python Environment Setup
# Create dedicated environment conda create -n glm45 python=3.10 conda activate glm45 # Clone the official repository git clone https://github.com/zai-org/GLM-4.5 cd GLM-4.5 # Install requirements pip install -r requirements.txt # Install additional dependencies for inference frameworks pip install vllm sglang pip install flash-attn --no-build-isolation
Inference Frameworks: Complete Implementation Guide
1. vLLM Deployment
Basic Server Setup:
vllm serve zai-org/GLM-4.5-Air \
--tensor-parallel-size 2 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--served-model-name glm-4.5-air \
--dtype auto \
--max-model-len 128000 \
--gpu-memory-utilization 0.95
vllm serve zai-org/GLM-4.5 \
--tensor-parallel-size 8 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--served-model-name glm-4.5 \
--dtype auto \
--cpu-offload-gb 16 \
--max-model-len 64000 # Reduced for memory constraints
- Use
--cpu-offload-gb 16to offload 16GB to CPU memory if GPU memory is insufficient. --max-model-lencontrols the max sequence length to save memory.- Adjust
--tensor-parallel-sizeaccording to your GPU count and size for efficient inference.
Advanced vLLM Configuration:
VLLM_ATTENTION_BACKEND=XFORMERS vllm serve zai-org/GLM-4.5-Air \
--tensor-parallel-size 2 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--quantization fp8 \
--kv-cache-dtype fp8 \
--max-num-seqs 32 \
--max-num-batched-tokens 8192 \
--served-model-name glm-4.5-air-optimized
VLLM_ATTENTION_BACKEND=XFORMERSenables optimized attention operations for better speed.--quantization fp8and--kv-cache-dtype fp8activate 8-bit floating point quantization for reduced memory and faster inference.--max-num-seqsand--max-num-batched-tokensmanage batching for throughput optimization.- Adjust parameters based on your hardware for best performance.
2. SGLang Deployment
FP8 Configuration (Recommended):
python3 -m sglang.launch_server \
--model-path zai-org/GLM-4.5-Air-FP8 \
--tp-size 2 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--mem-fraction-static 0.7 \
--disable-shared-experts-fusion \
--served-model-name glm-4.5-air-fp8 \
--host 0.0.0.0 \
--port 8000
- The
EAGLEalgorithm enables speculative decoding for faster and more efficient inference. --speculative-num-steps,--speculative-eagle-topk, and--speculative-num-draft-tokenscontrol decoding strategy parameters.- Adjust
--tp-sizebased on your available GPUs and model size. --mem-fraction-staticmanages static memory fraction allocation.--disable-shared-experts-fusioncan optimize model expert fusion behavior.
BF16 Configuration:
python3 -m sglang.launch_server \
--model-path zai-org/GLM-4.5 \
--tp-size 8 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--mem-fraction-static 0.6 \
--served-model-name glm-4.5 \
--host 0.0.0.0 \
--port 8000
- The
EAGLEalgorithm enhances decoding speed and efficiency through speculative multitoken generation. - Adjust
--tp-sizefor your GPU configuration for optimized parallelism. --mem-fraction-staticcontrols static memory reservation for stable inference.- Ensure your hardware supports BF16 precision for optimal performance.
3. Transformers Direct Implementation
Basic Usage Script:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Load model and tokenizer
model_name = "zai-org/GLM-4.5-Air"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
# Generate response function
def generate_response(prompt, enable_thinking=True):
if enable_thinking:
formatted_prompt = f"<thinking>\n{prompt}\n</thinking>"
else:
formatted_prompt = prompt
inputs = tokenizer(formatted_prompt, return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=1024,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[inputs['input_ids'].shape[1]:], skip_special_tokens=True)
return response
# Example usage
prompt = "Explain the concept of quantum computing in simple terms."
response = generate_response(prompt, enable_thinking=True)
print(response)
Making API Requests: Complete Examples
Basic API Request with Thinking Mode
import requests
import json
def call_glm45_api(prompt, enable_thinking=True, base_url="http://localhost:8000"):
headers = {
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.5-air",
"messages": [
{"role": "user", "content": prompt}
],
"max_tokens": 1024,
"temperature": 0.7,
"extra_body": {
"chat_template_kwargs": {
"enable_thinking": enable_thinking
}
}
}
response = requests.post(f"{base_url}/v1/chat/completions",
headers=headers,
data=json.dumps(payload))
return response.json()
# Example usage
response = call_glm45_api("Write a Python function to calculate fibonacci numbers", enable_thinking=True)
print(response['choices']['message']['content'])
Advanced API Request with Tool Calling
import requests
import json
def call_with_tools(prompt, tools=None):
payload = {
"model": "glm-4.5-air",
"messages": [
{"role": "user", "content": prompt}
],
"tools": tools or [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather information",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City name"
}
},
"required": ["location"]
}
}
}
],
"tool_choice": "auto",
"max_tokens": 1024,
"extra_body": {
"chat_template_kwargs": {
"enable_thinking": True
}
}
}
response = requests.post("http://localhost:8000/v1/chat/completions",
headers={"Content-Type": "application/json"},
data=json.dumps(payload))
return response.json()
# Example usage
response = call_with_tools("What's the weather like in Tokyo?")
