

Detecting Alzheimer's Disease with Deep Learning: A Step-by-Step Guide


Table of Contents
- Introduction
- About Dataset
- Hands-on Tutorial
- Uses of Alzheimer's Disease Detection in Healthcare
- Conclusion
- Frequently Asked Questions
Introduction
The emergence of artificial intelligence (AI) and machine learning (ML) technologies in the field of healthcare has heralded promising advancements in Alzheimer's disease detection. This groundbreaking dataset on Alzheimer's comprises meticulously collected MRI images categorized into four distinct classes, delineating various stages of the disease. It aims to catalyze the development of accurate predictive models capable of discerning and classifying different Alzheimer's stages which is very useful for ML Experts, ML Beginners, and Product Managers.
Leveraging state-of-the-art techniques, this dataset provides a valuable resource for researchers and data scientists to craft intricate algorithms designed for precise classification based on MRI images. The profound importance of this dataset lies in its potential to transform the landscape of early diagnosis and treatment of Alzheimer's disease, holding significant value for both scientific and medical communities.
About Dataset
This dataset on Alzheimer's disease consists of MRI images that have been manually collected and verified, containing four classes across both training and testing sets. These classes are:
- Mild Demented
- Moderate Demented
- Non-Demented
- Very Mild Demented
Contextually, Alzheimer's disease is a neurodegenerative disorder characterized by cognitive decline and memory loss. The dataset provides images depicting various stages of the disease, aiming to facilitate the development of highly accurate predictive models for identifying different stages of Alzheimer's.
Key points about the dataset:
Data Collection: The data has been collected manually from various sources, ensuring that each image is accurately labeled with one of the four specified classes.
MRI Images: The dataset consists of MRI (Magnetic Resonance Imaging) images. MRI is a commonly used imaging technique in medical diagnostics, particularly for neurological conditions like Alzheimer's disease.
Classes: The four classes represent different stages or severity levels of Alzheimer's disease, ranging from very mild to moderate dementia, along with a category for individuals who are non-demented, likely serving as a control or reference group.
Training and Testing Sets: The dataset is divided into separate sets for training and testing, enabling researchers to develop machine learning models that can predict and classify the stages of Alzheimer's disease accurately.
Model Development: The primary aim of sharing this dataset is to inspire the development of highly accurate models. Researchers and data scientists can leverage this dataset to create predictive models that can effectively categorize MRI images into the respective classes, aiding in early and accurate diagnosis of Alzheimer's disease.
Medical Importance: Accurate classification of Alzheimer's disease stages through MRI images can potentially assist medical professionals in early detection and intervention, enabling better patient care and management.
This dataset holds significant value for the scientific and medical communities, providing a valuable resource to develop and fine-tune algorithms aimed at precise Alzheimer's disease stage classification based on MRI images. Researchers can leverage this dataset to create machine learning or deep learning models, contributing to advancements in the early diagnosis and treatment of Alzheimer's disease.
Hands-on Tutorial
Outline
(i) Importing Necessary Libraries
(ii) Reading and Visualizing the Dataset
(iii) Data Augmentation and Handling Imbalanced Data
(iv) Data Splitting for Training, Validation, and Testing
(v) Convolutional Neural Network (CNN) Modeling
(vi) Training the CNN Model
(vii) Model Evaluation and Predictions
(viii) Confusion Matrix and Classification Report
Step 1: Importing Necessary Libraries
In this step, we import essential libraries such as OpenCV, Pandas, Matplotlib, Seaborn, and TensorFlow/Keras. These libraries offer functionalities for image processing, data manipulation, visualization, and building deep learning models.
import os
import cv2
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from keras.preprocessing.image import ImageDataGenerator
import keras
from keras.callbacks import EarlyStopping,ModelCheckpoint
import tensorflow as tf
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from tqdm import tqdm
from imblearn.over_sampling import SMOTEStep 2: Reading and Visualizing the Dataset
The code reads image data and organizes it into a Pandas DataFrame, storing image paths and their corresponding labels. Visualization using Seaborn's count plot helps understand the distribution of classes within the dataset.
