

Top Data Labeling Tools: Features & Use Cases
Explore top data labeling tools to enhance AI model accuracy, speed, and performance. Learn key features, use cases, and how to choose the best tool.


Let’s see, so you’re working on a machine learning project, and everything seems ready to go, the model, the pipeline, the data.
But there’s one big problem: the data is unlabelled, and labeling it manually could take weeks or even months. Sounds exhausting, right?
If you’ve ever had to label large amounts of data, you know how frustrating and time-consuming it can be.
Whether it’s tagging images for an AI system or labeling text for sentiment analysis, manual data labeling can feel overwhelming.
Thankfully, there are a few data labeling tools are here to make the process faster and easier.
In this guide, we’ll introduce you to some of the top data labeling tools, highlight their features, and explain how they can help solve your data labeling challenges.
Here is a quick overview of the best data labeling tools.
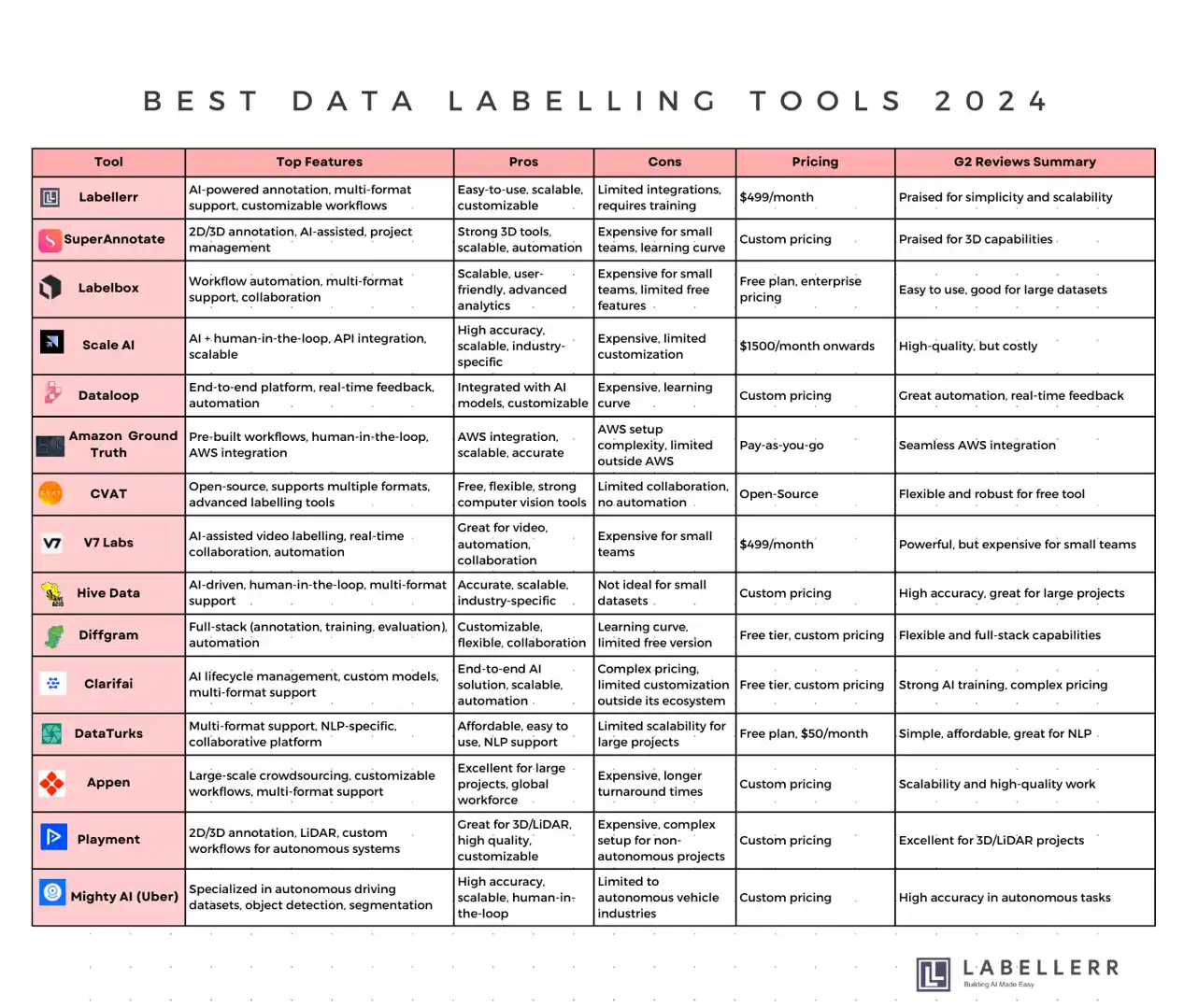
What are Data labeling Tools?
Data labeling tools are software platforms or applications designed to assist in the process of annotating data to make it understandable and usable by machine learning models.
These tools play a crucial role in preparing datasets that are essential for training artificial intelligence (AI) or ML models to interpret and make sense of different types of data, such as text, images, audio, and video.
What does data labeling tools do?
Data labeling tools are designed to streamline the process of assigning labels or tags to raw data, transforming it into a structured format that can be fed into machine learning algorithms.
The purpose of these tools is to automate and simplify the data annotation process, which is often a time-consuming and labor-intensive task when done manually.
Key Functions of Data labeling Tools:
- Annotation and Tagging: The core function of data labeling tools is to annotate data by applying labels to specific elements within a dataset.
For example, in an image dataset, this could involve tagging objects like cars, animals, or traffic signs. - Data Organization: These tools help in organizing data systematically, making it easier for data scientists and machine learning engineers to handle large volumes of data.
- Automation: Modern data labeling tools incorporate machine learning capabilities to assist in the labeling process.
They can predict labels based on previously labeled data, significantly reducing manual work. - Quality Control: These tools provide mechanisms to review and validate the labeled data to ensure accuracy and consistency, leading to higher quality datasets for AI training.
Why are they required?
The main purpose of data labeling tools is to create a clean, well-structured dataset that enables AI and machine learning models to learn and make accurate predictions.

High-quality data labeling is essential for the performance and reliability of these models, as the labeled data serves as the foundation on which the models are trained.
Data labeling tools are used across various applications, including:
- Computer Vision: For tasks like object detection, image classification, and facial recognition.
- Natural Language Processing (NLP): For sentiment analysis, text classification, and named entity recognition.
- Speech Recognition: For transcribing audio into text and identifying different sounds or words in audio data.
How are they needed in AI and Machine Learning?
Data labeling tools are vital in AI and machine learning because they directly impact the accuracy and performance of machine learning models.
Here are some reasons why data labeling tools are so important in the AI and machine learning process:
1. High-Quality Training Data
The success of AI models largely depends on the quality of the training data they are fed.
Data labeling tools ensure that the data is accurately tagged and structured, which leads to more reliable and effective models.
Properly labeled data helps machine learning algorithms recognize patterns and make predictions with higher precision.
2. Efficiency and Scalability
Data labeling tools significantly speed up the annotation process by automating repetitive tasks and providing collaborative features.
This efficiency is crucial when dealing with large datasets, as it allows data scientists and engineers to scale their projects without getting bogged down by manual labeling efforts.
3. Improved Model Performance
Accurate labels are the backbone of any machine learning model's training phase.
When data is labeled correctly, the model's learning process becomes more straightforward, leading to improved performance in tasks like image recognition, language processing, and predictive analysis.
4. Reducing Human Error
Manual data labeling is prone to errors and inconsistencies, especially when dealing with massive datasets.
Data labeling tools help reduce these errors by incorporating AI-driven suggestions, validation mechanisms, and quality control checks, which ensure that the labeled data is both consistent and accurate.
5. Automation and AI Integration
Advanced data labeling tools leverage AI to assist in the annotation process, which makes it possible to label data faster and with greater accuracy.
For example, these tools can use machine learning algorithms to auto-detect objects in images or suggest labels for text data based on context, thus enhancing the overall productivity of the labeling process.
6. Cost-Effectiveness
Using data labeling tools can significantly reduce the cost associated with data annotation.
By automating large portions of the labeling work, these tools minimize the need for extensive manual input, which can be resource-intensive and expensive.
This cost-efficiency is especially valuable for organizations handling large-scale AI and machine learning projects.
How to Choose the Best Data labeling Tool?
Selecting the right data labeling tool is a crucial step in building successful AI and machine learning models.
The right tool can significantly streamline the data annotation process, improve accuracy, and reduce costs.
Here’s a detailed guide on how to choose the best data labeling tool for your specific needs.
Key Features to Look For
When choosing a data labeling tool, it's essential to consider several key features that can help optimize the data annotation process and improve the overall efficiency of your AI projects.
1. Annotation Capabilities
- Look for tools that support multiple annotation types, such as text, image, video, and audio.
The tool should handle various tasks like object detection, image segmentation, sentiment analysis, or named entity recognition, depending on your project needs. - Advanced tools offer features like polygon annotations, keypoint tracking, and 3D annotations, which are crucial for more complex data requirements.
2. Automation and AI Integration
- The best data labeling tools leverage AI to automate repetitive tasks, significantly reducing manual work.
Look for features like auto-labeling, where the tool uses machine learning to predict and apply labels based on existing data. - Tools that use AI-driven models for annotation will improve labeling speed and accuracy, especially when working with large datasets.
3. Collaboration and Team Management
- If you're working with a team, it's important to choose a tool that supports collaborative features.
Look for tools that allow multiple users to work on the same project simultaneously and provide features like task assignment, real-time updates, and version control. - Built-in communication tools and activity tracking can help streamline workflows, making it easier to manage large-scale annotation projects.
4. Quality Control Mechanisms
- High-quality data is critical for effective machine learning. Tools with built-in quality control features help ensure that your annotations are accurate and consistent.
Look for features like annotation review, approval workflows, and validation checks. - Some tools offer consensus scoring and inter-annotator agreement metrics to help identify discrepancies and improve data quality.
5. Scalability
- The tool should be able to handle large datasets and scale as your project grows.
Scalability is essential for handling increases in data volume and complexity without compromising the annotation process's efficiency. - Ensure that the tool can easily integrate with your existing data pipelines and support batch processing for faster data annotation.
6. Data Security and Privacy
- For sensitive or confidential data, it's essential to choose a tool that offers robust security features.
Look for tools with data encryption, secure access controls, and compliance with industry standards like GDPR or HIPAA. - Ensure that the tool provides options for on-premises deployment or private cloud hosting if data security is a top priority.
Comparing Free vs. Paid Options
One of the significant considerations when choosing a data labeling tool is deciding between free and paid options. Both have their pros and cons, depending on your project's requirements and budget.
- Free Data labeling Tools
Pros:
- Cost-effective for small projects or startups with limited budgets.
- Open-source tools often have a large community of users and contributors, which means continuous updates and improvements.
- Great for educational purposes or for organizations just getting started with data annotation.
Cons:
- Limited features and automation capabilities compared to premium tools.
- May lack robust security features, which could be a concern for handling sensitive data.
- Support and troubleshooting can be slower, relying primarily on community forums rather than dedicated customer service.
Examples of Free Tools:
- LabelImg (for image annotation)
- VGG Image Annotator (VIA)
- CVAT (Computer Vision Annotation Tool)
2. Paid Data labeling Tools
Pros:
- Offer advanced features like AI-assisted labeling, automation, and integration with other tools and platforms.
- Include dedicated customer support, regular software updates, and extensive documentation.
- Provide better data security, compliance features, and enterprise-level scalability.
Cons:
- Can be costly, which may not be suitable for small businesses or individual projects.
- Some tools require a long-term commitment, with pricing plans that might not be flexible.
Examples of Paid Tools:
- SuperAnnotate
- Labelbox
- Dataloop.ai
Evaluating User Interface and Integration Capabilities
The user interface (UI) and integration capabilities of a data labeling tool can greatly impact your team's productivity and the overall effectiveness of the annotation process.
