

Common Challenges and Solutions for Free Data Labeling Tools

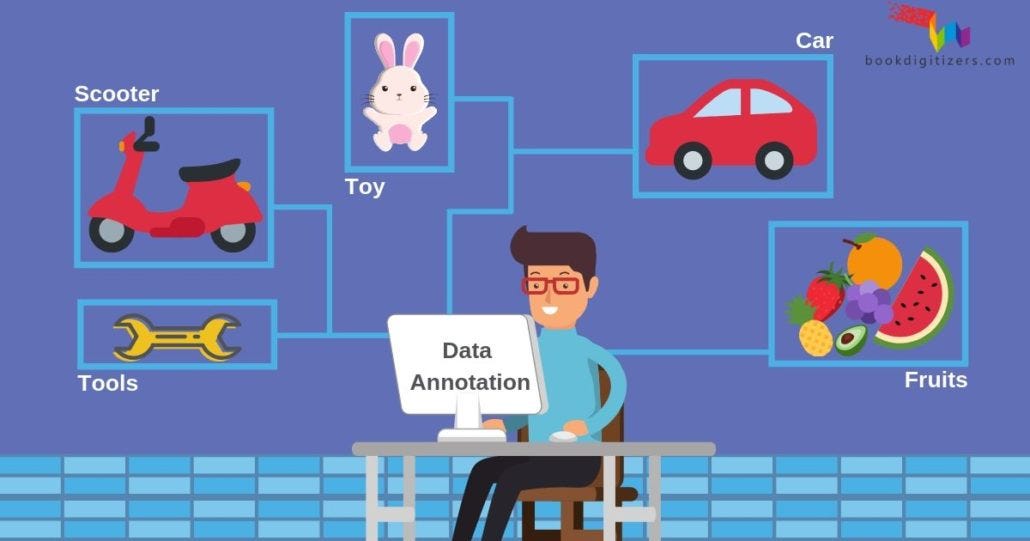
Table of Contents
- LabelMe
- VGG Image Annotator (VIA)
- Make Sense
- Imglab
- Why Labellerr
- Conclusion
- Frequently Asked Questions
Data labeling is of utmost importance in the field of machine learning and artificial intelligence as it provides labeled data, acting as ground truth, essential for training supervised learning models.
The process involves annotating data with relevant labels, enabling algorithms to learn patterns and make accurate predictions. Data labeling is critical for tasks such as object detection, image segmentation, sentiment analysis, and natural language processing, where models heavily rely on labeled examples for pattern recognition and decision-making.
Figure: Data Labelling
It ensures the quality and reliability of the dataset, directly influencing the performance and generalization capabilities of the trained models. Additionally, data labeling helps address bias and fairness concerns, benchmark model performance, and support domain-specific applications, making it a foundational step for human-centric and impactful AI systems.
For addressing the problem of annotating and labeling data for training a machine learning model, there are various different tools that are built. The user tends to use the tools as per their requirements.
For instance, in small-scale projects where the data used is not that large, users go for mainly open-source tools because of their low cost. But when it comes to large production levels, other factors are also considered, which include:
- Cloud-based services, if available.
- Collaborative features for multiple users.
- AI-Assisted Labelling.
LabelMe
LabelMe is an open-source web-based image annotation tool developed by the Computer Science and Artificial Intelligence Laboratory (CSAIL) at MIT. It is designed to facilitate the process of creating labeled datasets for various computer vision tasks, such as object detection, image segmentation, and keypoint annotation.
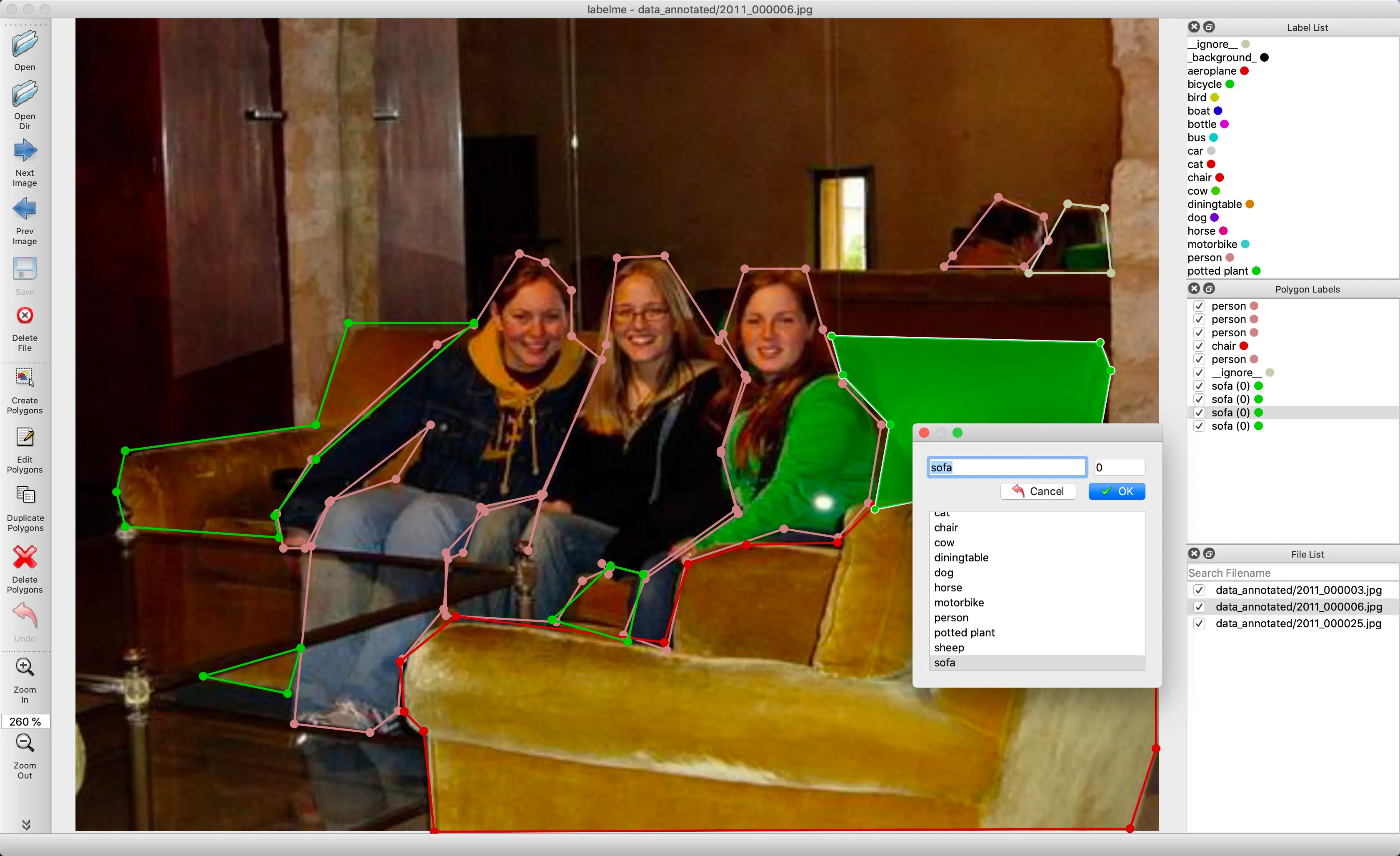
Figure: LabelMe Interface
LabelMe allows users to annotate images with bounding boxes, polygons, key points, and segmentation masks, enabling the creation of ground truth data for training and evaluating machine learning models.
Installation Steps
Below are the installation steps for labelme.
- Make sure you have Anaconda installed. If not, install Anaconda first. You can refer here for more details.
- Open the Anaconda Prompt.
- Run below instructions
# python3
conda create --name=labelme python=3
source activate labelme
# conda install -c conda-forge pyside2
# conda install pyqt
# pip install pyqt5 # pyqt5 can be installed via pip on python3
pip install labelme
