

ViNT Model Is Here, Let's See What It Can Do
The Visual Navigation Transformer (ViNT) is a foundation model for vision-based robotic navigation. Pre-trained on vast datasets, ViNT adapts to diverse robots and novel tasks via fine-tuning. Explore its architecture, zero-shot generalization capabilities, and limitations in mobile robotics.


Table of Contents
Introduction
General-purpose pre-trained models, often referred to as "foundation models," have enabled the development of adaptable solutions for specific machine learning problems using smaller datasets compared to starting from scratch.
These models are typically trained on large and diverse datasets with minimal supervision, requiring significantly more training data than is available for any individual downstream application.
The introduced model, the Visual Navigation Transformer (ViNT), aims to extend the success of general-purpose pre-trained models to the domain of vision-based robotic navigation.
ViNT undergoes training on several existing navigation datasets, comprising hundreds of hours of robotic navigation experiences across various robotic platforms. ViNT demonstrates positive transfer learning, impressively outperforming specialized models trained on narrower datasets.
ViNT can be enhanced by integrating diffusion-based goal proposals to explore novel environments and can effectively solve kilometer-scale navigation challenges when equipped with long-range heuristics.
Additionally, ViNT can be tailored to novel task specifications using a technique inspired by prompt-tuning, where the goal encoder is replaced with an encoding of another task modality, such as GPS waypoints or turn-by-turn directions, embedded into the same space of goal tokens. This flexibility and adaptability establish ViNT as an effective foundation model for mobile robotics.
Model Architecture
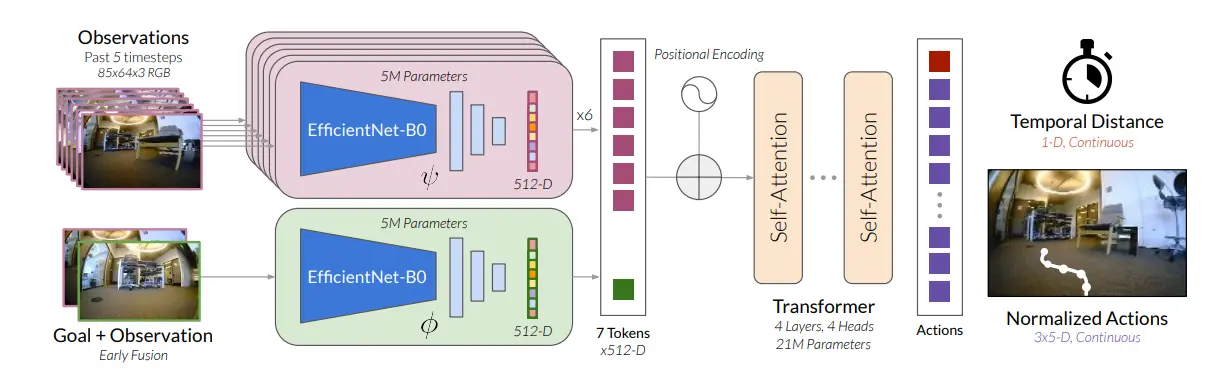
Figure: Model Architecture
ViNT utilizes a combination of two EfficientNet encoders denoted as ψ and ϕ to produce input tokens for a Transformer decoder.
The resultant sequence is merged and then transmitted through a fully connected network to make predictions regarding the (temporal) distance to the destination, along with a sequence of H = 5 forthcoming actions.
ViNT: A Foundation Model For Downstream Tasks
ViNT, originally designed for image goal-conditioned tasks, demonstrates its adaptability for various other tasks through fine-tuning in new environments or with different data modalities.
While its core function involves navigating to image goals, ViNT's strong navigational knowledge can be extended to broader applications.
Prior research explored the concept of sampling subgoals in a latent space. However, implementing this idea within ViNT's framework faced optimization difficulties and yielded suboptimal performance.
ViNT's Adaptation Techniques
ViNT's adaptability is showcased through several techniques. First, full model fine-tuning allows it to acquire new skills quickly and excel in different environments and robot embodiments with minimal on-task data, eliminating the need for retraining from scratch.