images = []
labels = []
for subfolder in tqdm(os.listdir('/kaggle/input/alzheimers-dataset-4-class-of-
images/Alzheimer_s Dataset')):
subfolder_path = os.path.join('/kaggle/input/alzheimers-dataset-4-class-of-
images/Alzheimer_s Dataset', subfolder)
for folder in os.listdir(subfolder_path):
subfolder_path2=os.path.join(subfolder_path,folder)
for image_filename in os.listdir(subfolder_path2):
image_path = os.path.join(subfolder_path2, image_filename)
images.append(image_path)
labels.append(folder)
df = pd.DataFrame({'image': images, 'label': labels})
df
plt.figure(figsize=(15,8))
ax = sns.countplot(x=df.label,palette='Set1')
ax.set_xlabel("Class",fontsize=20)
ax.set_ylabel("Count",fontsize=20)
plt.title('The Number Of Samples For Each Class',fontsize=20)
plt.grid(True)
plt.xticks(rotation=45)
plt.show()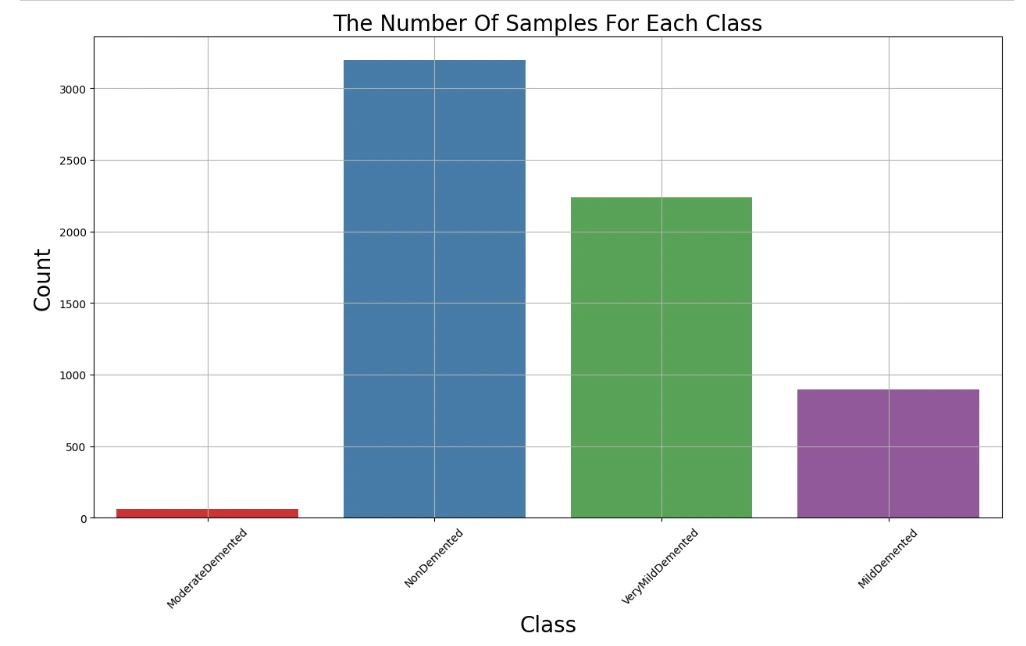
plt.figure(figsize=(50,50))
for n,i in enumerate(np.random.randint(0,len(df),50)):
plt.subplot(10,5,n+1)
img=cv2.imread(df.image[i])
img=cv2.resize(img,(224,224))
img=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.axis('off')
plt.title(df.label[i],fontsize=25)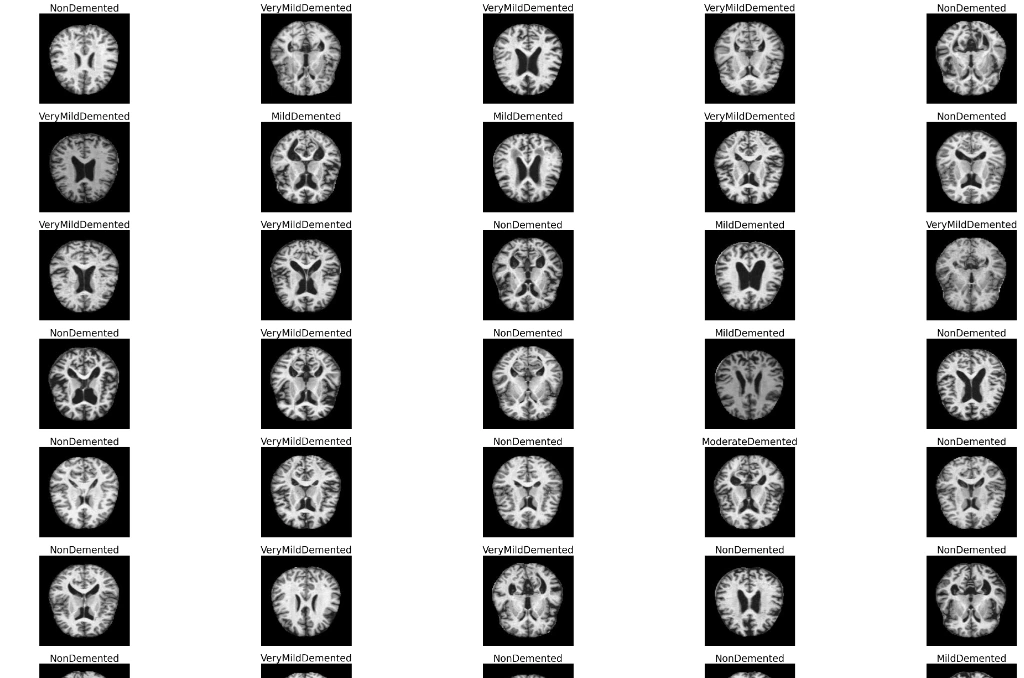
This visualization helps identify potential class imbalances, which is crucial for training an unbiased model.
