

Count Different Types of Blood Cell using CV and Labellerr
Computer vision automates RBC and WBC detection, replacing manual microscopy with fast, accurate, and consistent analysis. Using Labellerr’s annotation tools and COCO export, experts can create high-quality datasets and train reliable YOLO models for automated blood cell counting.

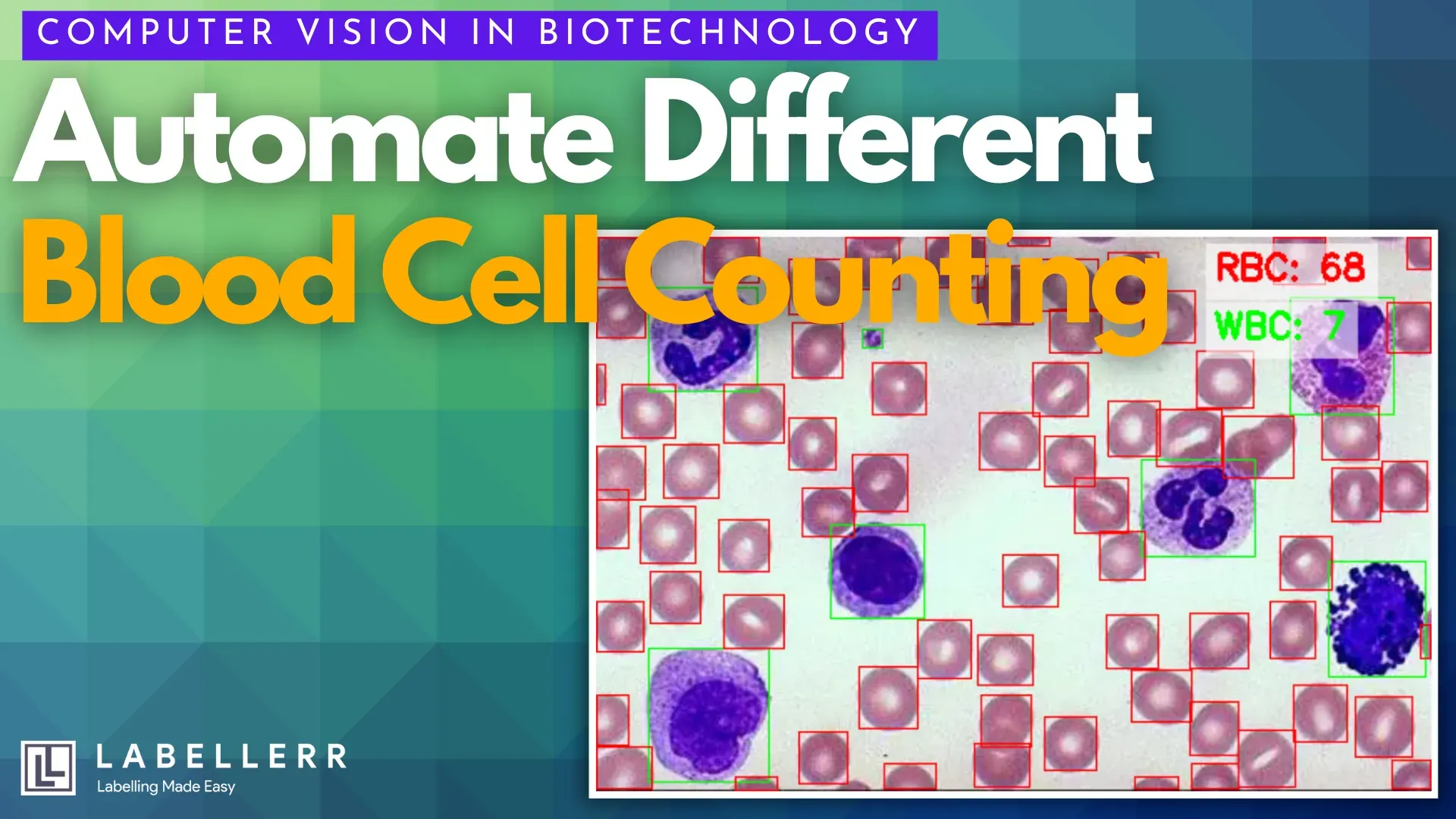
In medical diagnostics, the Complete Blood Count (CBC) is one of the most fundamental and frequently ordered tests.
From our experience working with healthcare professionals, we know that a key part of this process involves a specialist manually observing a blood smear under a microscope.
They must identify and count every single red blood cell (RBC) and white blood cell (WBC), a process that is not only slow and laborious but also susceptible to human fatigue and subjective error.
This manual bottleneck can delay diagnostics and increase costs. Our expertise in applied artificial intelligence has shown us a better way.
By building an authoritative and automated system, we can create a trustworthy tool that delivers fast, consistent, and accurate results, freeing up valuable expert time for more complex analysis.
The Solution
Computer vision (CV) offers a powerful and precise solution. We can use a state-of-the-art object detection model, such as YOLO (You Only Look Once), to train a system that replicates and often exceeds the capabilities of the human eye.
The process is straightforward:
- Train: We feed the AI model hundreds of sample images of blood smears.
- Learn: The model learns to identify the distinct visual features of a Red Blood Cell and a White Blood Cell.