ViNT demonstrates successful long-distance navigation in both indoor and outdoor settings, achieving various goals along the way.
In the visual representations, you can see sample paths from the starting point (marked in orange) to the destination (marked in green).

Figure: ViNT accomplishes long-horizon navigation with a variety of objectives in indoor and outdoor environments; example trajectories between start (orange) and goal (green) are visualized here.
It employs a goal-oriented strategy to reach specific objectives, which can be further enhanced with satellite imagery if desired. Alternatively, when the goal-oriented strategy is removed, ViNT engages in open-ended exploration, effectively covering a workspace to its fullest extent.
Additionally, ViNT can easily adjust to other common goal specifications by learning a "soft prompt" mapping from the desired goal modality to ViNT's goal token. This adaptation leverages the Transformer architecture's capability to process multimodal inputs projected into a shared token space.
By training a neural network to map subgoals in new modalities to this shared space, ViNT can be fine-tuned with on-task data, facilitating its transition to new tasks while harnessing its performance and generalization capabilities.
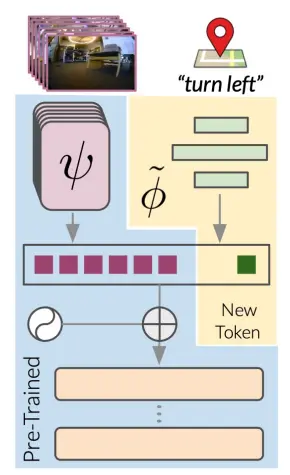
Figure: Adapting ViNT to different goals using a new tunable goal token.
Model Evaluation
To evaluate the model, 3 different criteria or questions were to be answered, which included:
- Can ViNT efficiently explore previously unseen environments and incorporate heuristics?
- Does ViNT generalize to novel robots, environments, and obstacles?
- Can ViNT be fine-tuned to improve performance in out-of-distribution environments?
Unseen environments and Incorporate Heuristics
The qualitative assessment demonstrates that when planning with the various subgoals suggested by diffusion, it results in more streamlined routes, whereas alternative baseline methods tend to follow convoluted paths during exploration. This can become clear from the below figure.
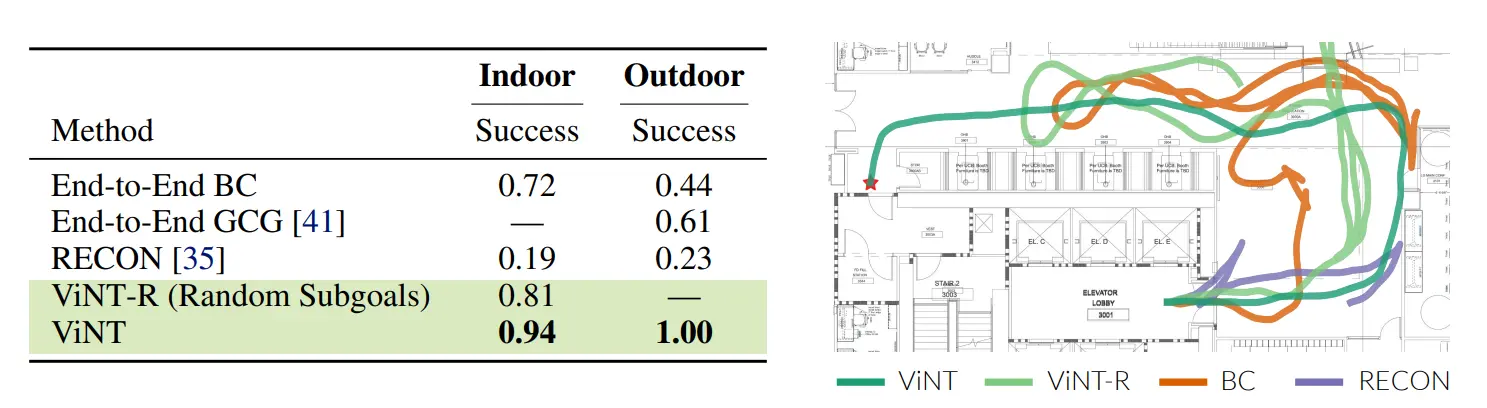
Figure: Comparison of ViNT with other baseline models
ViNT consistently demonstrates superior performance compared to the baseline methods in unguided goal-reaching within indoor and outdoor settings, as depicted on the left. ViNT's effectiveness in devising plans based on the proposals of diffusion subgoals allows it to navigate toward the goal efficiently.