# or you can install everything by conda command
# conda install labelme -c conda-forgeTo start labelme, Open Terminal, and type:
labelmeLimitations of the Labelme tool
Some Drawbacks which hinder the process of using the tool from beginners to experts include:
- Limited Scalability: LabelMe's web-based interface may become less efficient and responsive when working with a large number of images or complex annotations. This can be a concern for projects that require annotating thousands of images or more.
- Steep Learning Curve for Non-Technical Users: While LabelMe is designed to be user-friendly, it may still present a challenge for non-technical users who are not familiar with the tool's interface and concepts. The process of setting up and understanding the annotation workflow might require some technical expertise.
- Limited Annotation Tools: Although LabelMe supports various annotation types like bounding boxes, polygons, key points, and segmentation masks, it may lack some more advanced annotation options that other specialized tools may offer.
- Limited Dataset Formats: LabelMe supports the VOC-format dataset for semantic/instance segmentation and the COCO-format dataset for instance segmentation. While these formats are widely used, some users might prefer additional dataset formats to fit specific project requirements.
- Collaboration Challenges: While LabelMe does offer some collaboration features, such as sharing annotated images and working with multiple contributors, it may not be as robust as other dedicated annotation platforms that have more advanced collaboration functionalities.
- Maintenance and Updates: As an open-source project, LabelMe's development and maintenance may vary over time. Updates, bug fixes, and improvements might not be as frequent or comprehensive as with commercial alternatives.
- No Cloud-based Support: Unlike some other annotation platforms, LabelMe does not have built-in cloud-based support. This means that hosting and managing LabelMe for large-scale collaborative projects might require additional setup and maintenance efforts.
- Complex Installation Process: Installing LabelMe can be challenging, especially for users who are not familiar with the command shell or command-line interfaces. This complexity may deter some users from using the tool.
- Local Storage Requirement: LabelMe needs to be installed directly on the user's computer, which means large datasets might pose storage limitations and require sufficient disk space.
- Lack of Image Enhancement and Augmentation: LabelMe does not provide built-in tools for image enhancement or data augmentation, which are essential for improving model performance and handling data variations.