1. User-Friendly Interface
- A well-designed and intuitive user interface is crucial, especially for beginners.
The tool should be easy to navigate, with a clear layout that doesn't require extensive training to use. - Features like drag-and-drop functionality, easy label management, and visual aids for annotation can make the process smoother and more efficient.
2. Customization Options
- Customization is important if you have specific requirements for your project.
Look for tools that allow you to customize the labeling interface, create tailored workflows, and adjust annotation settings according to your needs. - Tools that support the creation of custom labels, classes, and annotation rules can help improve the accuracy and relevance of your dataset.
3. Integration with Existing Systems
- The ability to integrate the data labeling tool with your existing tech stack is essential for seamless data workflows.
Check if the tool supports integration with popular machine learning frameworks, cloud storage platforms, and data management systems like AWS, Google Cloud, or TensorFlow. - Integration capabilities allow for direct data import/export, reducing the time and effort needed to move data between different platforms.
4. API Support and Extensibility
- Tools with robust API support are highly valuable for automating the annotation process and connecting with other software systems.
API access enables you to programmatically interact with the tool, automate tasks, and customize functionality to meet your project's needs. - Extensible tools can adapt to evolving project requirements, making it easier to scale up or modify your data labeling processes as needed.
Popular Data labeling Tools for Machine Learning
Choosing the right data labeling tool is crucial for the success of machine learning projects.
The market offers a wide range of data labeling tools designed to cater to various needs, from industry-leading platforms to open-source options and AI-powered solutions.
Let's explore some of the most popular data labeling tools across these categories.
Top Tools in the Industry
Several data labeling tools stand out in the industry for their features, usability, and effectiveness. These tools are widely adopted by enterprises and AI researchers to manage large-scale data annotation projects.
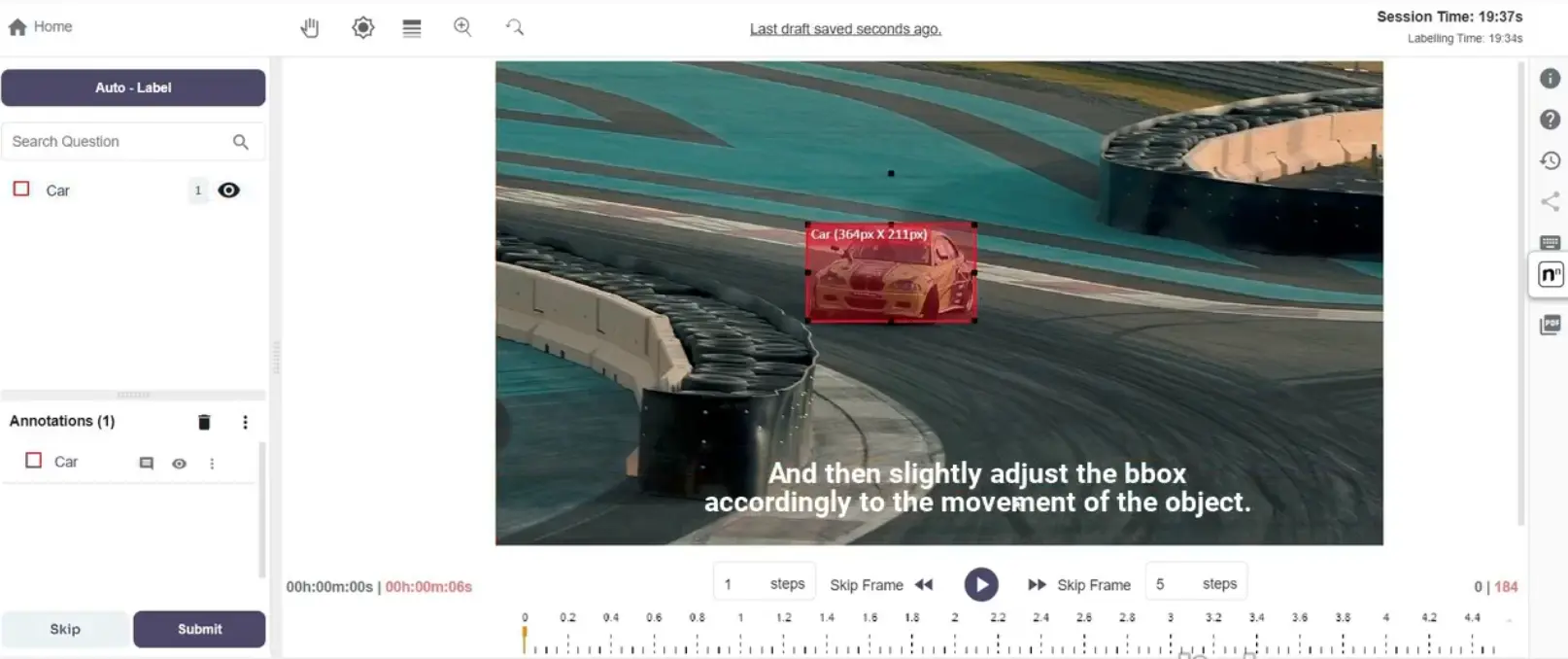
1. Labellerr
Labellerr is a versatile data labeling platform that caters to industries like healthcare, automotive, and retail by streamlining the annotation process with AI-powered tools.
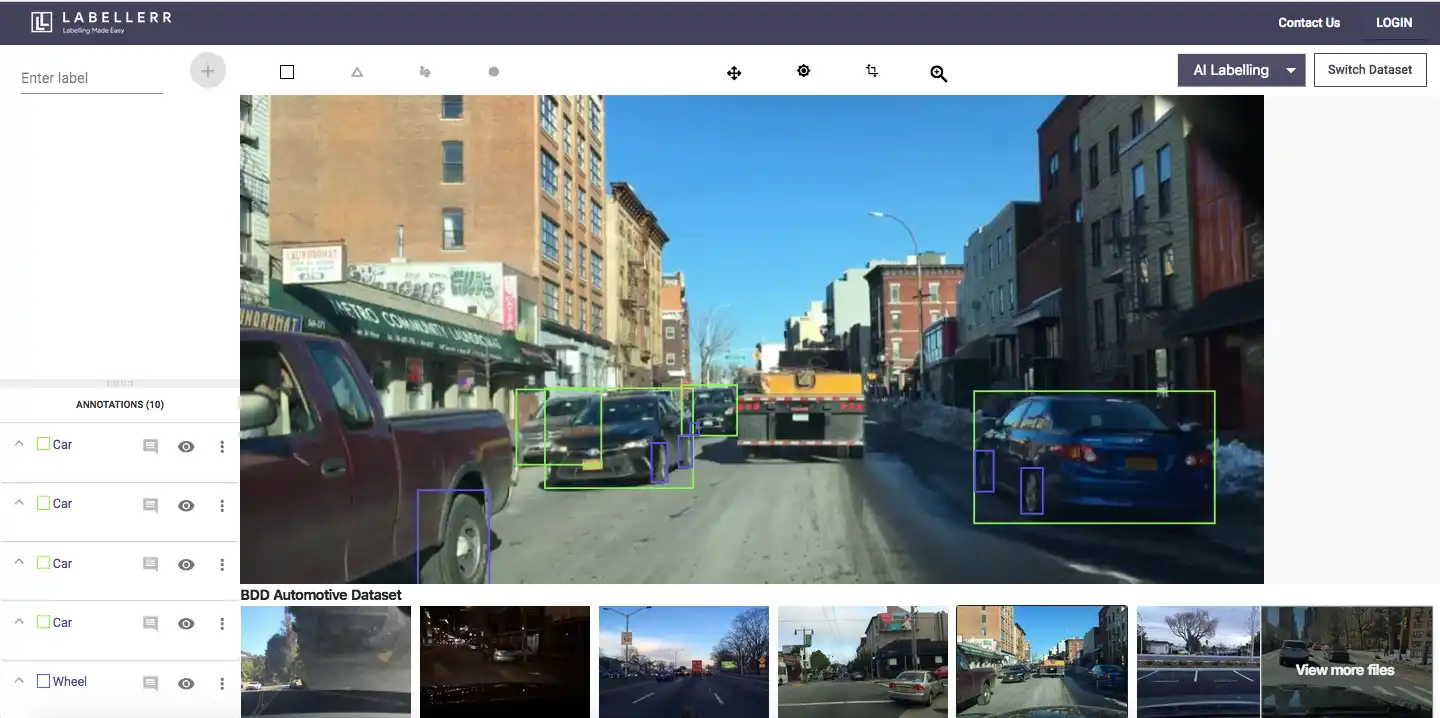
Labellerr provides a range of features, including multi-format data handling, workflow automation, and collaboration, making it suitable for organizations seeking efficient labeling solutions.
Its intuitive interface makes it easy for both beginners and experts, allowing faster data labeling and annotation while maintaining accuracy.
Top Features:
- AI-powered annotations for faster labeling
- Supports a variety of file formats (text, image, video, etc.)
- Integrates with multiple platforms for seamless workflows
- Real-time collaboration tools
- Customizable workflows for specific needs
Pros:
- Easy to use interface
- Efficient AI-assisted annotation
- Custom workflows
- Scalable to meet enterprise needs
Cons:
- Limited integrations with external tools
- Might require training for complex use cases
Pricing:
- Researcher Plan: You can use Labellerr for free, with up to 2,500 data credits and 1 seat.
- Pro Plan: $499/mo
- Enterprise Plan: Custom Pricing Contact Sales
G2 Reviews:
Labellerr is highly rated on G2 for its simplicity, efficiency, and ability to handle large datasets with ease. Users appreciate its scalability and collaboration features.
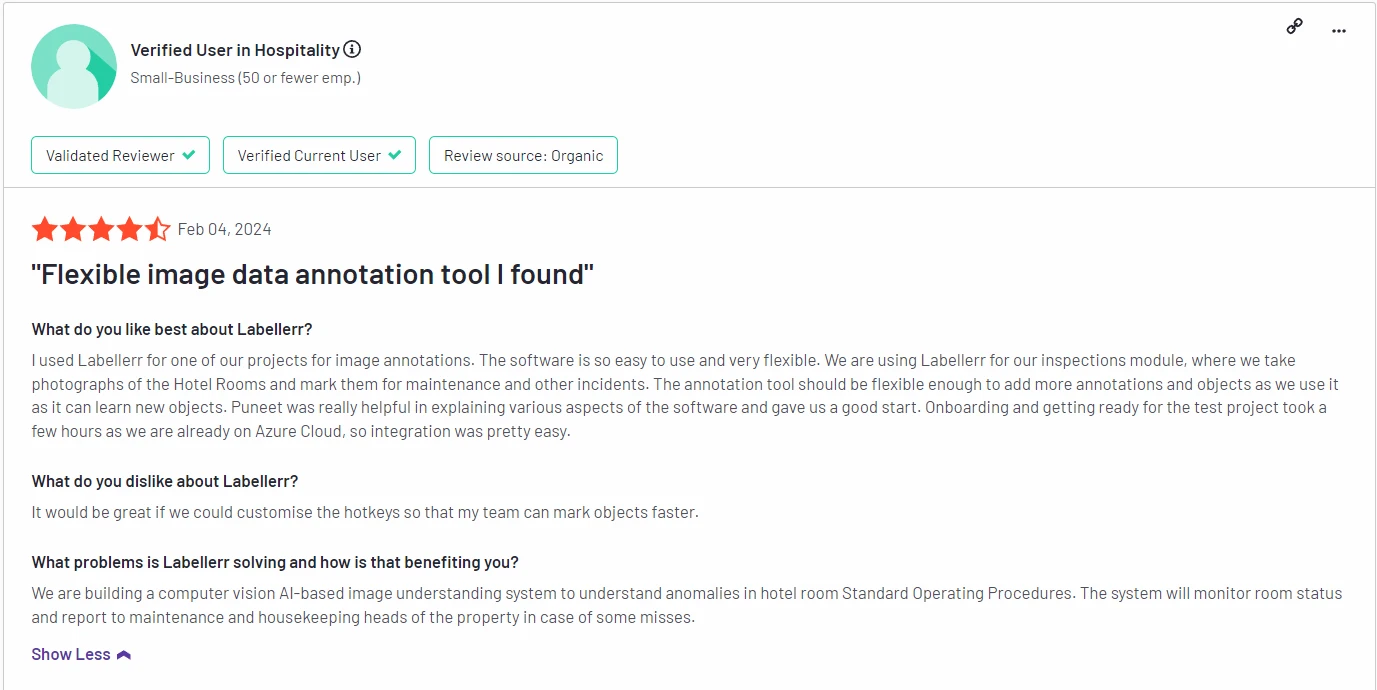
G2 review 4.8 out of 5. Check the detailed review here.