In contrast, other baseline methods encounter challenges when it comes to exploring extensive indoor environments, as illustrated by the overlaid trajectories on an indoor floor plan on the right.
Zero-Shot Generalization: a Single Policy to Drive Any Robot
ViNT policy was deployed across four robotic platforms to measure Zero-shot Capabilities, abstaining from any task-specific fine-tuning. They documented the maximum displacement of each robot (measured in meters) from its initial location, representing the capability to reach distant objectives in intricate environments, as outlined below figure.
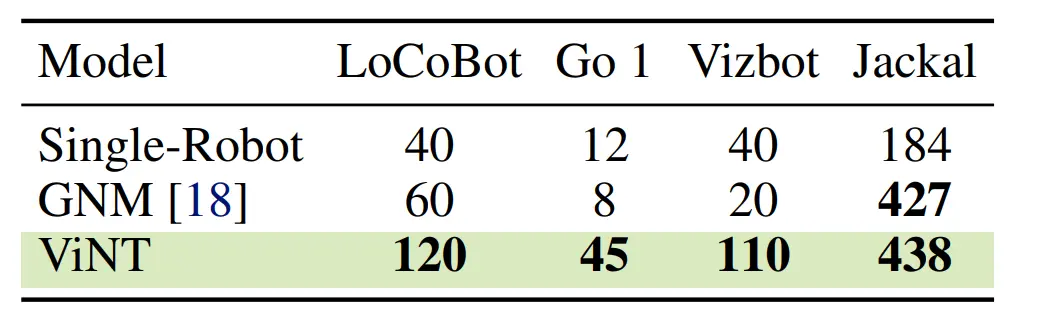
Figure: Comparison in Zero-shot Performance of ViNT with other models
In tasks related to coverage, ViNT successfully operates various robots, achieving maximum displacements of hundreds of meters without requiring any intervention. This performance surpasses that of lower-capacity models, such as GNM, as well as specialized models trained exclusively on a single robot dataset.
ViNT's accomplishment in zero-shot generalization is particularly noteworthy, as it effectively controlled a Go 1 quadruped—robot not included in its training data.
Broader Generalization via Fine-Tuning
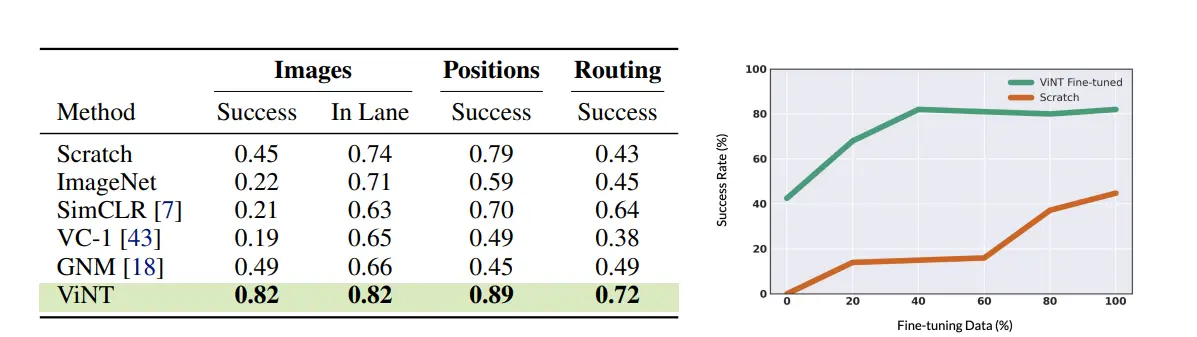
Figure: ViNT Performance over CARLA Simulator
From the above figure, we can observe that ViNT exhibits the capability to undergo end-to-end fine-tuning (Images) or adaptation for downstream tasks (Positions and Routing), consistently outperforming both training from scratch and alternative pre-training approaches.