print(response)
Performance Monitoring and Optimization
GPU Memory Monitoring
watch -n 1 nvidia-smi
# Log GPU metrics every 1 second to gpu_usage.log
nvidia-smi --query-gpu=timestamp,memory.used,memory.free,utilization.gpu \
--format=csv -l 1 > gpu_usage.log
watch -n 1 nvidia-smirunsnvidia-smievery second to display live GPU status.nvidia-smi --query-gpu=...logs timestamp, used/free memory, and GPU utilization every second to a CSV file.- Useful for real-time monitoring and persistent logging of GPU performance metrics.
Performance Benchmarking Script
import time
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
def benchmark_model(model_name, prompts, num_runs=10):
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
total_time = 0
total_tokens = 0
for _ in range(num_runs):
for prompt in prompts:
start_time = time.time()
inputs = tokenizer(prompt, return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=256,
do_sample=False,
pad_token_id=tokenizer.eos_token_id
)
end_time = time.time()
# Calculate metrics
generated_tokens = outputs.shape[1] - inputs['input_ids'].shape[1]
total_time += (end_time - start_time)
total_tokens += generated_tokens
avg_tokens_per_second = total_tokens / total_time
print(f"Average tokens per second: {avg_tokens_per_second:.2f}")
print(f"Average latency per token: {total_time/total_tokens*1000:.2f}ms")
# Run benchmark
test_prompts = [
"Explain machine learning",
"Write a sorting algorithm",
"Describe the solar system"
]
benchmark_model("zai-org/GLM-4.5-Air", test_prompts)
Troubleshooting Common Issues
Memory Issues
# If CUDA out of memory error occurs: export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128 # For flash attention compile errors: export TORCH_CUDA_ARCH_LIST='9.0+PTX' # Adjust according to your GPU architecture
- Use
PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128to reduce GPU memory fragmentation. - Set
TORCH_CUDA_ARCH_LISTbased on your GPU compute capability to avoid flash attention compile issues. - Set these environment variables before running your PyTorch or deep learning scripts.
Performance Optimization Tips
- Use FP8 when possible: Reduces memory usage by ~50%
- Enable speculative decoding: Can improve inference speed by 2-3x
- Optimize batch sizes: Start with batch size 1 and increase gradually
- Monitor temperature settings: Lower values (0.1-0.3) for deterministic outputs
- Use tensor parallelism: Distribute model across multiple GPUs efficiently
This comprehensive guide provides everything you need to successfully deploy and run GLM-4.5 models, from basic setups to production-scale deployments with full optimization.
The Open-Source Impact: What This Means for the AI Community
By open-sourcing the GLM-4.5 family under the MIT license, Z.ai has democratized access to top-tier AI. Startups, researchers, and individual developers can now build applications that were previously only possible with expensive, proprietary models.
GLM-4.5 has set a new benchmark for open-source AI, challenging the dominance of closed models and pushing the entire field forward.
More than just another language model, the GLM-4.5 family is a toolkit for building the next generation of intelligent, autonomous agents that can reason, code, see, and act in our world.
This release is an invitation for the entire community to join in and build that future together.
FAQs
What is GLM-4.5?
GLM-4.5 is an open-source large language model by Zhipu AI, designed to unify advanced reasoning, coding, agentic abilities, and vision in a single powerful framework.
What are GLM-4.5's core capabilities?
It features dual “thinking” and “non-thinking” modes for efficiency, supports 128K context, function calling, web browsing, coding, vision, and offers robust multilingual performance.
Is GLM-4.5 free and open source?
Yes, GLM-4.5 is MIT-licensed, allowing self-hosting, custom training, and commercial use without restrictions.
How does GLM-4.5 compare to other models?
On industry benchmarks, GLM-4.5 ranks third globally, excelling at code, reasoning, and agentic benchmarks compared to leading closed and open models.
Where can GLM-4.5 be accessed?
Model weights, code, and APIs are available on Hugging Face and ModelScope, with quick-start guides for local or cloud deployment.
References

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