Step 3: Data Augmentation and Handling Imbalanced Data
ImageDataGenerator from Keras facilitates data augmentation, which enhances the dataset by generating augmented versions of images, leading to better model generalization. Additionally, SMOTE (Synthetic Minority Over-sampling Technique) is used to address imbalances by generating synthetic samples for minority classes.
Size=(176,176)
work_dr = ImageDataGenerator(
rescale = 1./255
)
train_data_gen = work_dr.flow_from_dataframe(df,x_col='image',y_col='label',
target_size=Size, batch_size=6500, shuffle=False)train_data, train_labels = train_data_gen.next()
class_num=np.sort(['Alzheimer_s disease','Cognitively normal',
'Early mild cognitive impairment','Late mild cognitive impairment'])
class_num
sm = SMOTE(random_state=42)
train_data, train_labels = sm.fit_resample(train_data.reshape(-1, 176 * 176 * 3), train_labels)
train_data = train_data.reshape(-1, 176,176, 3)
print(train_data.shape, train_labels.shape)labels=[class_num[i] for i in np.argmax(train_labels,axis=1) ]
plt.figure(figsize=(15,8))
ax = sns.countplot(x=labels,palette='Set1')
ax.set_xlabel("Class",fontsize=20)
ax.set_ylabel("Count",fontsize=20)
plt.title('The Number Of Samples For Each Class',fontsize=20)
plt.grid(True)
plt.xticks(rotation=45)
plt.show()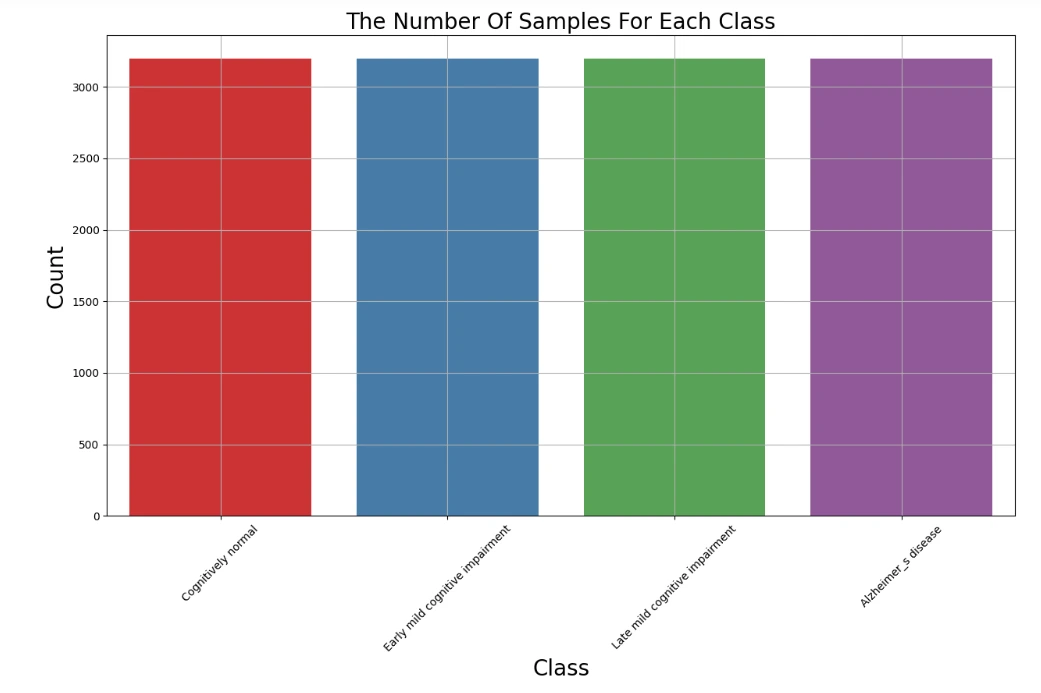
Step 4: Data Splitting for Training, Validation, and Testing
The dataset is split into training, validation, and test sets using train_test_split from sklearn. This step ensures that the model is trained on one set, validated on another, and tested on a separate unseen set.