2. SuperAnnotate
SuperAnnotate is a widely recognized platform for data labeling, particularly in computer vision applications.
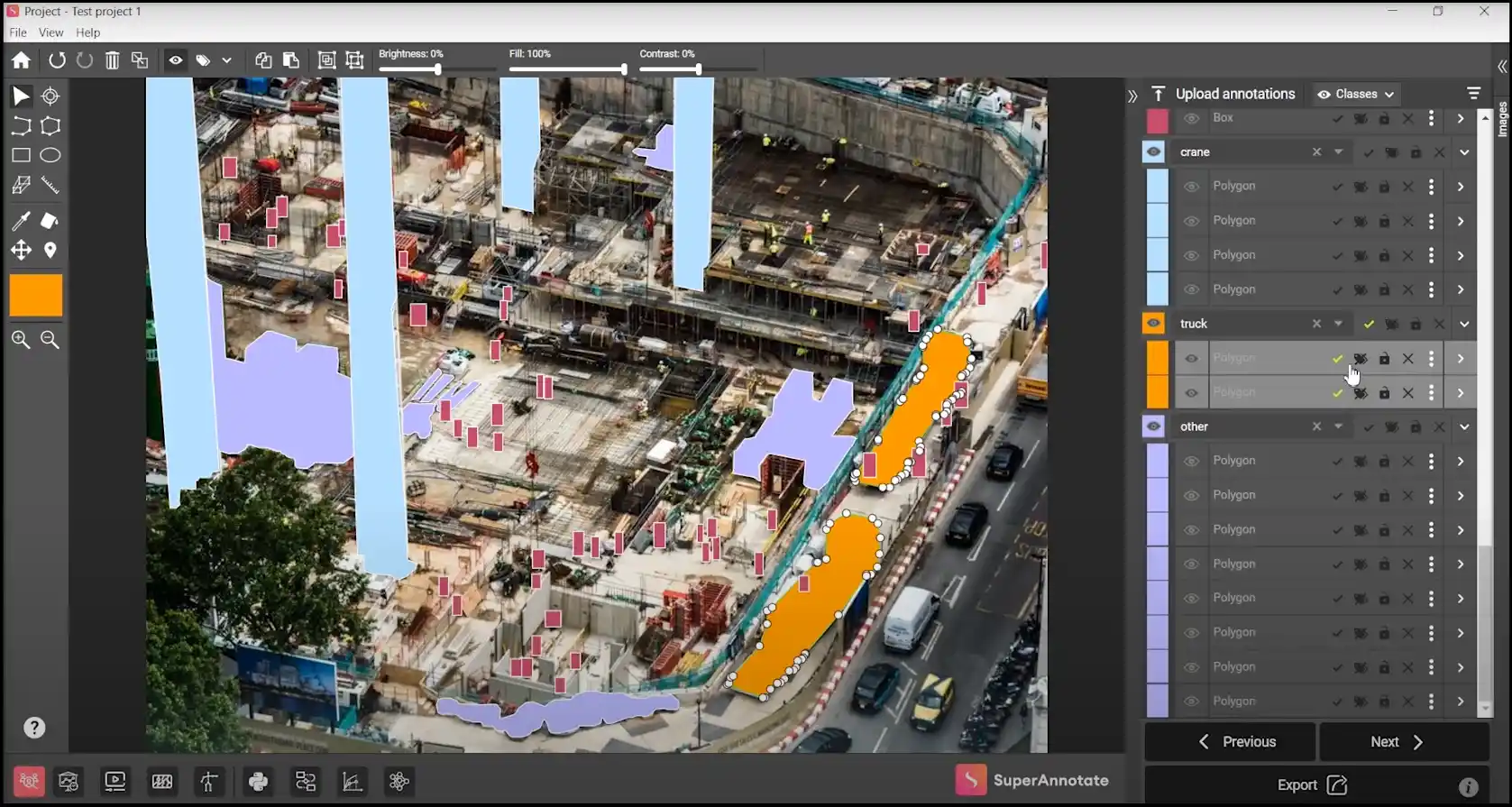
It provides a comprehensive suite for both 2D and 3D annotations and integrates AI-powered features to expedite the labeling process.
SuperAnnotate also offers a robust collaboration platform, allowing large teams to work together seamlessly on annotation tasks.
Top Features:
- 2D and 3D annotation capabilities
- AI-assisted labeling for faster results
- Integrated project management and collaboration tools
- Multi-format support (images, videos, LiDAR, etc.)
- Quality control and analytics features
Pros:
- Strong 3D annotation capabilities
- Excellent project management tools
- AI-driven automation speeds up workflows
- Scalable for larger teams
Cons:
- Can be expensive for small teams
- Learning curve for advanced features
Pricing:
- Free: Good for Academics and Researchers or early developing startup
- Pro: Contact Sales
- Enterprise: Contact Sales
G2 Reviews:
Users on G2 praise its 3D capabilities, intuitive design, and ability to manage complex projects efficiently.
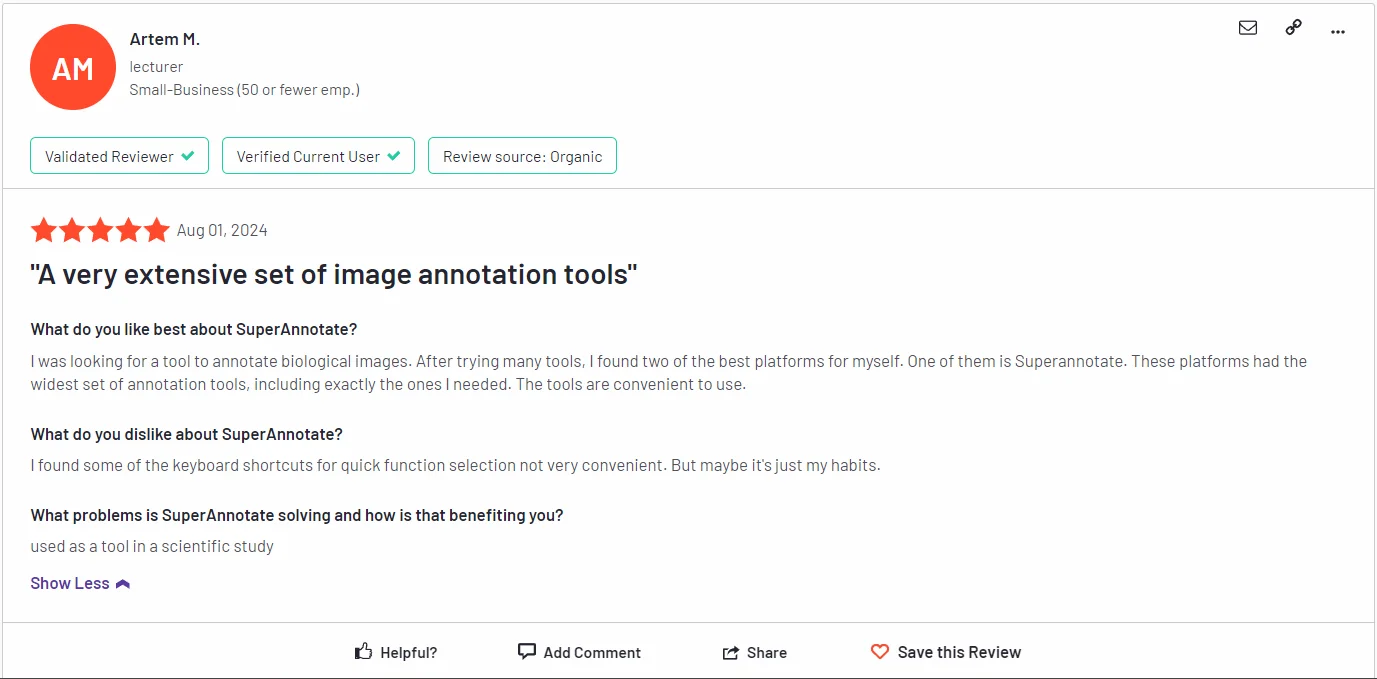
G2 review 4.9 out of 5. Check the detailed review here.
3. Labelbox
Introduction:
Labelbox is a popular data annotation platform, well-regarded for its robust workflow automation, collaboration features, and ability to manage large-scale datasets.
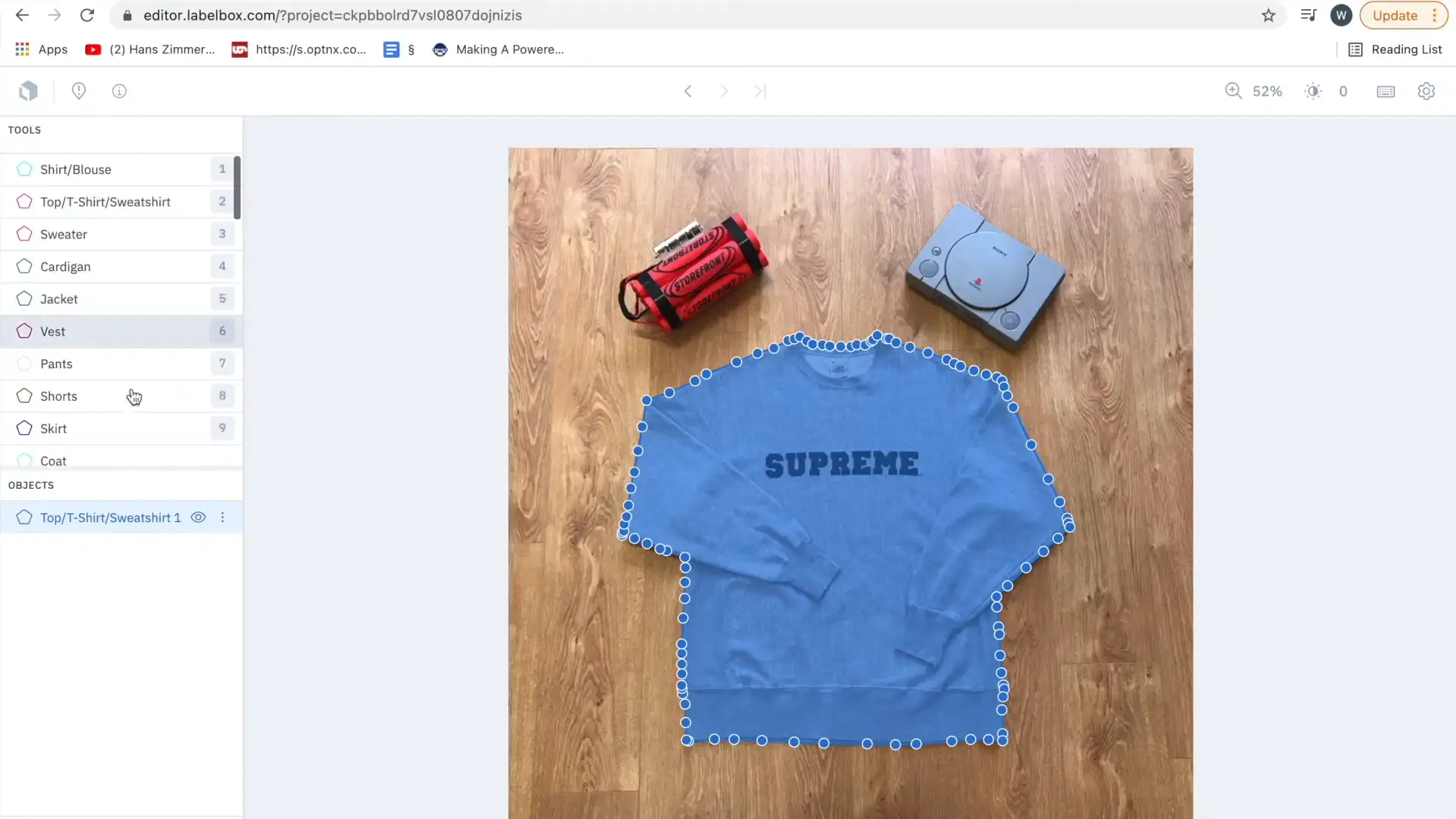
It supports a wide range of data types, making it ideal for teams working on various machine learning projects, including NLP and computer vision.