On the right side, ViNT showcases its ability to transfer navigational capabilities to new tasks, achieving a 40% success rate even without fine-tuning and further excelling in the task with an 80% success rate after receiving less than one hour of fine-tuning data.
The green ViNT fine-tuning results outshine those of a single-domain model trained with five times the amount of data (indicated in orange).
ViNT Limitations
Similar to many large-scale models, ViNT imposes a higher computational load during the inference phase, which can pose challenges when deployed on power-constrained platforms like quadcopters.
While the design strives to facilitate efficient inference, it's important to note that our Transformer-based model still incurs considerably higher computational costs during deployment compared to simpler feedforward convolutional networks.
Furthermore, although ViNT demonstrates effective generalization across different robots in our experiments, it operates under the assumption of a certain level of structural similarity. For instance, it lacks the capacity to control the altitude of a quadcopter or adapt to alterations in the action representation, and it cannot accommodate the integration of new sensors like LIDAR.
Future efforts could involve training ViNT on a range of modalities and action spaces to address these limitations, potentially unlocking the capability to handle these varied scenarios and challenges.
ViNT Limitations
In conclusion, the emergence of general-purpose pre-trained models, often referred to as "foundation models," has significantly transformed the landscape of machine learning.
These models provide a robust starting point for addressing specific tasks, even when working with limited datasets, as they are typically trained on large and diverse datasets with minimal supervision.
The Visual Navigation Transformer (ViNT), introduced extends the success of foundation models into the realm of vision-based robotic navigation. By training on extensive navigation datasets from various robotic platforms, ViNT exhibits remarkable transfer learning capabilities, outperforming specialized models trained on narrower datasets.
ViNT's adaptability is a key highlight, as it can be fine-tuned for various tasks and environments. This adaptability includes the incorporation of diffusion-based goal proposals, enabling efficient navigation in novel environments.
Additionally, ViNT can adapt to new task specifications by replacing its goal encoder with another task modality, showcasing its versatility for mobile robotics applications.
Deployed on a diverse set of robotic platforms, including drones and quadrupeds, ViNT consistently demonstrates its ability to efficiently explore and navigate through previously uncharted environments. Its performance outpaces that of baseline methods, particularly in unguided goal-reaching tasks, emphasizing its efficacy in planning with diffusion subgoals.
ViNT also excels in zero-shot generalization, exhibiting impressive capabilities in controlling diverse robotic platforms without task-specific fine-tuning. This versatility is a testament to its potential for broader applications.
Through fine-tuning and adaptation techniques, ViNT outperforms other models when tasked with diverse goals, achieving both efficient navigation and successful generalization. Its performance, when compared to a model trained from scratch with increased data, highlights its efficiency in utilizing available resources.
However, it's important to acknowledge that ViNT, like many large-scale models, imposes a significant computational burden during inference, which may be a limitation in power-constrained settings.
Additionally, while it demonstrates effective generalization, it assumes a certain level of structural similarity among robots and may not handle certain variations or sensor integrations.
To address these limitations, future research could involve training ViNT on a broader range of modalities and action spaces, potentially unlocking its potential to handle a wider array of scenarios and challenges. Nevertheless, ViNT's adaptability and strong navigational capabilities make it a promising foundation model for various mobile robotics applications.
Frequently Asked Questions
What is the Visual Navigation Transformer (ViNT)?
ViNT is a general-purpose foundation model designed for vision-based robotic navigation. Pre-trained on extensive navigation datasets, it processes visual inputs to predict distances and forthcoming actions, effectively controlling various robotic platforms.
How does ViNT adapt to new tasks and environments?
ViNT adapts through full model fine-tuning and a prompt-tuning technique. By replacing its goal encoder with mappings for new modalities—like GPS waypoints or turn-by-turn directions—it can navigate novel environments without needing to be retrained from scratch.
What are the main limitations of the ViNT model?
ViNT imposes a high computational load during inference, making it challenging to deploy on power-constrained devices like quadcopters. Additionally, it relies on structural similarity among robots and currently lacks the ability to integrate new sensor types like LIDAR.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