- Detect: Once trained, the model can process a new image in milliseconds, drawing a bounding box around every cell it finds and classifying it as "RBC" or "WBC."
- Count: The system simply counts the number of boxes for each class, delivering an instantaneous and accurate cell count.
This approach transforms a tedious manual task into an automated, data-driven workflow, enabling labs to process samples at a scale previously unimaginable.
How Labellerr Helps Biotechnology
The most powerful AI model is useless without high-quality data to train it. This is the single biggest challenge in building specialized AI for biotechnology. You need "ground truth", a perfect dataset where a human expert has already identified all the cells.
This is where a platform like Labellerr becomes essential. It bridges the gap between expert knowledge and the AI model by making it easy to create this "ground truth" data.
- Upload Data: A medical expert can upload their sample microscopic images directly to the Labellerr platform.
- Annotate with Ease: Using simple on-screen tools, the expert can quickly draw boxes around each cell, labeling one class "RBC" and the other "WBC." The platform is designed for this exact task, making the annotation process fast and efficient.
- Export for Training: Once the images are labeled, Labellerr exports all the annotations into a single COCO JSON file. This file is a standardized format that contains the "ground truth" data, ready to be fed directly into the training pipeline for the YOLO model.
Labellerr streamlines the most critical and time-consuming part of the AI workflow: creating the high-quality, expert-verified dataset.
Creating Blood Cell Types Count Model using Labellerr
Here is a the YOLO model training workflow, based on the cookbook referenced to train your own blood cell counter after you have exported your annotated data from Labellerr.
# --- 1. Installation ---
# First, you need the 'ultralytics' library that contains the YOLO model
!pip install ultralytics
# --- 2. Data Preparation ---
from YOLO_fine_tunes.coco_yolo_converter import coco_to_yolo_converter
# Define paths
coco_json_path = 'path/to/your/exported_annotations.json'
image_dir = 'path/to/your/images/'
output_yolo_dir = 'yolo_dataset/'
# This function creates the 'data.yaml' file and the
# 'train/' and 'labels/' directories that YOLO needs.
coco_to_yolo_converter(
json_path=coco_json_path,
image_dir=image_dir,
save_dir=output_yolo_dir
)
# --- 3. Model Training ---
import torch
from ultralytics import YOLO
# Free up GPU memory before training
if torch.cuda.is_available():
torch.cuda.empty_cache()
# Load a pre-trained YOLO model
model = YOLO('yolov8n.pt') # 'n' is for the 'nano' version, fast and small
# Train the model on your new dataset
print("Starting model training...")
results = model.train(
data=f'{output_yolo_dir}/data.yaml',
epochs=100, # You can adjust the number of epochs
imgsz=640,
batch=16
)
print("Training complete. Model saved to 'runs/detect/train/...'")
# --- 4. Inference and Counting ---
import cv2
from collections import defaultdict
# Load your custom-trained model
trained_model = YOLO('runs/detect/train/weights/best.pt')
def detect_and_count(image_path, confidence_threshold=0.3):
# Run prediction
results = trained_model(image_path, conf=confidence_threshold)
img = cv2.imread(image_path)
# Dictionary to store counts
cell_counts = defaultdict(int)
# Loop through results
for r in results:
for box in r.boxes:
# Get class ID and name
cls_id = int(box.cls[0])
class_name = trained_model.names[cls_id]
# Add to count
cell_counts[class_name] += 1
# --- Draw bounding boxes on the image ---
x1, y1, x2, y2 = map(int, box.xyxy[0])
conf = float(box.conf[0])
# Assign color based on class
color = (0, 255, 0) if class_name == 'RBC' else (255, 0, 0)
cv2.rectangle(img, (x1, y1), (x2, y2), color, 2)
cv2.putText(img, f'{class_name} {conf:.2f}', (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
# --- Display the total counts on the image ---
count_text_y = 30
for cell_type, count in cell_counts.items():
text = f'{cell_type} Count: {count}'
cv2.putText(img, text, (10, count_text_y),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
count_text_y += 40
# Save or display the image
cv2.imwrite('output_detection.jpg', img)
print("Inference complete. Output image saved.")
print("Detected Counts:", dict(cell_counts))
# Example usage:
detect_and_count('path/to/your/test_blood_image.jpg')
Conclusion
The power of advanced AI models like YOLO is impressive, but it's essential to understand that the model is only one part of the equation.
The final performance of this automated blood cell counter is not determined by the complexity of the code, but by the quality of the data it was trained on.
A model trained with incomplete or inaccurate annotations will confidently produce the wrong counts. Therefore, the most critical step in any computer vision project is the data annotation.
A clean, accurate, and comprehensive dataset, built by experts on a platform like Labellerr, is the true foundation for building a reliable and trustworthy AI system for any use case.
FAQs
How does computer vision improve the accuracy of RBC and WBC counting?
Computer vision removes human fatigue, improves consistency, and provides rapid and accurate detection of RBCs and WBCs by analyzing each image uniformly.
Why is expert-verified annotation essential for training a blood cell detection model?
The model learns directly from the annotated examples. Precise labels ensure the AI accurately identifies and classifies cell types during real-world inference.
How does Labellerr simplify creating datasets for blood smear analysis?
Labellerr offers easy annotation tools and standardized COCO export, allowing experts to label cells quickly and generate high-quality datasets ready for YOLO training.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