X_train, X_test1, y_train, y_test1 = train_test_split(train_data,train_labels,
test_size=0.3, random_state=42,shuffle=True,stratify=train_labels)
X_val, X_test, y_val, y_test = train_test_split(X_test1,y_test1, test_size=0.5,
random_state=42,shuffle=True,stratify=y_test1)
print('X_train shape is ' , X_train.shape)
print('X_test shape is ' , X_test.shape)
print('X_val shape is ' , X_val.shape)
print('y_train shape is ' , y_train.shape)
print('y_test shape is ' , y_test.shape)
print('y_val shape is ' , y_val.shape)Stratification based on labels ensures proportional class distribution in each split, preventing bias.
Step 5: Convolutional Neural Network (CNN) Modeling
Here, we define the architecture of the CNN model using Keras' Sequential API. The model consists of convolutional layers, max-pooling layers, flatten layers, dense layers, and dropout layers for regularization.
model=keras.models.Sequential()
model.add(keras.layers.Conv2D(32,kernel_size=
(3,3),strides=2,padding='same',activation='relu',input_shape=(176,176,3)))
model.add(keras.layers.MaxPool2D(pool_size=(2,2),strides=2,padding='same'))
model.add(keras.layers.Conv2D(64,kernel_size=
(3,3),strides=2,activation='relu',padding='same'))
model.add(keras.layers.MaxPool2D((2,2),2,padding='same'))
model.add(keras.layers.Conv2D(128,kernel_size=
(3,3),strides=2,activation='relu',padding='same'))
model.add(keras.layers.MaxPool2D((2,2),2,padding='same'))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(1024,activation='relu'))
model.add(keras.layers.Dropout(0.3))
model.add(keras.layers.Dense(4,activation='softmax'))
model.summary()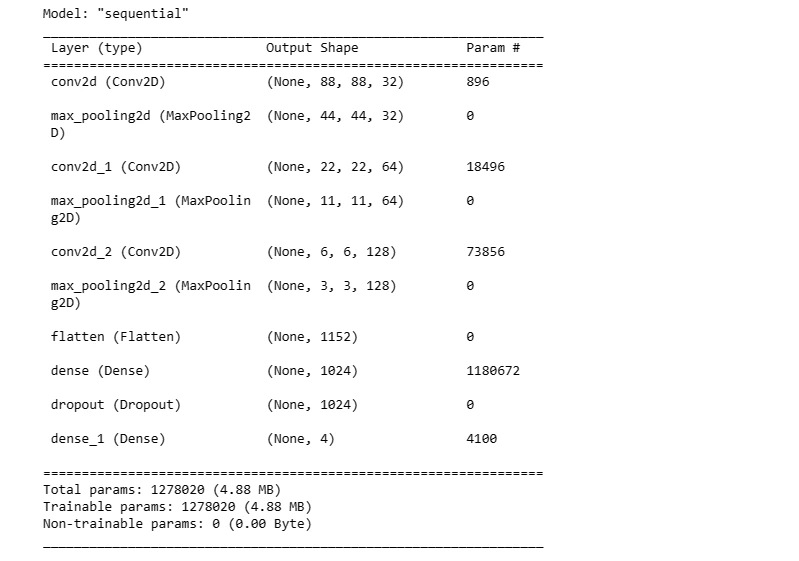
The summary provides an overview of the model architecture, including the number of parameters in each layer.
Step 6: Training the CNN Model
Before training, we compile the model, specifying the optimizer, loss function, and evaluation metrics. We fit the model to the training data while validating its performance on the validation set. Callbacks are used for early stopping and model checkpointing.
checkpoint_cb =ModelCheckpoint("CNN_model.h5", save_best_only=True)
early_stopping_cb =EarlyStopping(patience=10, restore_best_weights=True)
model.compile(optimizer ='adam', loss='categorical_crossentropy', metrics=['accuracy'])
hist = model.fit(X_train,y_train, epochs=50, validation_data=(X_val,y_val),
callbacks=[checkpoint_cb, early_stopping_cb])
The training process generates metrics such as loss and accuracy for both training and validation sets.