- Individual File Saving: LabelMe requires users to save each annotated file individually. This manual process can be time-consuming and cumbersome, especially when dealing with large datasets.
- Lack of Comprehensive Tutorials: While LabelMe's documentation exists, there may be a lack of comprehensive tutorials or beginner-friendly resources to help new users get started with the tool easily.
VGG Image Annotator (VIA)
VGG Image Annotator (VIA) is an open-source web-based image annotation tool developed by the Visual Geometry Group (VGG) at the University of Oxford. VIA is designed to facilitate the process of creating labeled datasets for computer vision tasks.
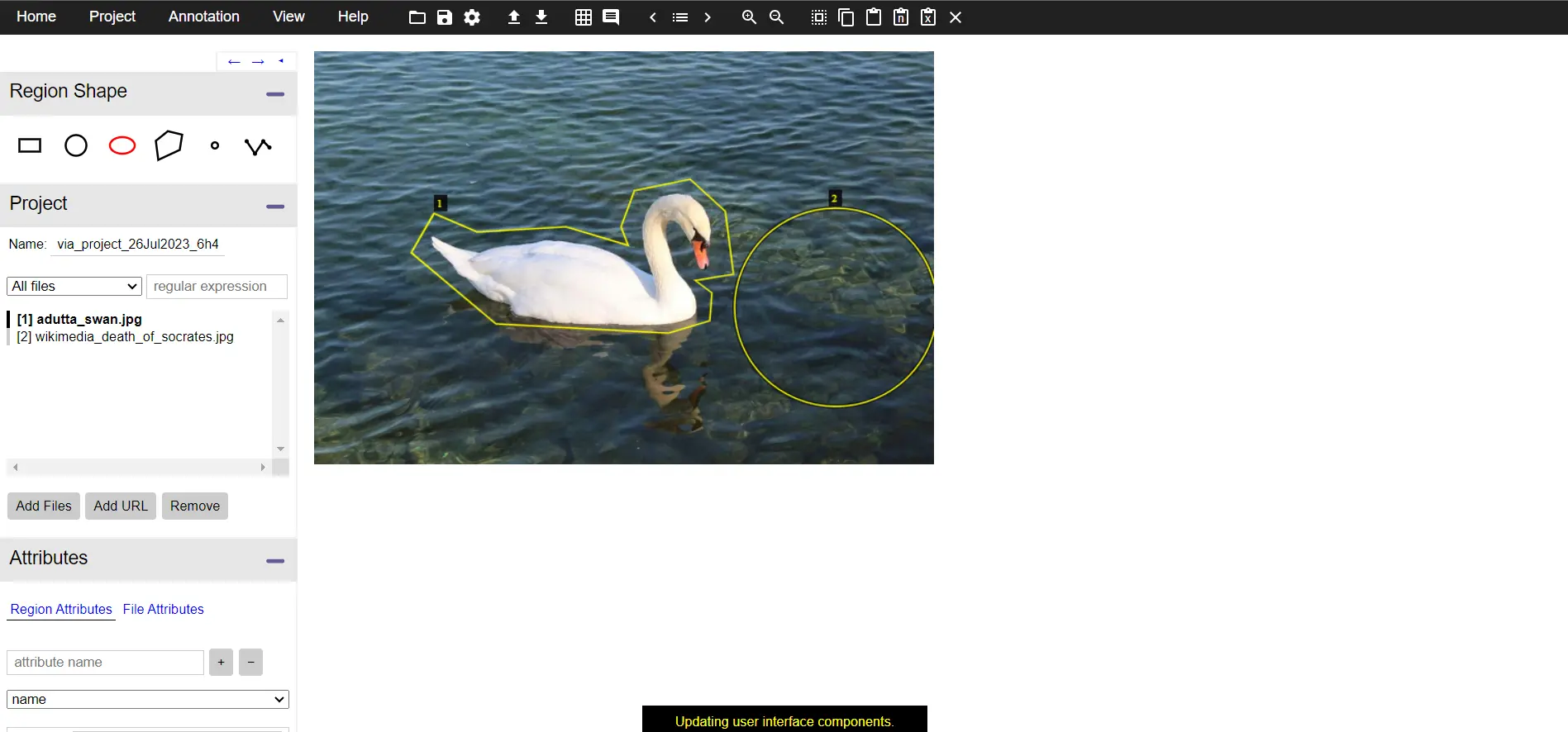
Figure: VGG Annotator Interface
It allows users to annotate images with various annotation types, making it suitable for tasks like object detection, instance segmentation, and keypoint annotation. Some key points which are to be mentioned include:
- Basic GUI: VIA has a simple graphical user interface with limited options for customization. While this makes it easy to use for beginners, it may lack some advanced features and settings found in more complex annotation tools.
- No Pre-uploaded Dataset: Users need to manually upload their images to VIA for annotation, which can be time-consuming, especially for projects with a large number of images.
- Individual Image Labeling: Each image must be labeled individually in VIA, which can be time-consuming and labor-intensive for large datasets, as users need to draw annotations for each image manually.
