

Reinforcement learning with human feedback (RLHF) for LLMs

Researchers are working to improve Language Models' (LLMs') capabilities to make them even more intelligent and human-like in the constantly changing field of artificial intelligence.
A ground-breaking strategy that utilizes the cooperative potential of both machine and human intelligence is called reinforcement learning with human feedback (RLHF). RLHF aspires to open up new spheres of adaptability, nuance, and context in language generation by including human supervision in the training process.
In this blog, we set out on a quest to explore deeply the world of RLHF, exploring its fundamentals, potential uses, and revolutionary potential for the field of natural language processing. As we investigate the frontier of RLHF for LLMs, get ready to see the emergence of a potent human-machine alliance.
What is Reinforcement learning with human feedback (RLHF)?
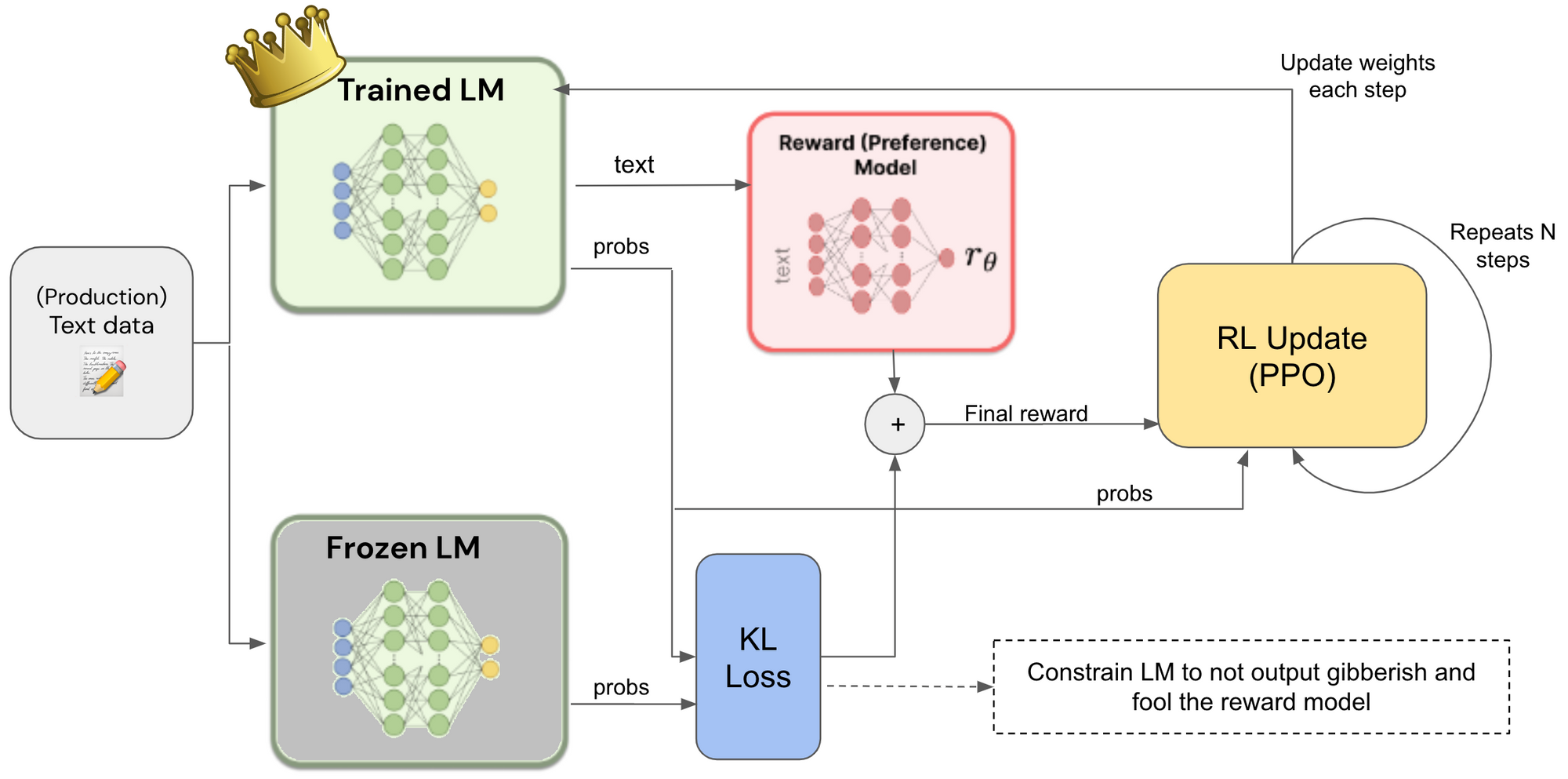
Machine learning models can be trained using human input thanks to a technique called Reinforcement Learning from Human input (RLHF). Large Language Models (LLMs), which can be difficult to train using conventional supervised learning approaches, can benefit greatly from this approach.
To improve the model, RLHF incorporates human feedback throughout training. The reinforcement learning algorithm is adjusted using human feedback, allowing the model to consider the results of its actions and modify its behavior accordingly.
RLHF is superior to conventional supervised learning techniques in a number of ways. Instead of relying on previously labeled data, it enables the model to learn from its own activities and modify its behavior as necessary. Additionally, by integrating RLHF with human values and preferences, large language models can be used safely and effectively.
By incorporating human feedback during training to improve the model, RLHF can be utilized to enhance LLMs. The reinforcement learning algorithm's reward function is modified using human feedback, allowing the model to take account of the results of its actions and modify its behavior accordingly. Large Language models can now be trained with less bias and more in line with human values and preferences thanks to RLHF.