Step 7: Model Evaluation and Predictions
The trained model's performance is evaluated using the test set to assess its accuracy on unseen data. Predictions are made on the test set to generate predicted labels.
hist_=pd.DataFrame(hist.history)
hist_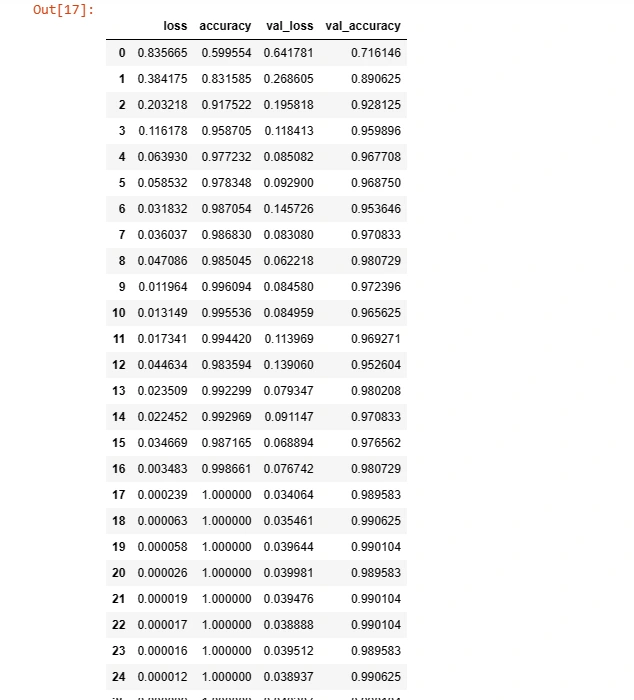
plt.figure(figsize=(15,10))
plt.subplot(1,2,1)
plt.plot(hist_['loss'],label='Train_Loss')
plt.plot(hist_['val_loss'],label='Validation_Loss')
plt.title('Train_Loss & Validation_Loss',fontsize=20)
plt.legend()
plt.subplot(1,2,2)
plt.plot(hist_['accuracy'],label='Train_Accuracy')
plt.plot(hist_['val_accuracy'],label='Validation_Accuracy')
plt.title('Train_Accuracy & Validation_Accuracy',fontsize=20)
plt.legend()