- Limited Shapes for Labeling: VIA offers a limited set of annotation shapes (e.g., bounding box, polygon, point), which might not be suitable for accurately labeling small or curved objects, potentially limiting the tool's usability for certain tasks.
- No Image Enhancement and Augmentation: VIA lacks built-in image enhancement and augmentation tools, which means users cannot perform adjustments like brightness, contrast, or data augmentation techniques directly within the tool.
Limitations of the VGG Annotation Tool
The VGG Image Annotator (VIA) is a valuable open-source image annotation tool developed by the Visual Geometry Group (VGG) at the University of Oxford. Despite its numerous advantages, the tool is not without limitations. Some of these include:
- Limited Platform Compatibility: VIA is a web-based tool, which means it primarily works on desktop computers or laptops with web browsers. It might not be optimized for use on mobile devices, limiting flexibility for users who prefer annotating on tablets or smartphones.
- Annotation Speed and Efficiency: While VIA is suitable for smaller-scale projects, its annotation speed might be slower compared to specialized annotation software or tools designed for high-throughput annotation tasks.
- Complexity with Large Datasets: Handling a large number of images and annotations in VIA might become cumbersome and resource-intensive, leading to slower performance and potential stability issues.
- Version Compatibility: As a software tool, VIA might require users to ensure compatibility with specific browser versions or system configurations, and updates to browsers or operating systems may cause compatibility issues.
- Project Management Features: VIA might lack certain project management features found in dedicated annotation platforms, such as task assignment, progress tracking, and data versioning.
- No AI-Assisted Annotation: Unlike some commercial annotation tools, VIA may not have built-in AI-assisted annotation features, which can speed up the annotation process and reduce manual effort.
- Learning Resources: While VIA's documentation and community support exist, the availability of comprehensive tutorials and learning resources might be limited compared to popular commercial annotation platforms.
- Storage and Data Backup: Users need to ensure proper data storage and backup practices independently since VIA does not offer cloud-based storage or automatic backup features.
Make Sense
MakeSense.ai is an AI-powered platform used for data labeling and annotation tasks. It offers a range of features to streamline the process of creating high-quality labeled datasets for machine learning and computer vision projects.
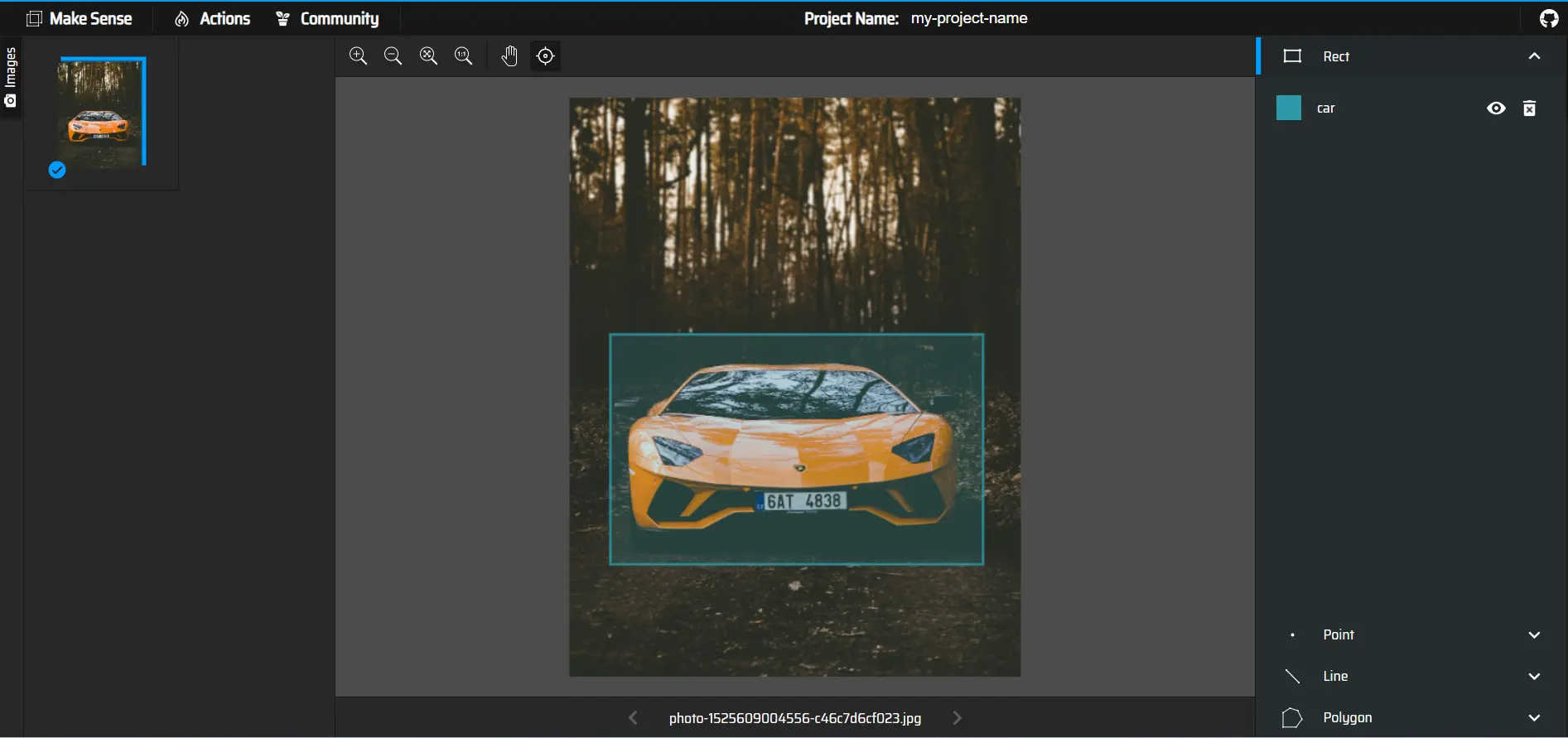
Figure: MakeSense AI Interface
The platform often utilizes AI-assisted annotation to help accelerate the annotation process by automating some aspects of labeling, making it more efficient and cost-effective. Some key points which are observed include:
- Slow Dynamic Labeling: The process of dynamic labeling, where users download individual images for annotation, can be slow and time-consuming, especially for large datasets.