Top Features:
- Workflow automation
- Support for text, images, video, and more
- Quality assurance features
- Easy collaboration across teams
- API integrations for seamless workflow
Pros:
- Scalable and highly customizable
- User-friendly interface
- Advanced analytics and data management tools
Cons:
- Expensive for small teams
- Limited free features
Pricing:
- Free: 500 LabelBox Unit
- Starter: $0.10 per LabelBox Unit
- Enterprise: Contact Sales
G2 Reviews:
Highly rated for ease of use and customization options. Users appreciate the platform’s ability to handle large datasets efficiently.
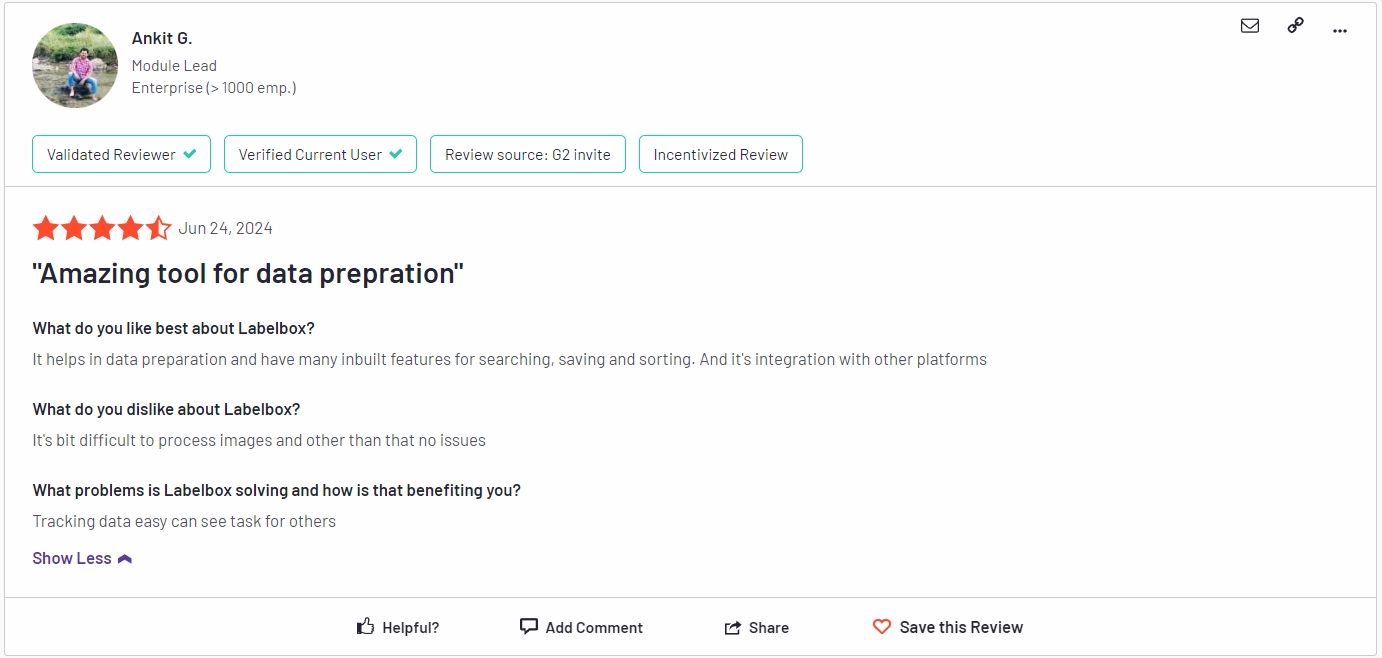
G2 review 4.7 out of 5. Check the detailed review here.
4. Scale AI
Scale AI is known for its high-quality annotation services for large datasets, particularly in industries like autonomous vehicles, e-commerce, and more.
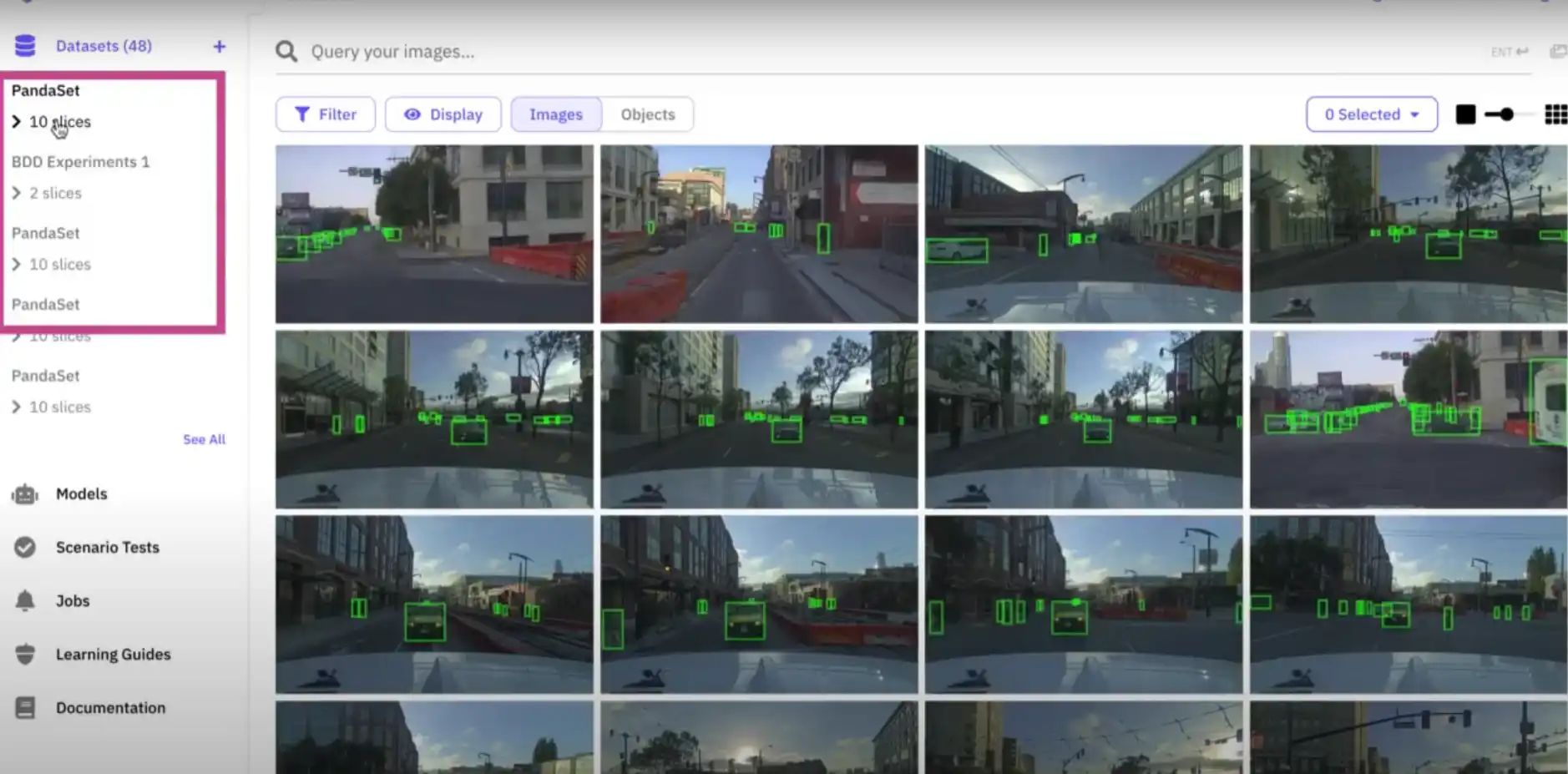
It combines human intelligence with machine learning to provide fast and accurate labeling. Scale AI has become a top choice for companies looking for data labeling at scale.
Top Features:
- Human-in-the-loop labeling for accuracy
- AI-assisted labeling for speed
- Robust API integration
- Supports various data formats
- Quality assurance at scale
Pros:
- Excellent for large datasets
- AI-driven quality control
- High accuracy
- Industry-specific solutions
Cons:
- Expensive for smaller companies
- Limited customization for specific tasks
Pricing:
- Free: $0 per month with 10k data volume.
- Team: $1500 per month with 200k data volume.
- Pro: $7500 per month with 2M data volume.
- Enterprise: Custom Pricing with Unlimited data volume.
G2 Reviews:
Praised for high-quality annotations and scalability. Some users mention the higher costs as a downside.
5. Dataloop
Dataloop is an AI-driven platform that integrates data annotation with model training pipelines, making it ideal for projects requiring real-time feedback.
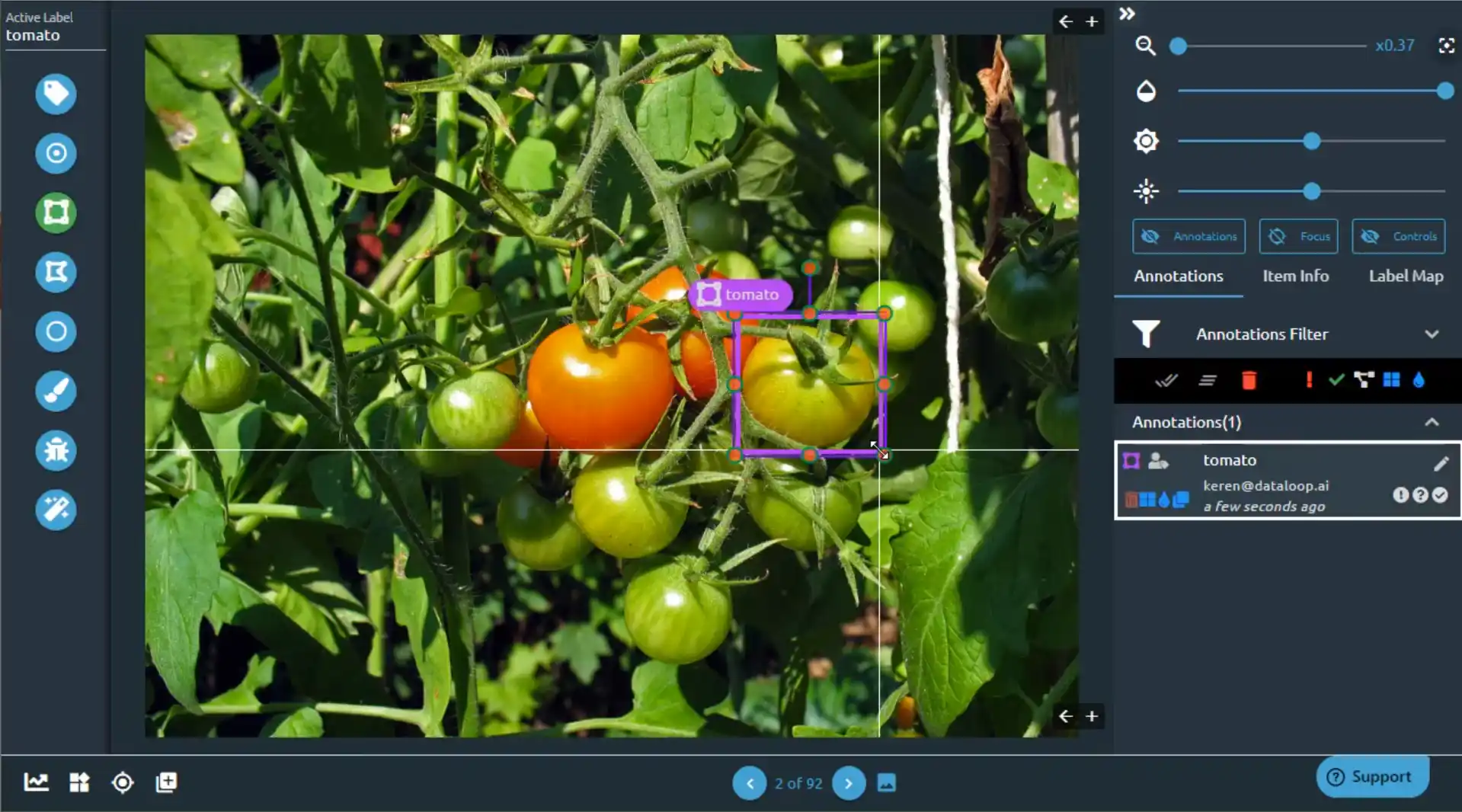
Its robust automation features, along with real-time collaboration tools, make it a preferred choice for teams looking to streamline their AI data workflows.