plt.show()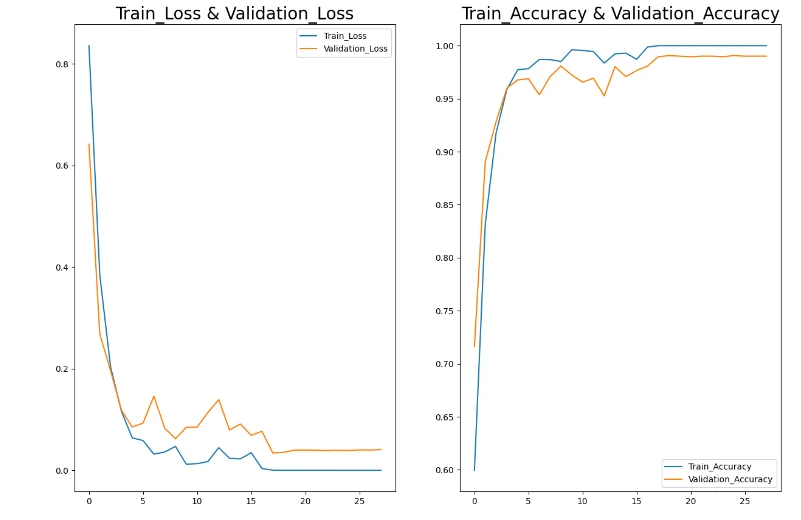
score, acc= model.evaluate(X_test,y_test)
print('Test Loss =', score)
print('Test Accuracy =', acc)
predictions = model.predict(X_test)
y_pred = np.argmax(predictions,axis=1)
y_test_ = np.argmax(y_test,axis=1)
df = pd.DataFrame({'Actual': y_test_, 'Prediction': y_pred})
df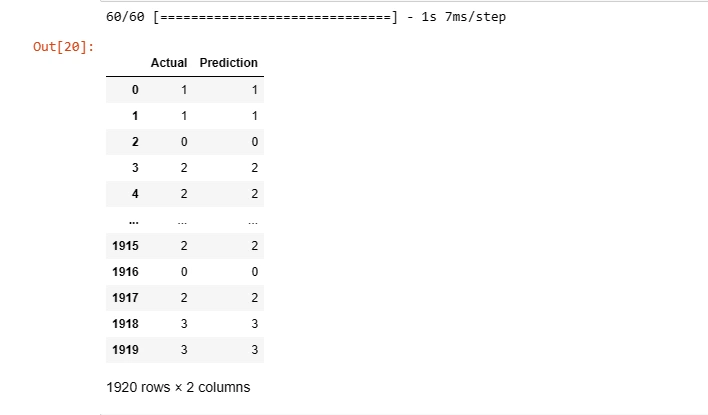
plt.figure(figsize=(50,50))
for n,i in enumerate(np.random.randint(0,len(X_test),20)):
plt.subplot(10,2,n+1)
plt.imshow(X_test[i])
plt.axis('off')
plt.title(f'{class_num[y_test_[i]]} ==== {class_num[y_pred[i]]}',fontsize=27)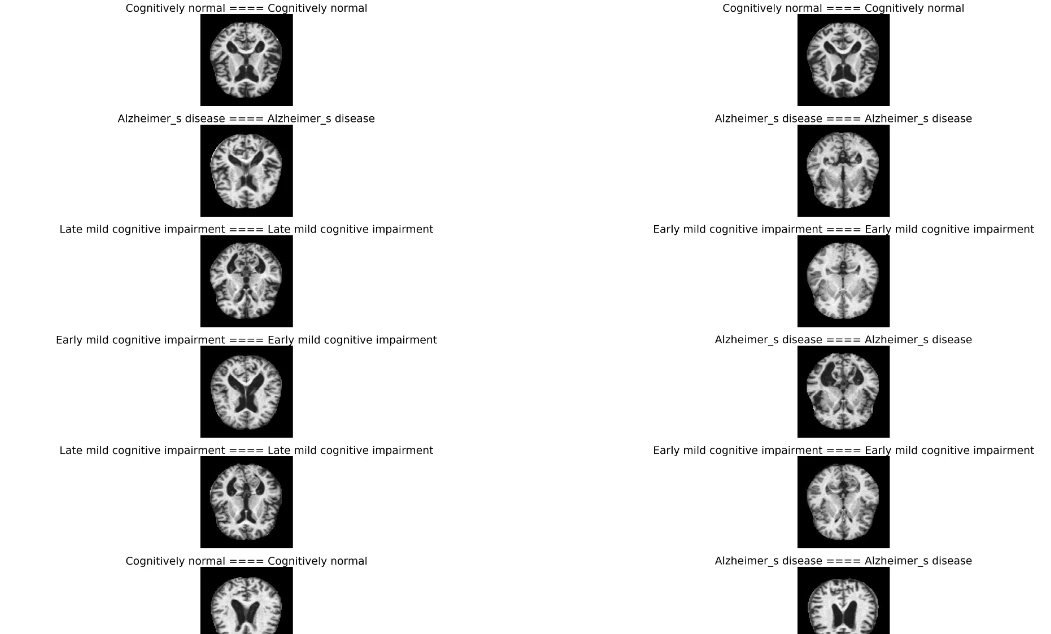
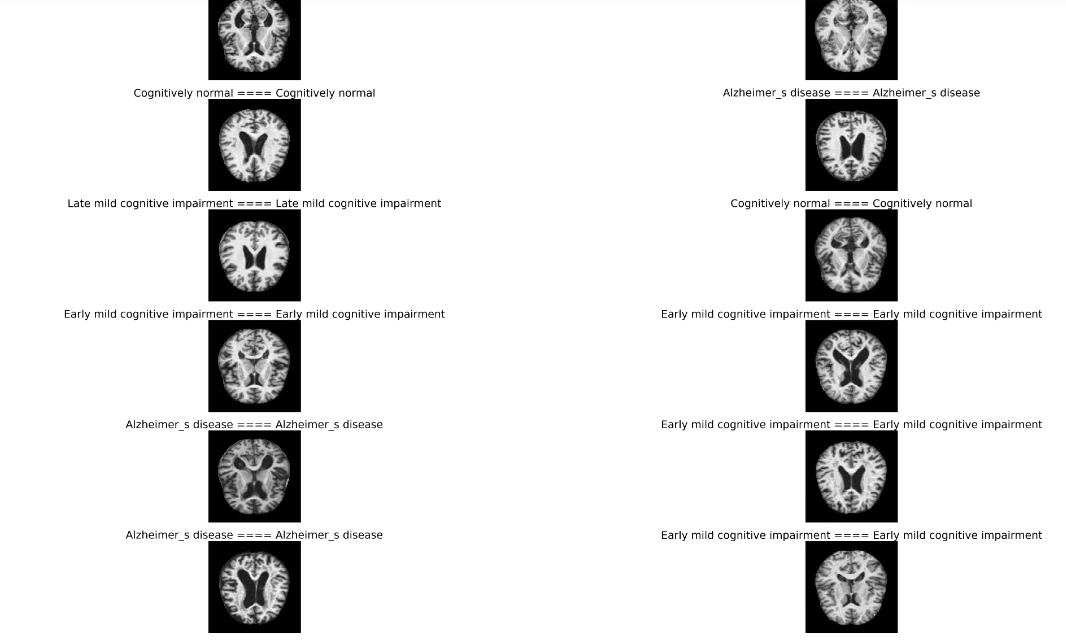
This step helps understand how well the model generalizes to new, unseen data.