- Slow Automatic Labeling: While "Make Sense" supports automatic labeling using AI models like SSD (Single Shot Multibox Detector) and PoseNet, the automatic labeling process might have latency issues and be slower than expected.
- Limited to Object Detection and Image Classification: The tool is primarily designed for object detection and image classification tasks, which may not fully cater to other complex annotation needs like semantic segmentation or instance segmentation.
- Limited Annotation Types: While "Make Sense" supports various annotation types, such as bounding boxes, key points, lines, and polygons, it may not offer specialized annotation types required for certain niche tasks.
- Pretrained Models: While the platform provides pre-trained models to aid in automatic labeling, the effectiveness of these models might depend on the specific dataset and task, potentially requiring manual adjustments.
- No Image Enhancement and Augmentation: The platform lacks built-in image enhancement and augmentation features, which are valuable for data preprocessing and improving model performance.
- Limited Download Formats: "Make Sense" offers limited options for downloading annotations, limiting export formats to YOLO, CSV files, and VOC format.
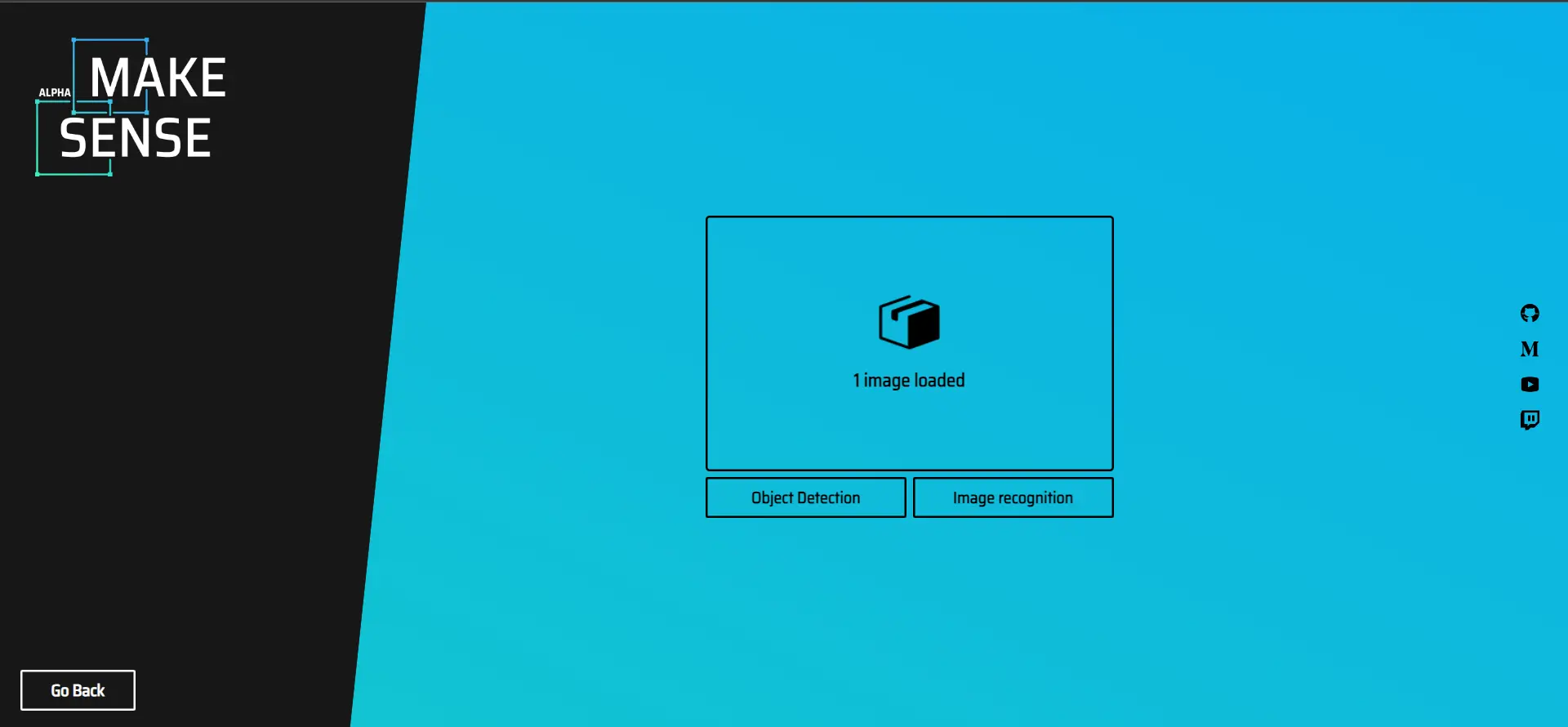
Figure: MakeSense AI Only provides options for object detection and Image Recognition
Imglab
imglab is an open-source web-based image annotation tool developed by Natural Intelligence (NI) for creating labeled datasets for computer vision tasks.