Top Features:
- End-to-end platform (annotation + model training)
- Real-time feedback and collaboration
- Automation tools for data labeling
- Support for multiple formats (images, videos, etc.)
- Quality control features
Pros:
- Seamless integration with AI models
- Real-time feedback loop
- Excellent automation features
- Highly customizable workflows
Cons:
- Expensive for small-scale projects
- Learning curve for new users
Pricing:
- Free Trial is available. Rest custom pricing is available based on project needs.
G2 Reviews:
Highly rated for automation features and real-time collaboration, though some users mention the pricing as a downside for smaller teams.
6. Amazon SageMaker Ground Truth
Amazon SageMaker Ground Truth is an enterprise-level tool for data labeling that combines machine learning models with human-in-the-loop workflows to deliver high-quality annotations.
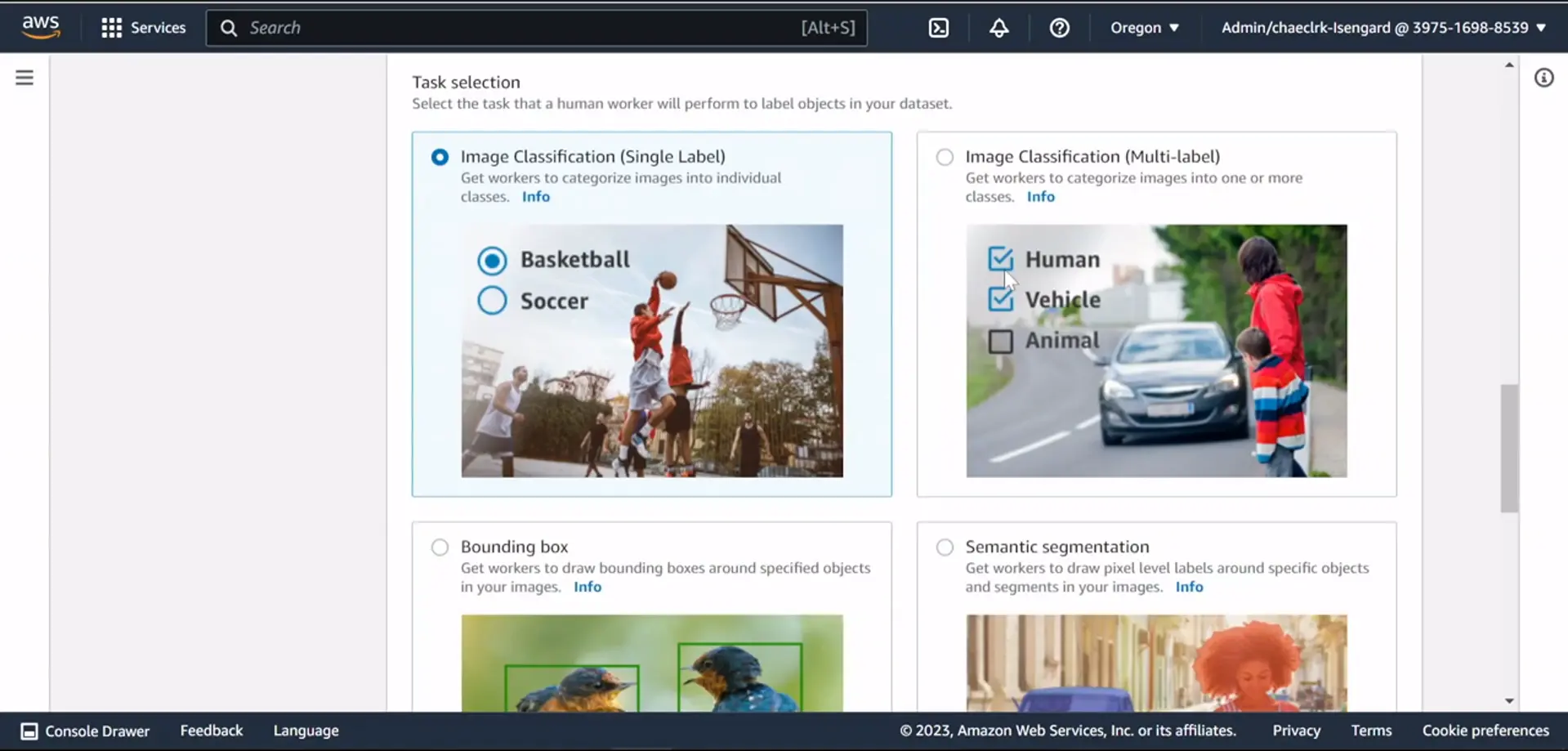
It offers pre-built workflows for labeling tasks and seamlessly integrates with the rest of the AWS ecosystem.
Top Features:
- Pre-built workflows for image and text labeling
- Human-in-the-loop for high accuracy
- Integration with AWS for seamless data management
- Scalable for large datasets
- Cost-effective through active learning
Pros:
- Strong integration with AWS services
- Pre-built workflows save time
- Scalable to enterprise levels
- High-quality annotations through active learning
Cons:
- AWS ecosystem can be overwhelming for beginners
- Limited features outside of AWS integration
Pricing:
- Pay-as-you-go pricing based on the volume of data labeled.
G2 Reviews:
Praised for its seamless AWS integration, but some users mention the complexity of setting up workflows outside of the AWS ecosystem.
G2 reviews 4.0 out of 5. Check the detailed review here.
7. CVAT (Computer Vision Annotation Tool)
CVAT is an open-source tool developed by Intel, primarily designed for computer vision tasks.
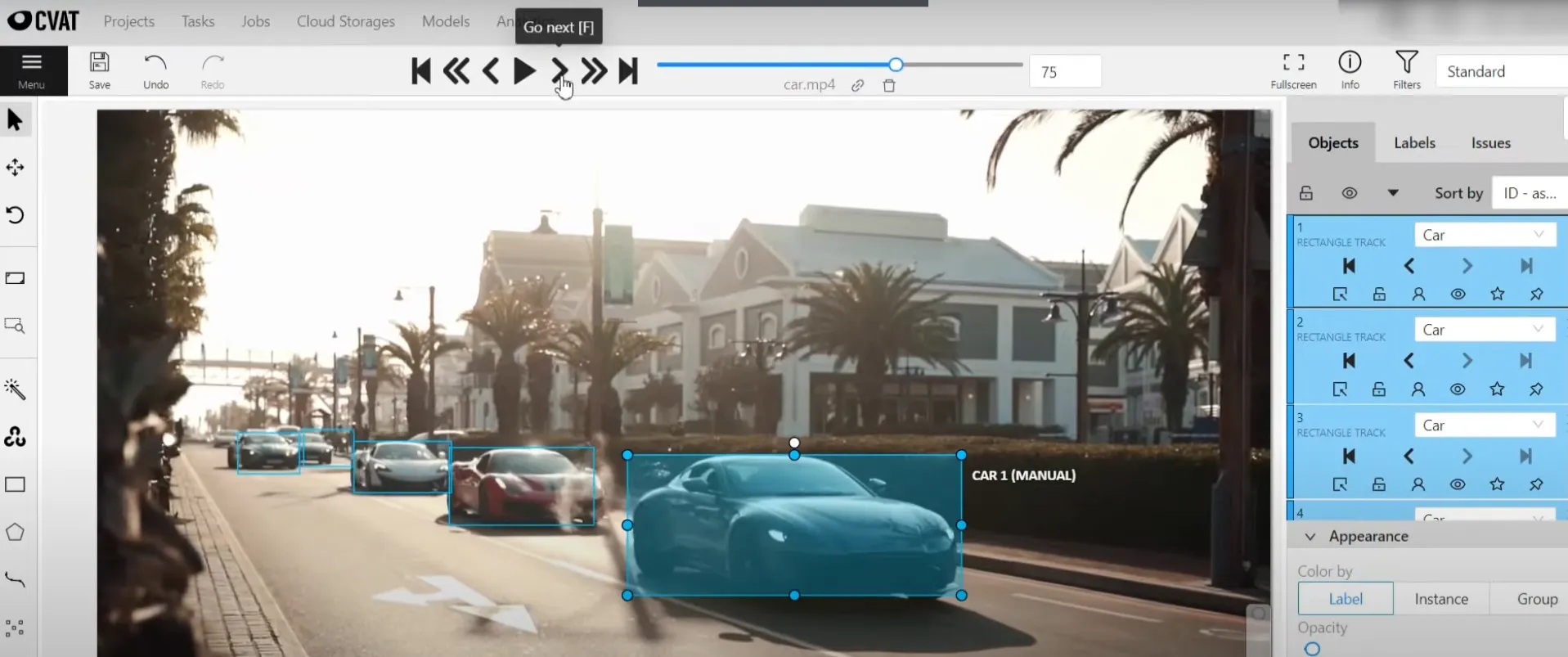
It supports a range of annotation types, including image and video segmentation, object detection, and more.
CVAT is widely used by teams looking for a free yet powerful solution for their data annotation needs.
Top Features:
- Open-source and free-to-use
- Supports image, video, and text annotations
- Multi-format support
- Advanced labeling tools for computer vision tasks
- Easy-to-use interface for beginners
Pros:
- Free and open-source
- Strong support for computer vision tasks
- Community-driven updates
- Flexible for different projects
Cons:
- Limited collaboration tools
- No built-in automation
Pricing:
- Free: Limited for personal use and small teams
- Solo: $33 Unlimited Professional Plan
- Team: $33 Per member of the organization.
G2 Reviews:
Users appreciate the flexibility and robust features of a free tool, though some mention the lack of automation as a limitation.
G2 reviews 4.5 out of 5. Check the detailed review here.
8. V7 Labs
V7 Labs is a data annotation platform that focuses on AI-assisted annotation for images and videos.