Step 8: Confusion Matrix and Classification Report
The confusion matrix provides insights into the model's performance across different classes. Additionally, the classification report displays metrics such as precision, recall, and F1-score for each class.
CM = confusion_matrix(y_test_,y_pred)
CM_percent = CM.astype('float') / CM.sum(axis=1)[:, np.newaxis]
sns.heatmap(CM_percent,fmt='g',center = True,cbar=False,annot=True,cmap='Blues')
CM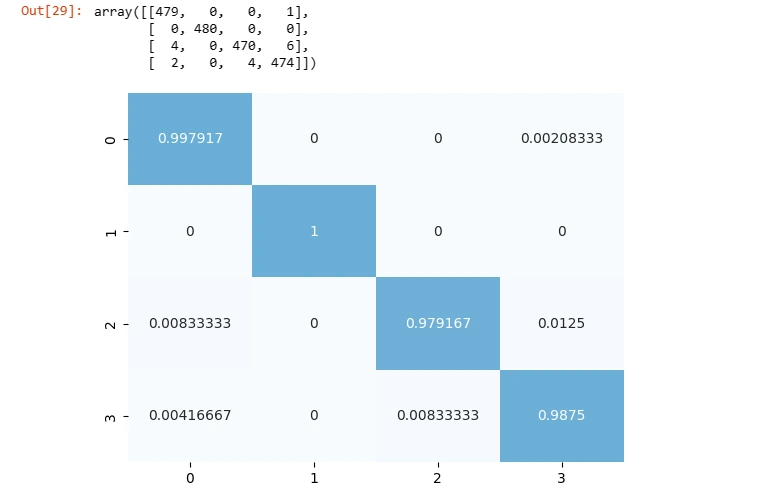
ClassificationReport = classification_report(y_test_,y_pred)
print('Classification Report is : ', ClassificationReport )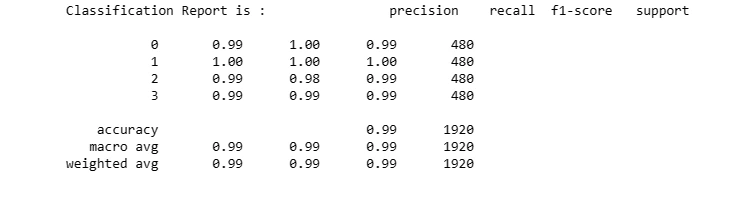
These metrics help assess the model's strengths and weaknesses in classifying different categories.
Uses of Alzheimer's Disease Detection in Healthcare
Computer Vision and Machine learning (ML) have several impactful uses in healthcare related to Alzheimer's disease. Some key applications include:
Early Detection and Diagnosis: AI and ML algorithms can analyze various data types (such as MRI images, genetic markers, cognitive assessments) to identify patterns indicative of Alzheimer's disease at an early stage. Early detection allows for timely interventions and treatment planning.
Predictive Analytics: Machine learning models can predict the risk of developing Alzheimer's disease based on a combination of factors like age, genetics, lifestyle, and medical history. This aids in personalized risk assessment and preventive care.