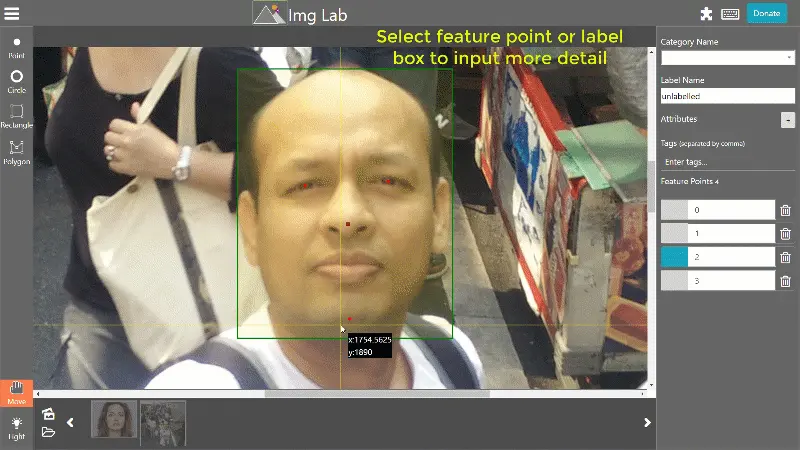
Figure: imglab Tool for Data Labelling
The tool allows users to annotate images with bounding boxes, keypoints, polygons, and other annotation types, making it suitable for various object detection, image segmentation, and keypoint detection tasks.
Installation Steps
In this section, we discuss the installation steps required for imglab. The installation process requires knowledge of the command shell.
Below are the required steps:
- Open cmd in Windows or terminal in Linux and type:
git clone https://github.com/NaturalIntelligence/imglab.git2. Install node and npm
3. Open the terminal and run:
npm install -g live-server to install node live server.4. Finally, open the terminal in /imglab/ folder and run
live-server One issue that may encounter while installing imglab is restricted access to the live server.

Figure: Live-Server Issue
So to configure that,
- Open Powershell as an administrator in Windows or terminal in sudo mode.
- Type:
Set-ExecutionPolicy Unrestricted- Now repeat the step 4 above again.
Make sure to reconfigure the access to Restricted again. This can be done by opening Powershell in administrator mode and typing:
Set-ExecutionPolicy RestrictedLimitations of imglab tool
- Limited Annotation Types: imglab supports bounding boxes and key points, but it may not offer more specialized annotation types needed for certain specific computer vision tasks, such as instance segmentation or semantic segmentation.
- User Interface Complexity: The user interface of imglab might be straightforward, but for users who need to become more familiar with the tool, the initial learning curve could be steeper, especially for complex annotation tasks.
- Scalability: While imglab is suitable for smaller datasets, its performance and efficiency might decrease when working with large-scale datasets, which could impact productivity.
- Collaboration Features: imglab doesen't have built-in features for team collaboration, making it less suitable for larger annotation projects involving multiple contributors.
- Export Format Compatibility: While imglab supports exporting annotations in formats like XML and JSON, it may lack compatibility with some specialized formats required by specific machine learning frameworks or libraries.
- Platform Compatibility: While imglab is written in Python and aims to be cross-platform compatible, users might encounter compatibility issues with certain operating systems or environments.
- Advanced Annotation Tools: imglab may not provide advanced quality control mechanisms, inter-annotator agreement calculations, or automation features, which can be beneficial for larger and more complex annotation projects.
- Limited AI Integration: imglab does not have built-in AI-assisted annotation features, which help speed up the annotation process and reduce manual effort.
- Support and Updates: Being an open-source project, the maintenance and updates support may not be that regular.
- Local storage requirements: As the software runs locally on your pc, the dataset which can be used limits the storage and performance of the computer.
- Complexity for installations: The user must be familiar with the command line interface, as, during installation, it is required.
Why Labellerr
Labellerr is a powerful and innovative data annotation platform that offers AI-powered image and video annotation services.