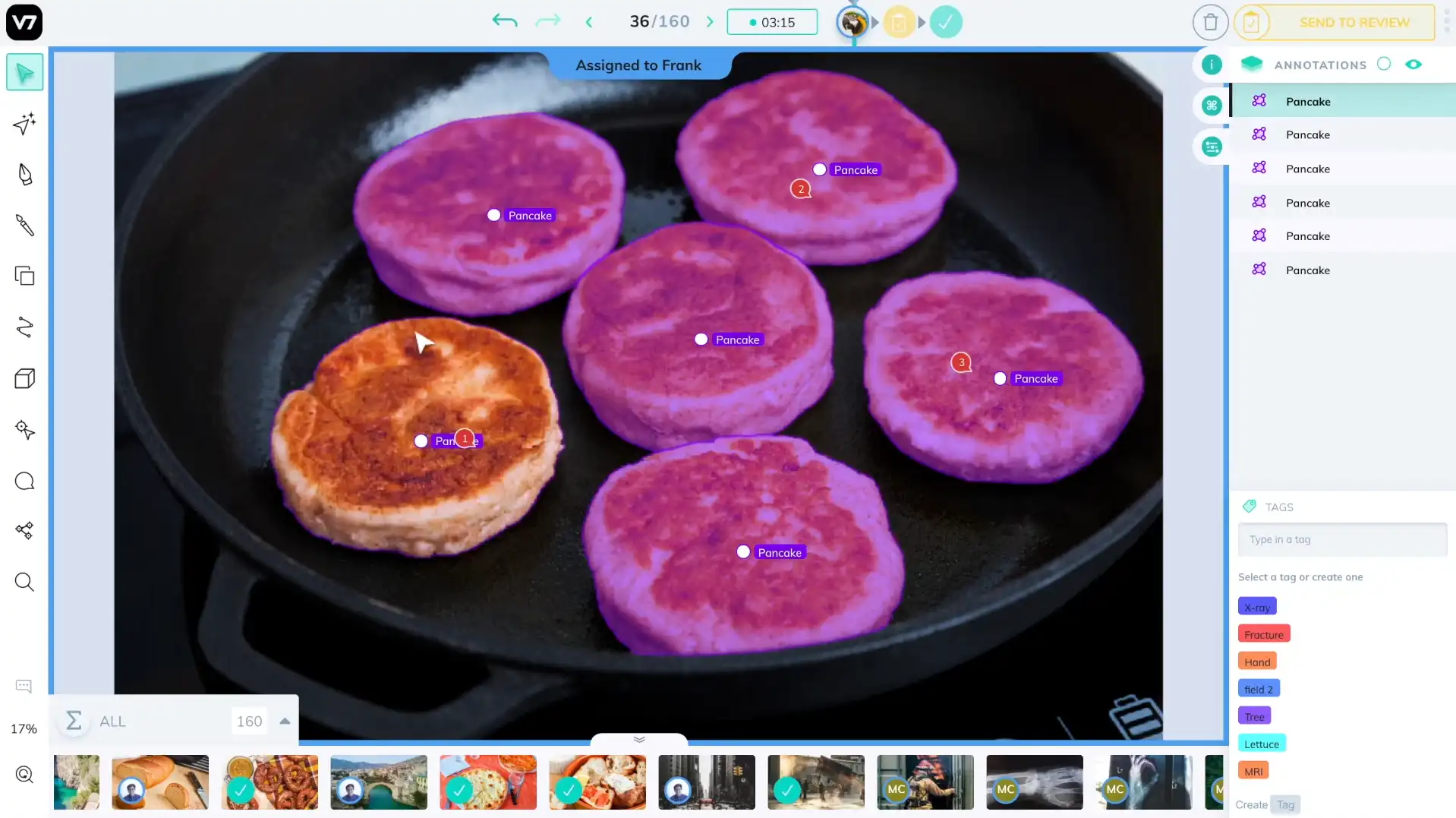
It uses deep learning models to automate the labeling process, which reduces time and effort for large-scale annotation projects.
V7 Labs is highly suited for video labeling tasks, with powerful tools for frame-by-frame analysis and a user-friendly interface to boost team collaboration.
Top Features:
- AI-assisted image and video labeling
- Support for real-time collaboration
- Frame-by-frame video annotation
- Pre-built models for automation
- Integration with model training pipelines
Pros:
- Excellent for video and image labeling
- AI-powered automation speeds up the process
- Seamless collaboration tools
- High-quality output for complex tasks
Cons:
- Limited customization options for niche projects
- Can be expensive for small teams
Pricing:
- Basic: You can use V7 for free with 1k files and 3 seats.
- Starter: $499/month for 50k files and 3 seats with 1 workspace.
- Business: Contact Sales with 1M files
- Pro: Contact Sales with 4M files
- Enterprise: Contact Sales with 10M+ files
G2 Reviews:
Users praise V7 Labs for its powerful video annotation tools and real-time collaboration, though some find the pricing steep for smaller projects.
G2 reviews 4.8 out of 5. Check the detailed review here.
9. Hive Data
Hive Data offers AI-driven data labeling services, catering to a wide range of industries including autonomous vehicles, healthcare, and retail.
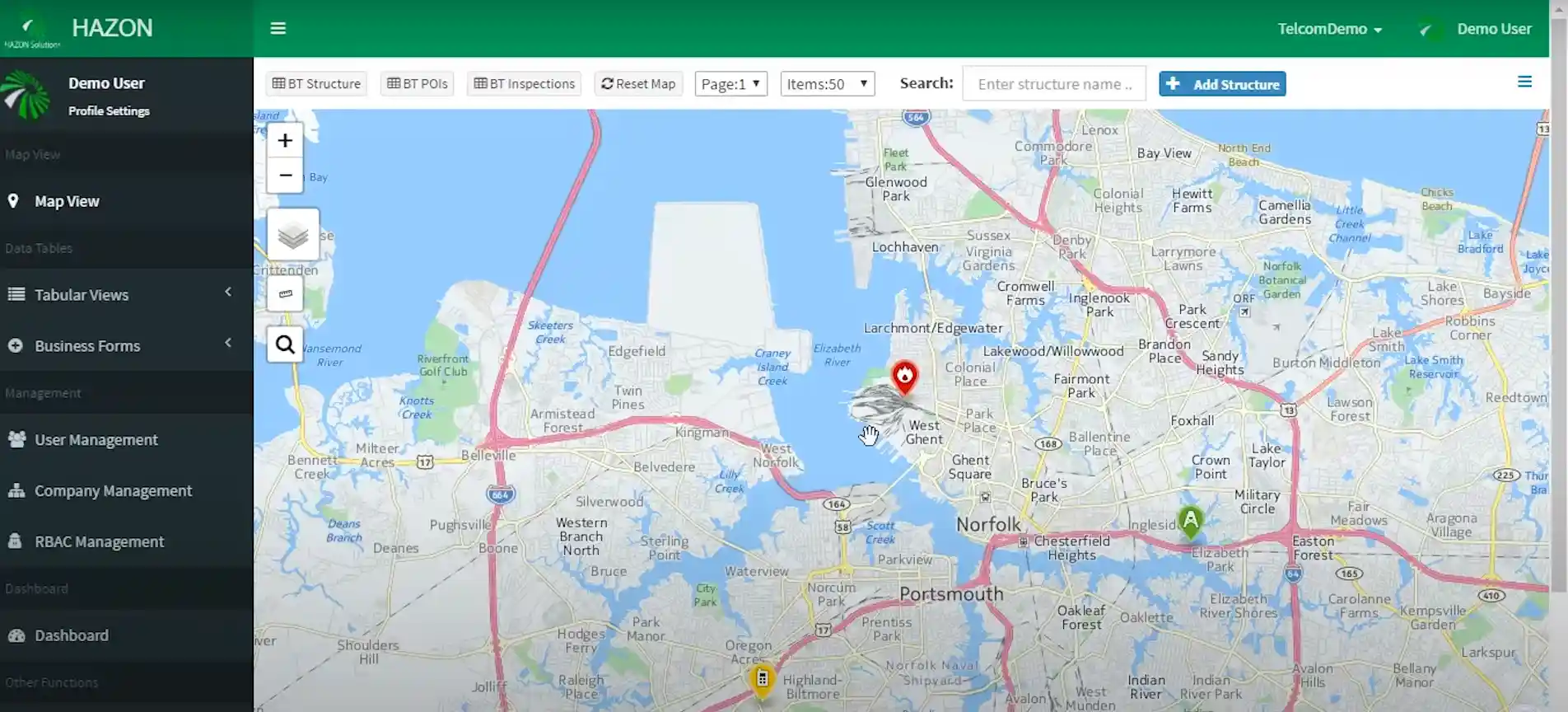
The platform uses a combination of human intelligence and machine learning to deliver highly accurate annotations.
Hive’s AI models are fine-tuned to continuously improve with each labeling task, ensuring consistent accuracy and performance.
Top Features:
- AI-driven data labeling
- Human-in-the-loop model for better accuracy
- Custom models for different industries
- Quality assurance and control
- Support for multiple data formats
Pros:
- Strong AI-assisted labeling
- Industry-specific custom models
- Consistent accuracy with scalable solutions
- High-quality human-in-the-loop approach
Cons:
- Not ideal for smaller datasets
- Limited customization for niche applications
Pricing:
- Free: No monthly cost
- Starter: $1 per user per month
- Teams: $3 per user per month
- Enterprise: Contact Sales
G2 Reviews:
Hive Data is praised for its high accuracy and scalability, though some users mention that it’s not the best fit for smaller teams or datasets.
10. Diffgram
Diffgram is a full-stack platform designed for AI and data science teams. It provides tools for data annotation, model training, and evaluation, creating a unified platform for managing machine learning projects.
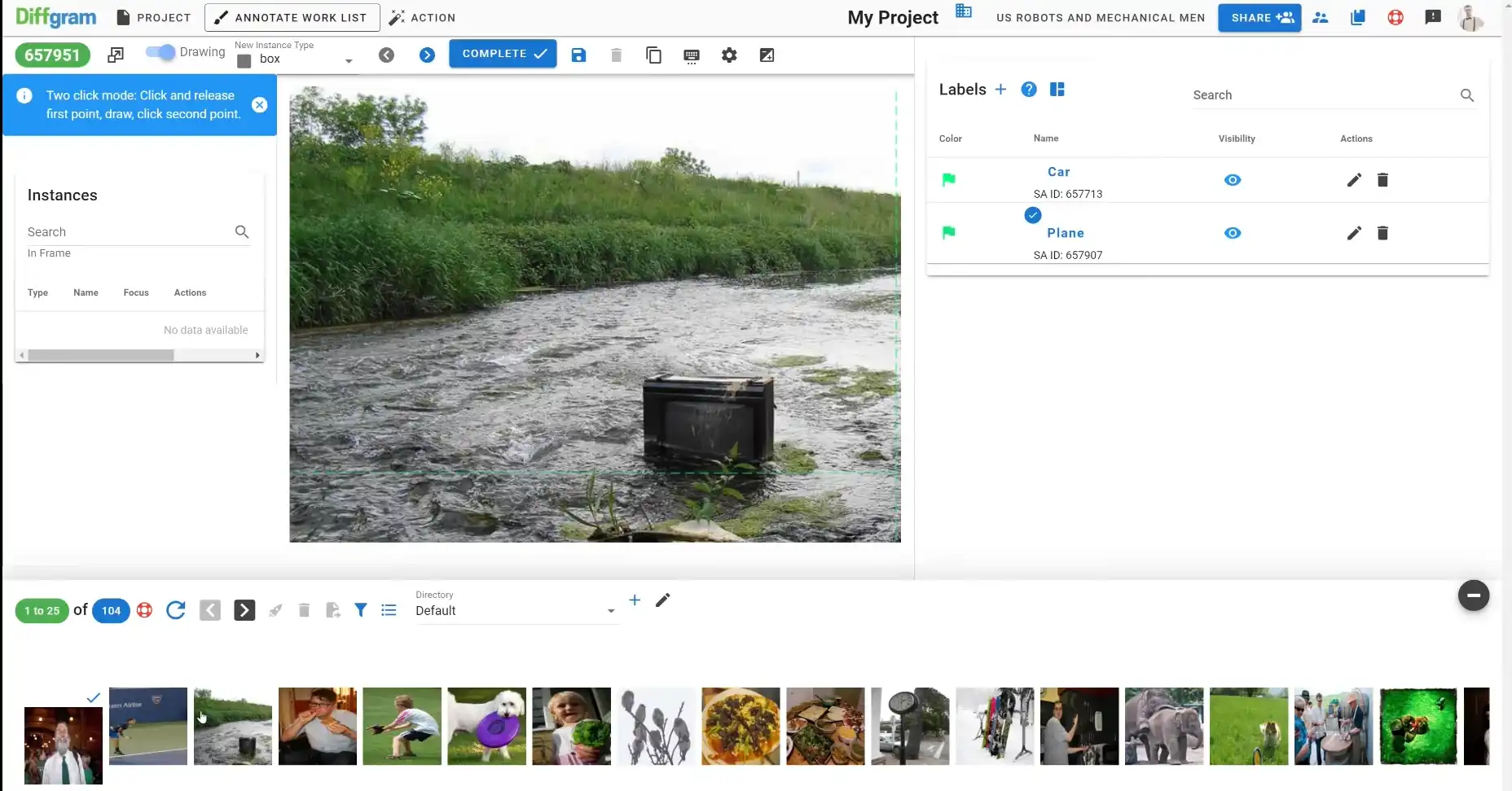
Diffgram is particularly suited for teams working with both small-scale and large-scale datasets, offering flexibility and robust customization features to fit various project needs.