News: Explore our latest technology LabelGPT and label your Images in a few minutes!
How to Use Reinforcement Learning for Large Language Model?
%20for%20LLMs/RLHF-LLM-reward-model.webp)
Large language models can be improved through reinforcement learning by being adjusted to make better judgments based on rewards and punishments.
Reinforcement Learning from Human Feedback (RLHF), which entails using human feedback during training to fine-tune the model, is one method of implementing reinforcement learning into language models. RLHF enables the model to take into account the results of its activities and modify its behavior as a result.
When working with large language models, pre-training can also be used to direct exploration by providing background information from text corpora. Using large language models, a technique known as Exploring with LLMs (ELLM) creates synthetic data that may be used to train reinforcement learning agents.
For fine-tuning large language models, reinforcement learning is recommended over supervised learning because it enables the model to learn from its own actions and modify its behavior accordingly rather than depending on pre-existing labeled data. Additionally, by integrating huge language models with human values and preferences, reinforcement learning can help reduce the dangers and misuse of those models.
What are some examples of tasks that can be improved using RLHF for LLMs?
%20for%20LLMs/RELF.webp)
Reinforcement Large Language Models (LLMs) can be enhanced for a range of activities using Learning from Human Feedback (RLHF). LLMs can be made more bias-free and more in line with human values and preferences by using RLHF.
The following are some tasks that can be enhanced by utilizing RLHF for LLMs:
- Text Generation: By incorporating human feedback during model training to hone the model, RLHF can be used to enhance the quality of text produced by LLMs.
- Dialogue Systems: By incorporating human feedback during training to improve the model, RLHF can be used to enhance the performance of dialogue systems.
- Language Translation: By incorporating human feedback during model training, RLHF can be used to increase the precision of language translation.
- Summarization: By including human feedback in the model's training process, RLHF can be used to raise the standard of summaries produced by LLMs.
- Question Answering: By incorporating human feedback during training to fine-tune the model, RLHF can be used to increase the accuracy of question answering.
- Sentiment Detection: By incorporating human feedback during model training to fine-tune it, RLHF has been used to increase the accuracy of sentiment identification for particular domains or businesses.
- Computer Programming: By incorporating human feedback during training to improve the model, RLHF has been used to speed up and improve software development.
Overall, by using human feedback during training to fine-tune the model, RLHF is a potent technique that may be utilized to enhance the performance of LLMs for a number of applications.
Examples of Products using Reinforcement Learning with Human Feedback (RLHF) for LLMs
For Large Language Models (LLMs), a number of products employ Reinforcement Learning from Human Feedback (RLHF). Products using RLHF for LLMs include, for instance:
- Scale AI: Scale AI provides a framework for developing LLMs and training them, incorporating RLHF to enhance language applications with human input.
- OpenAI: OpenAI has improved ChatGPT, a language model that produces text in response to user input, by implementing RLHF.
- Labelbox: Labelbox provides labeling software for RLHF to improve already-trained LLM models and produce human-like replies more quickly.
- Hugging Face: Hugging Face provides RL4LMs, a collection of building blocks for modifying and assessing LLMs using a range of RL algorithms, reward functions, and metrics.
In general, RLHF is an effective method that may be utilized to raise LLMs' performance in a range of activities. In order to create solutions that use LLMs for natural language production, question answering, sentiment recognition, computer programming, and language translation, a number of businesses and organizations are employing RLHF.
Conclusion
In conclusion, using Reinforcement Learning with Human Feedback (RLHF), Language Models (LLMs) can reach previously unheard-of levels of sophistication. LLMs are able to comprehend and produce language with more adaptability, nuance, and context thanks to RLHF, which makes use of human coaching during the training process.
This cooperative strategy has the enormous potential to revolutionize natural language processing and equip LLMs to communicate with people more perceptively and skillfully.
By bridging the gap between human expertise and machine learning algorithms, RLHF allows an effective collaboration between humans and machines. We may anticipate a new era of LLMs with a greater knowledge of the language, pushing the limits of AI-driven communication to new heights as we continue to investigate and improve RLHF approaches.
Want to know more about such AI-oriented information and technologies, Read here!
FAQs
Q1: What is Reinforcement Learning with Human Feedback (RLHF) for LLMs?
RLHF for LLMs is a method for developing language models that blends reinforcement learning strategies with human input. It includes employing a reward signal supplied by people to direct the language model's learning process.
Q2: How does RLHF function for LLMs?
There are normally two steps involved in RLHF. First, a language model is trained on a dataset of human-generated replies using conventional supervised learning methods. After that, a reward model is developed by compiling user comments on the output of the model. Using reinforcement learning methods, this reward model is utilized to adjust the language model.
Q3: Why does RLHF for LLMs use human feedback?
Compared to conventional methods that rely on predetermined reward functions, human feedback offers a more nuanced and focused reward signal. By including user input, RLHF enables the language model to gain knowledge from the experience and preferences of human raters, producing more precise and contextually relevant replies.
Q4: What kinds of human input are used in RLHF for LLMs?
Human feedback might come in the form of binary (such as a thumbs up or down), scaled (such as rating on a Likert scale), or comparative (such as evaluating several model-generated replies) incentives. The exact requirements of the program and the resources available will determine which sort of feedback is used.
Q5: What distinguishes RLHF for LLMs from traditional supervised learning?
The model is trained using a dataset of labeled examples in traditional supervised learning. In RLHF, supervised learning is used for the initial training, while reinforcement learning techniques are used for fine-tuning, with human input acting as the reward signal.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