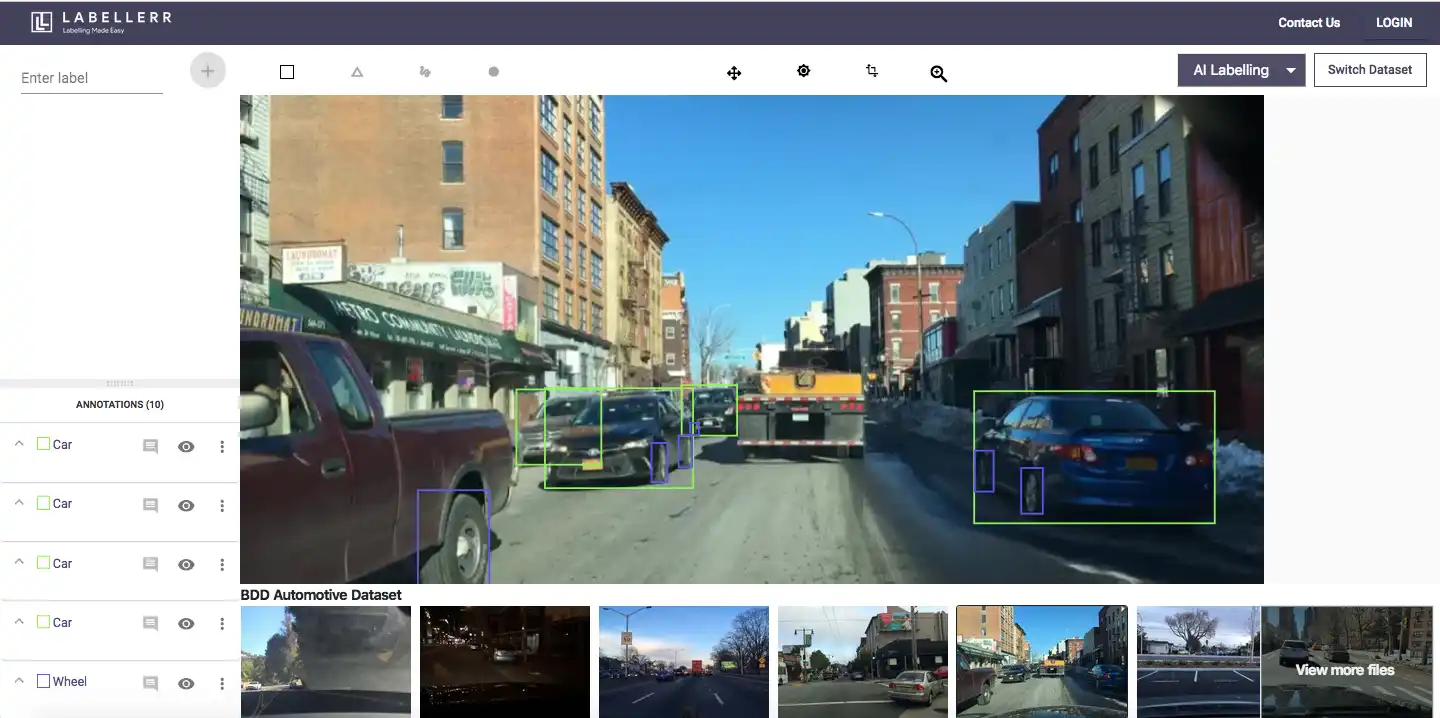
Figure: Labellerr Tool
Developed to simplify the creation of labeled datasets for machine learning and computer vision projects, Labellerr leverages cutting-edge artificial intelligence and machine learning algorithms to assist human annotators in the annotation process.
In the above sections, we saw various limitations of different annotation tools. Here, we are going to discuss various key points, where labellerr as a tool surpasses the above tools in the most efficient way.
- AI-Assisted Annotation: Labellerr leverages the power of artificial intelligence to assist human annotators in the labeling process. AI algorithms can predict and suggest annotations, making the annotation process faster and more efficient. This reduces the manual effort required from human annotators, resulting in significant time savings.
- Various Annotation Types: Labellerr supports a wide array of annotation types, including bounding boxes, polygons, keypoints, and image segmentation. This versatility enables users to create high-quality labeled datasets for different computer vision tasks, such as object detection, instance segmentation, and pose estimation.
- Scalability: Labellerr is designed to handle large datasets with ease, making it a scalable solution for annotation tasks of varying sizes. Whether the project involves a few hundred images or millions of data points, Labellerr can efficiently handle the workload.
- Quality Control: Labellerr incorporates built-in quality control mechanisms to ensure the accuracy and consistency of annotations. The platform may offer tools for annotator validation, inter-annotator agreement calculations, and annotation review processes, guaranteeing the reliability of the labeled data.
- Team Collaboration: Labellerr supports collaboration among multiple users and teams, allowing them to work together on the same annotation project. Users can assign tasks, track progress, and manage annotations efficiently, enhancing collaboration and project management.
- Flexible Integration: The annotations created using Labellerr can seamlessly integrate with various machine-learning frameworks and libraries. This integration facilitates the use of the annotated data for training and evaluating machine learning models, streamlining the entire machine learning pipeline.