Image Analysis: AI algorithms can analyze MRI, PET (Positron Emission Tomography), or CT (Computed Tomography) scans to assist radiologists in detecting subtle changes in the brain structure and identifying markers of Alzheimer's disease progression.
Drug Discovery and Development: ML algorithms can be utilized in pharmaceutical research to screen compounds, simulate drug interactions, and predict the effectiveness of potential medications for treating Alzheimer's disease. This accelerates drug discovery processes.
Personalized Treatment Plans: AI-powered systems can analyze patient data and provide personalized treatment plans, considering individual variations in disease progression, genetic makeup, and response to therapies.
Clinical Decision Support: AI-based decision support systems assist healthcare providers by analyzing patient data, recommending suitable diagnostic tests, suggesting treatment options, and aiding in disease management decisions.
Monitoring Disease Progression: ML models can continuously monitor and analyze patient data, including cognitive assessments, vital signs, and imaging results, to track disease progression and modify treatment plans accordingly.
Patient Care and Support: AI-powered applications can offer support for caregivers and patients by providing educational resources, monitoring medication adherence, and facilitating remote patient monitoring to improve the quality of life for individuals with Alzheimer's disease.
Research Advancements: AI and ML techniques enable researchers to analyze vast amounts of data from various sources, uncovering new insights into the disease's underlying mechanisms, risk factors, and potential treatment approaches.
Clinical Trials Optimization: AI and ML assist in optimizing clinical trial processes by identifying suitable candidates, predicting trial outcomes, and optimizing trial design, leading to more efficient and effective trials for Alzheimer's disease treatments.
The integration of AI and ML technologies in healthcare for Alzheimer's disease showcases immense potential in early detection, personalized treatment, improved patient care, and accelerated research efforts toward finding a cure or effective interventions for this debilitating condition.
Conclusion
The fusion of AI and ML methodologies in the realm of Alzheimer's disease detection and diagnosis presents a paradigm shift in healthcare. Through meticulously curated datasets like the one focusing on Alzheimer's MRI images, innovative algorithms are forged to unravel the complexities of this neurodegenerative disorder.
With applications ranging from early detection and predictive analytics to personalized treatment plans and clinical decision support systems, the integration of AI and ML technologies holds immense promise in revolutionizing patient care, optimizing clinical trials, and steering advancements in research.
The collective strides made in leveraging these technologies signify a beacon of hope in the quest for effective interventions and, ultimately, a cure for Alzheimer's disease, underscoring the profound impact AI and ML have on improving healthcare outcomes.
Frequently Asked Questions
1. Can deep learning help diagnose Alzheimer's disease?
Yes, deep learning holds immense promise in aiding the diagnosis of Alzheimer's disease. Utilizing advanced neural networks and deep learning architectures, particularly with the analysis of MRI images, researchers can develop models capable of detecting intricate patterns and anomalies associated with Alzheimer's disease progression.
These models can effectively classify different stages of the disease, assisting in early and accurate diagnosis. By leveraging deep learning techniques to analyze complex datasets, including neuroimaging data, genetic markers, and clinical information, there's potential for more precise and timely identification of Alzheimer's, offering opportunities for early interventions and personalized treatment strategies.
2. Why is early detection of Alzheimer's disease important?
Early detection of Alzheimer's disease is crucial for several reasons. Firstly, it allows for timely intervention and implementation of treatment plans that may help slow the progression of the disease, potentially preserving cognitive functions and quality of life for a longer duration.
Secondly, early diagnosis provides an opportunity for individuals and their families to plan and make informed decisions regarding care, financial matters, and future arrangements. Additionally, it enables participation in clinical trials for experimental treatments at a stage when interventions might be more effective, ultimately offering better prospects for managing the condition and improving outcomes for individuals affected by Alzheimer's disease.
3. Can a deep-learning model distinguish Alzheimer's disease from normal cognition?
Yes, deep-learning models have demonstrated remarkable capabilities in distinguishing Alzheimer's disease from normal cognition. By leveraging advanced neural networks trained on diverse datasets, particularly using neuroimaging such as MRI or PET scans, these models can identify subtle patterns, structural changes, or biomarkers indicative of Alzheimer's pathology.
The models excel in recognizing distinct features associated with Alzheimer's disease, enabling accurate classification between individuals with the condition and those exhibiting normal cognitive function. This ability holds significant promise for early detection and intervention, contributing to improved diagnostic accuracy and potential advancements in Alzheimer's disease management.
Looking for high quality training data to train your alzheimer's disease detection model? Talk to our team to get a tool demo.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