Top Features:
- Full-stack platform (annotation, training, and evaluation)
- Automation tools for faster labeling
- Supports images, video, and text data
- Real-time collaboration and feedback
- Custom workflows for specific project needs
Pros:
- Integrated platform for end-to-end AI workflows
- Highly customizable
- Flexible for both small and large datasets
- Strong collaboration tools
Cons:
- Steeper learning curve for new users
- Some features are limited in the free version
Pricing:
- Offers a free tier with limited features.
- Enterprise pricing is custom based on project size.
G2 Reviews:
Users appreciate Diffgram’s full-stack approach and flexibility, but some mention the initial setup and learning curve can be challenging for beginners.
11. Clarifai
Clarifai provides AI-powered tools for image, video, and text labeling, with a focus on custom model training and deployment.
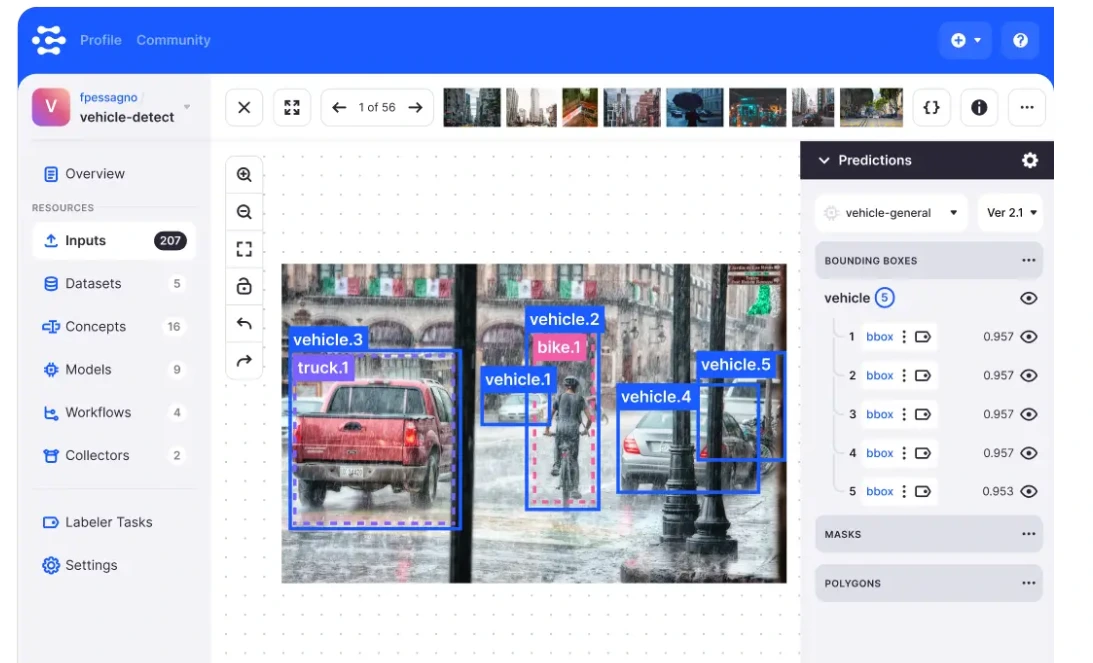
It offers a complete AI lifecycle management system, enabling teams to build, label, and train models within a single platform.
Clarifai is ideal for teams that need a robust solution for both labeling and model deployment.
Top Features:
- AI lifecycle management (build, label, train)
- Custom models for specific industries
- Supports image, video, and text data
- Automated labeling using pre-trained models
- Integration with external platforms
Pros:
- End-to-end solution for AI workflows
- Powerful AI model training tools
- Strong automation features
- Highly scalable
Cons:
- Complex pricing structure
- Limited customization outside its ecosystem
Pricing:
- Community version is Free.
- Essential version is $30/month.
- Professional version is $300/month.
G2 Reviews:
Users praise Clarifai for its AI model training capabilities and robust automation features, though some find the pricing model challenging to navigate.
G2 Review : 4.3/5 (link to customer reviews).
12. DataTurks
DataTurks is a collaborative platform designed for labeling text, images, and videos.
It supports a wide range of annotation types, including NLP, computer vision, and more.
DataTurks emphasizes ease of use and is a popular choice for small and medium-sized teams looking for affordable annotation tools without sacrificing functionality.
Top Features:
- Support for text, image, and video annotation
- Collaborative platform with real-time feedback
- NLP-specific annotation features
- Easy-to-use interface
- API integrations for streamlined workflows
Pros:
- Affordable pricing
- Ideal for small to medium-sized teams
- Strong support for NLP tasks
- Simple and intuitive design
Cons:
- Limited scalability for enterprise-level projects
- Lacks some advanced features found in more expensive tools
Pricing:
- Offers free access for small projects.
- Paid plans start at $30/month.
G2 Reviews:
Users appreciate DataTurks for its simplicity and affordability, especially for NLP tasks, though larger teams find it lacking in advanced features.
13. Appen
Appen is a leading provider of human-annotated datasets, specializing in crowdsourcing large-scale data labeling for machine learning projects.

It offers a diverse range of services, including text, image, video, and audio labeling. Appen is particularly known for its ability to handle complex, high-volume tasks with the help of a global workforce.
Top Features:
- Large-scale crowdsourced data labeling
- Supports text, image, video, and audio
- Customizable workflows for specific needs
- High-quality annotations from trained professionals
- Scalability for enterprise-level projects
Pros:
- Excellent for large-scale projects
- Global workforce ensures high-quality annotations
- Custom workflows for different industries
- Wide range of supported data types
Cons:
- Expensive for smaller teams
- Crowdsourced model may have longer turnaround times
Pricing:
- Custom pricing based on project scope and data volume.
G2 Reviews:
Appen is praised for its scalability and ability to handle complex tasks, but some users note that the crowdsourced model may lead to longer project completion times.
14. Playment
Playment is a data labeling platform that specializes in annotation for autonomous systems, such as autonomous vehicles and drones.
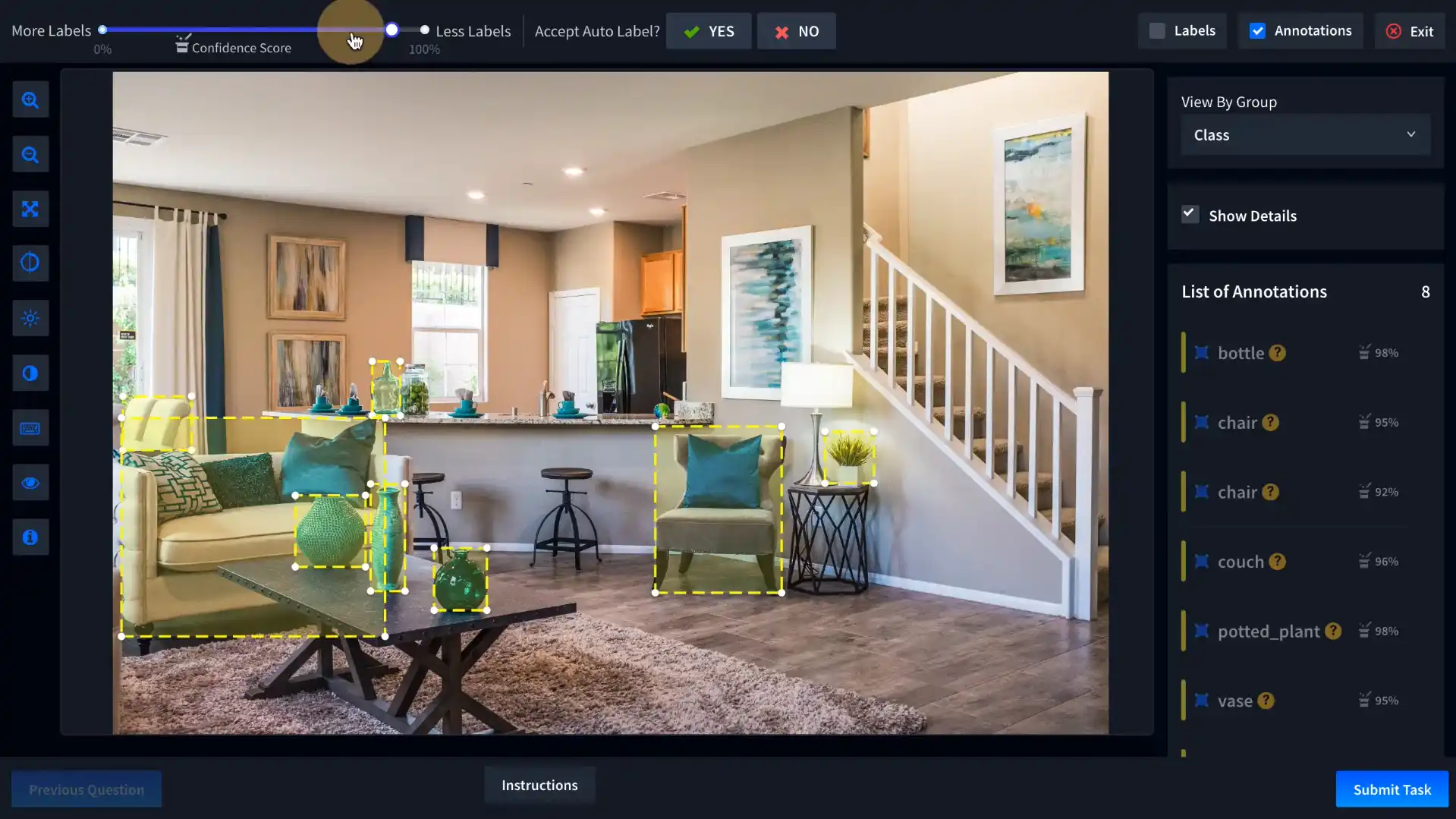
It offers a robust set of tools for complex 3D and 2D annotation tasks, including LiDAR and video annotations.
Playment’s services are highly customizable, making it a top choice for industries working with autonomous technologies.
Top Features:
- Specialized tools for 2D and 3D annotations
- LiDAR and video annotation support
- High-quality quality assurance processes
- AI-assisted labeling for speed and accuracy
- Custom workflows for autonomous systems
Pros:
- Excellent for complex 3D and LiDAR annotations
- Strong quality control features
- Custom workflows tailored to specific industries
- High-quality output for autonomous projects
Cons:
- Expensive for small-scale projects
- Complex setup for non-autonomous tasks
Pricing:
- Custom pricing based on project needs.