- Domain-Specific Expertise: Labellerr may offer domain-specific expertise in certain areas, such as medical imaging or autonomous vehicles. This means that the platform can cater to the specific annotation needs of different industries and tasks, providing precise annotations tailored to the respective domains.
- Data Privacy and Security: Data privacy and security are crucial when dealing with sensitive or confidential datasets. Labellerr prioritizes data privacy and implements security measures to protect the integrity and confidentiality of the annotated data.
- Professional Support: The platform may provide professional support, assisting users with any questions, technical issues, or custom requirements they may have. Access to expert support ensures a smoother annotation process and faster resolution of any challenges that may arise.
- Time and Cost Efficiency: By leveraging AI-assisted annotation and scalable infrastructure, Labellerr can optimize the annotation process, reducing the overall time and cost required for annotating large datasets. This efficiency can be especially beneficial for businesses and research teams working on time-sensitive projects or with limited resources.
- Simple to use: As in most above cases for different tools, they require some command line code for installation process. In case of labellerr, it is a web based service. So the user can directly start the process of data labelling without going through any cumbersome installation process.
Conclusion
Data labeling is a crucial step in the field of machine learning and artificial intelligence as it provides labeled data, acting as ground truth, essential for training supervised learning models.
The process involves annotating data with relevant labels, enabling algorithms to learn patterns and make accurate predictions.
Data labeling is critical for tasks such as object detection, image segmentation, sentiment analysis, and natural language processing, where models heavily rely on labeled examples for pattern recognition and decision-making.
Data labeling ensures the quality and reliability of the dataset, directly influencing the performance and generalization capabilities of the trained models. Without accurate labels, models may not learn meaningful patterns and may fail to perform well on unseen data.
Additionally, data labeling helps address bias and fairness concerns, benchmark model performance, and support domain-specific applications, making it a foundational step for human-centric and impactful AI systems.
To address the problem of annotating and labeling data for training a machine learning model, various annotation and data labeling tools have been developed. The choice of the tool depends on the specific requirements of the project.
For small-scale projects with limited budgets, open-source tools like LabelMe and VGG Image Annotator (VIA) might be suitable due to their low cost and simplicity.
However, they may lack some advanced features and scalability required for larger production-level projects.
On the other hand, commercial tools Labellerr offer AI-assisted annotation, scalability, team collaboration, and integration with machine learning frameworks, making them ideal for large-scale and professional applications.
These tools often support various annotation types, providing flexibility for different computer vision tasks.
Frequently Asked Questions
1. Why is data labeling important in machine learning and artificial intelligence?
Data labeling provides labeled data, acting as ground truth, essential for training supervised learning models. It enables algorithms to learn patterns and make accurate predictions, making it critical for tasks such as object detection, image segmentation, sentiment analysis, and natural language processing.
Quality and reliable datasets directly influence the performance and generalization capabilities of trained models.
2. How does storing annotations in a single file for different images better compared to storing these annotations in different files?
In image classification or object detection tasks, how you organize your labeled data (annotations) can affect the ease of data handling, data loading, and the overall efficiency of your training and evaluation processes.
Whether you store the annotations in different JSON files or in one JSON file depends on the specific requirements of your project and the tools or libraries you are using. Here are some considerations for both approaches:
Storing annotations in different JSON files
Pros:
- Modularity: Keeping annotations in separate JSON files can make it easier to manage and update individual annotations without affecting the entire dataset. This can be helpful when new data is annotated or when you need to make corrections to specific annotations.
- Parallel processing: If you have a large dataset and plan to perform parallel data processing (e.g., multi-threaded loading), having annotations in separate files can enable concurrent access to different parts of the dataset, potentially improving data loading performance.
Cons:
- Complexity: Managing multiple JSON files might be more complex, especially if you need to deal with annotations spanning multiple files.
- Dependency on file organization: Properly organizing and linking the different files might become a challenge.
Storing annotations in one JSON file
Pros:
- Simplicity: Having all annotations in one JSON file simplifies data handling since you only need to deal with one file for the entire dataset.
- Ease of distribution: Distributing the dataset becomes straightforward as you only need to share one file.
Cons:
- Scalability: If you have a large dataset, storing all annotations in a single file might lead to performance issues, especially during data loading and processing.
- Version control and updates: Updating annotations might require modifying the entire JSON file, leading to potential conflicts in version control systems.
In many cases, both approaches can work effectively. The decision often depends on the size of the dataset, the specific requirements of the project, and the tools or libraries you use to work with the data.
If you are using popular deep learning frameworks like TensorFlow or PyTorch, they have specific data loading utilities (e.g., tf.data in TensorFlow, DataLoader in PyTorch) that can handle data from both single and multiple JSON files efficiently.
For smaller datasets, a single JSON file might be more convenient, while for larger datasets, splitting the annotations into separate files could provide performance benefits.
3. How does Labellerr surpass other data annotation tools?
Labellerr offers AI-assisted annotation, various annotation types, scalability, quality control, team collaboration, flexible integration, domain-specific expertise, data privacy, professional support, time and cost efficiency, making it suitable for large-scale and professional applications.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