G2 Reviews:
Highly rated for its LiDAR and 3D annotation tools, though users mention that the pricing can be steep for non-autonomous projects.
15. Mighty AI (acquired by Uber)
Mighty AI was known for its high-quality annotations, particularly for autonomous driving datasets.
After being acquired by Uber, the platform has continued to be a key player in the autonomous vehicle industry, providing accurate data labeling services for computer vision tasks, including object detection, segmentation, and more.
Top Features:
- Specialized in autonomous driving datasets
- High-quality object detection and segmentation
- Human-in-the-loop for improved accuracy
- Custom workflows for large datasets
- Strong quality control processes
Pros:
- Industry leader for autonomous vehicle datasets
- High accuracy
- Scalable for large projects
- Human-in-the-loop ensures quality control
Cons:
- Limited to autonomous driving and similar industries
- Pricing not suited for small teams
Pricing:
- Custom pricing based on project scope.
G2 Reviews:
Praised for its accuracy and focus on autonomous vehicles, though some users note its limitations in other industries.
Benefits of Using Data Labeling Tools in AI
Data labeling tools play a crucial role in streamlining the development of AI and machine learning models.
By using these tools, organizations can efficiently and accurately annotate vast amounts of data, which is essential for training models to make precise predictions.
Below are the key benefits of using data labeling tools in AI.
Improved Efficiency and Accuracy
1. Automated labeling:
- Data labeling tools often come equipped with AI-powered features like pre-labeling and auto-annotation.
These features use machine learning algorithms to predict labels for data points, significantly reducing the manual effort required in the annotation process. - This automation not only speeds up the labeling process but also minimizes the chances of human errors, ensuring consistent and accurate annotations.
2. Precision in Data Annotations:
- High-quality data labeling is critical for training AI models to perform well.
Tools that offer features like bounding boxes, segmentation masks, and key point annotations help ensure that every aspect of the data is labeled with precision. - This precision directly impacts the performance of machine learning models, leading to higher accuracy in predictions and better outcomes.
3. Error Detection and Correction:
- Many data labeling tools include built-in mechanisms to identify and correct labeling errors.
They might flag inconsistencies in annotations or provide suggestions for rectifying mistakes. - This feature helps maintain a high standard of data quality, which is crucial for building reliable AI systems.
Scalability for Large Projects
1. Handling Massive Datasets:
- AI projects often require large datasets to train robust models. Data labeling tools are designed to handle these large-scale annotation tasks efficiently, allowing teams to work on thousands or even millions of data points simultaneously.
- These tools are built to manage extensive datasets without compromising on speed or accuracy, making them ideal for enterprises developing large AI and machine learning models.
2. Flexible Workflow Management:
- Data labeling tools typically offer workflow management capabilities that allow teams to break down large projects into smaller tasks.
This approach helps in distributing the workload among multiple team members or even across different teams. - Tools with such features provide a structured way to manage and track the progress of data labeling, ensuring that even the most complex projects are completed on time.
3. Cloud-Based and On-Premise Solutions:
- Many data labeling tools offer both cloud-based and on-premise options to cater to the needs of organizations.
Cloud-based solutions provide the flexibility to scale up or down depending on the project's size, while on-premise solutions offer greater control over data security. - This scalability ensures that businesses of all sizes, from startups to large enterprises, can find a data labeling tool that fits their requirements.
Enhanced Collaboration and Quality Control
1. Team-Based Annotation:
- Data labeling tools often include features that promote collaborative work, such as role-based access controls, task assignments, and real-time feedback.
These features enable multiple annotators to work together seamlessly on the same project. - Collaboration tools ensure that team members can easily communicate, share feedback, and make adjustments to annotations, leading to faster project completion and higher-quality results.
2. Integrated Quality Assurance Mechanisms:
- Quality control is a critical aspect of data labeling. Many tools incorporate review and validation stages in the annotation workflow to ensure that labeled data meets the required standards.
- These quality assurance mechanisms might include peer reviews, automated checks, and analytics to identify discrepancies or inconsistencies in the labeled data.
3. Version Control and Audit Trails:
- Some advanced data labeling tools offer version control and audit trail features that track every change made during the annotation process.
This transparency allows teams to review the history of modifications, making it easier to identify errors and revert to previous versions if needed. - Such features are particularly useful in maintaining data integrity and ensuring that the labeled datasets are reliable and error-free.
Common Challenges in Data Labeling and How to Overcome Them
Data labeling is a fundamental part of AI and machine learning development, but it also comes with several challenges that can affect the accuracy, efficiency, and overall success of AI projects.
Understanding these challenges and knowing how to address them is crucial for developing reliable AI models.
Below, we explore some of the most common challenges in data labeling and how to overcome them.
Data Privacy and Security Concerns
Challenge: Protecting Sensitive Information
- Data labeling often involves sensitive information, especially in domains like healthcare, finance, and security.
Annotating this data without proper safeguards can lead to breaches of confidentiality and data misuse. - Privacy regulations like GDPR, HIPAA, and CCPA impose strict requirements on how data can be collected, stored, and shared, making it essential to handle data securely during the labeling process.
Solution: Data Anonymization and Encryption
- Data Anonymization: Before labeling begins, sensitive data should be anonymized to protect individual identities.
Removing personally identifiable information (PII) ensures that the data cannot be traced back to specific individuals. - Encryption Techniques: Encrypting data during storage and transfer adds an extra layer of security, ensuring that even if unauthorized access occurs, the data remains unintelligible.
Solution: Using Secure Data labeling Platforms
- Choose data labeling tools that comply with industry standards for data security and offer secure environments for annotation.
Platforms with built-in privacy features, access controls, and compliance certifications are essential for protecting sensitive data. - Cloud-based data labeling tools should provide end-to-end encryption and secure connections (SSL/TLS) to prevent data leaks during the annotation process.
Reducing Bias in Annotations
Challenge: Annotator Bias
- Human biases can significantly influence the quality of labeled data, leading to biased machine learning models.
Differences in annotators' cultural backgrounds, perspectives, or experiences can result in inconsistent labels and skewed datasets. - Bias in data labeling can propagate into AI models, affecting their fairness and decision-making accuracy, especially in sensitive applications like hiring, healthcare, or criminal justice.
Solution: Diverse Annotation Teams
- Building a diverse team of annotators helps to minimize bias by incorporating a range of perspectives during the labeling process.
Diverse teams are more likely to provide balanced and comprehensive annotations, reducing the risk of systematic biases. - Conducting bias training for annotators to raise awareness about unconscious biases and providing guidelines on how to maintain objectivity can also improve labeling accuracy.
Solution: Consensus-based labeling
- Implement a consensus-based approach where multiple annotators label the same data points and a final decision is reached based on majority agreement.
This method reduces the influence of individual biases and leads to more consistent annotations. - Using AI-driven tools to flag inconsistencies or disagreements among annotators can also help identify potential biases early in the labeling process.
Addressing High Costs in Manual Labeling
Challenge: Expensive and Time-Consuming Process
- Manual data labeling is labor-intensive and costly, especially for large datasets required in training complex AI models.
The need for skilled annotators, quality control, and extensive time investment can drive up project costs. - For small businesses or startups, the cost of manual data labeling can be a significant barrier to entry in AI and machine learning development.
Solution: Leveraging AI-Powered Annotation Tools
- To reduce the dependency on manual labor, consider using AI-powered data labeling tools that offer features like auto-annotation and machine-assisted labeling.
These tools use machine learning algorithms to pre-label data, requiring less manual effort. - Automation not only speeds up the labeling process but also helps reduce costs by minimizing the number of human resources required for annotation tasks.
Solution: Outsourcing and Crowdsourcing
- Outsourcing data labeling tasks to specialized service providers or crowdsourcing platforms can be a cost-effective solution.
These platforms provide access to large pools of annotators at competitive rates, making it easier to scale labeling operations without incurring high costs. - Crowdsourcing allows businesses to tap into a global workforce, ensuring faster turnaround times and reduced costs compared to in-house labeling efforts.
Why Pick Labellerr for Data Labeling?
- Labellerr makes data labeling easy and fast.
- You can label images, text, and videos in one place.
- AI features help you finish tasks quickly and with fewer mistakes.
- Work with the team in real time.
- Your data stays safe and private.
- Labellerr grows with your project, big or small.
Try Labellerr if you want a simple, smart, and secure labeling tool.
How has Labellerr helped teams develop Robust AI?
Transforming a Maritime Startup's Training Data Pipeline
Case Study:
One of our client specializing in autonomous vehicle technology faced challenges with their image annotation process due to the vast amounts of data needed to train their AI models.
Traditional manual methods were slow and prone to errors. They required a scalable solution that could automate parts of the annotation workflow while maintaining high accuracy.
Solution:
Labellerr’s AI-powered image annotation tool provided the team with the automation capabilities they needed.
The platform’s customizable workflows, AI-assisted annotations, and multi-format support streamlined the labeling process, allowing Mythos AI to handle large datasets more efficiently.
The integration of quality control workflows ensured high annotation accuracy, while real-time collaboration improved team productivity.
Outcome:
The team experienced a 40% increase in labeling speed and a significant reduction in manual errors.
The use of Labellerr’s platform helped the company meet project deadlines faster, contributing to quicker iterations in model training and development for their autonomous vehicle projects.
Choosing the Right Data Labeling Tool for Sports Visual Analytics
Case Study:
A sports analytics company focused on visual analytics for performance evaluation struggled with the complexity and volume of sports footage.
The company needed a data labeling tool capable of annotating video data for movement tracking, object detection, and event classification in real-time sports scenarios.
Solution:
Labellerr provided a comprehensive data labeling solution tailored to the specific needs of sports visual analytics.
With AI-assisted labeling for high-volume video data, the platform enabled the company to track players, annotate events like goals or fouls, and classify object types in a fraction of the time required by manual processes.
The collaboration tools allowed multiple analysts to work simultaneously, speeding up the labeling process.
Outcome:
The sports analytics firm improved its data labeling efficiency by 30%, significantly speeding up analysis for team performance insights.
Labellerr’s automated features helped the company deliver faster, more accurate analytics to clients, offering a competitive edge in the fast-paced world of sports technology.
Revolutionizing Waste Segmentation with Labellerr
Case Study:
Another client, focused on waste management, faced difficulties in accurately labeling waste segmentation data for their AI-based sorting models.
The diverse nature of waste, including different shapes, sizes, and materials, made manual labeling time-consuming and inefficient.
They required a robust tool to streamline the labeling process for better segmentation accuracy.
Solution:
Labellerr stepped in to provide an AI-driven annotation platform that automated the process of waste segmentation.
The tool’s ability to handle multi-class labeling allowed Spare-it to classify various waste types with precision.
AI-powered suggestions reduced the manual effort required for labeling each waste item, while custom workflows improved the efficiency of the entire process.
Outcome:
Spare-it saw a 50% reduction in time spent on data labeling, with an increase in segmentation accuracy.
This allowed them to train their sorting models faster and more effectively, which in turn improved their AI’s performance in real-world waste sorting applications.
The automation provided by Labellerr played a critical role in scaling their waste management solution.
FAQs
1. What is data labeling in machine learning?
Data labeling involves annotating or tagging datasets to help machine learning models learn from the data. It’s essential for supervised learning tasks, where labeled data is used to train algorithms.
2. Why is data labeling important?
Data labeling improves the accuracy and performance of machine learning models by providing context and information. Properly labeled data helps models understand patterns and make predictions.
3. Are these tools suitable for all industries?
Most tools are versatile and can be adapted for various industries, including healthcare, automotive, finance, and retail. However, some tools may have features tailored for specific use cases.
4. Do I need technical expertise to use these tools?
While many tools are designed to be user-friendly, some may require technical knowledge or training, especially those with advanced features or customizations.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
