

Tutorial To Build AI Model For Fish Detection Using Kaggle Dataset


Table of Contents
- Introduction
- Prerequisites
- Concepts Required
- Methodology
- Dataset Selection
- Implementation
- Conclusion
Introduction
The aquaculture industry, which involves fish farming, faces various challenges that hinder its growth and sustainability.
One of the major issues is the lack of efficient and accurate monitoring of fish health, welfare, and environmental conditions, which can lead to reduced productivity, disease outbreaks, and economic losses.
Traditional monitoring of fish farms, such as manual observations and sample testing, is time-consuming, costly, and often unreliable.
As a result, there is a need for innovative and technology-driven solutions, such as computer vision-based systems, that can provide real-time, non-invasive monitoring and analysis of fish behavior, health, and environmental conditions, leading to improved fish health, productivity, and sustainability.
Figure: Aquabytes Smart data-driven fish monitoring system
According to a report by the Food and Agriculture Organization (FAO) of the United Nations, the global aquaculture industry has been growing steadily over the past few decades and reached a market size of over USD 245 billion in 2020.
Traditional monitoring of fish farms, such as manual observations and sample testing, is time-consuming, costly, and often unreliable.
As a result, fish farmers may lose significant amounts of money due to inefficient and ineffective management practices.
For instance, disease outbreaks can cause significant losses to fish farmers. According to a study by the University of Stirling, infectious salmon anemia (ISA) alone can cause losses of up to USD 180 million per year in the global salmon industry.
Moreover, the environmental damage caused by poor management practices can result in regulatory fines and damage the industry's reputation.
Aquabyte is one such company that provides computer vision and machine learning solutions to the aquaculture industry. The company was founded in 2017 and is located in San Francisco, California.

Aquabyte's technology is designed to improve the efficiency and sustainability of fish farming operations by providing real-time insights into fish health and behavior.
The company's products include underwater cameras and image recognition software to monitor fish populations, detect diseases, and optimize feeding practices.
Aquabyte's computer vision system is designed to identify and track individual fish within a farm environment. The system uses machine learning algorithms to analyze fish behavior and health based on data collected by underwater cameras.
This data can be used to make informed decisions about feeding, stocking densities, and other factors impacting fish health and growth.
Prerequisites
To proceed further and understand CNN based approach for detecting casting defects, one should be familiar with:
- Python: All the below code will be written using python.
- Tensorflow: TensorFlow is a free, open-source machine learning and artificial intelligence software library. It can be utilized for various tasks but is most commonly employed for deep neural network training and inference.
- Keras: Keras is a Python interface for artificial neural networks and is open-source software. Keras serves as an interface for the TensorFlow library
- Kaggle: Kaggle is a platform for data science competitions where users can work on real-world problems, build their skills, and compete with other data scientists. It also provides a community for sharing and collaborating on data science projects and resources.
Apart from the above-listed tools, there are certain other theoretical concepts one should be familiar with to understand the below tutorial.
Concepts Required
Transfer Learning
Transfer learning is a machine learning technique that adapts a pre-trained model to a new task. This technique is widely used in deep learning because it dramatically reduces the data and computing resources required to train a model.
This technique avoids the need to start the training process from scratch, as it takes advantage of the knowledge learned from solving the first problem that has already been trained on a large dataset.
The pre-trained model can be a general-purpose model trained on a large dataset like ImageNet or a specific model trained for a similar task.
The idea behind transfer learning is that the learned features in the pre-trained model are highly relevant to the new task and can be used as a starting point for fine-tuning the model on the new dataset.
Transfer learning has proven highly effective in various applications, including computer vision, natural language processing, and speech recognition.
Methodology
To proceed with our Fish monitoring system, we do the following steps:
- Import the required libraries
- Create the dataset in the required form and do data preprocessing
- Create our model using VGG16 as the base model
- Train our model
- Predict on Test data
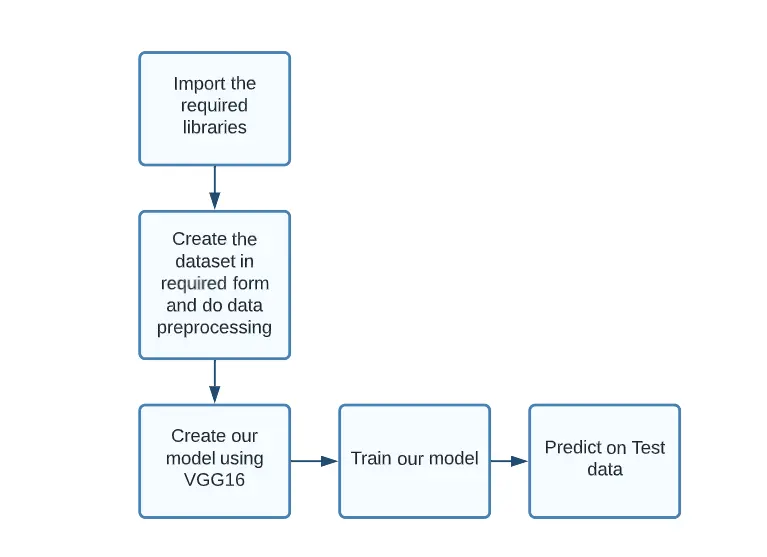
Figure: Flowchart for methodology (Image by author)
Dataset Selection
For the above project, we have used The Nature Conservancy Fisheries Monitoring dataset available on Kaggle. Some important points about the dataset include:
- The dataset consists of 3777 images with eight different fish species: Albacore tuna, Bigeye tuna, Yellowfin tuna, Mahi Mahi, Opah, Sharks, Other (meaning other types of fish), and No Fish (meaning no fish in the picture).
- The images are in JPEG format and have a resolution of 1280x720 pixels.
- The dataset is split into two sets: a training set with 2,544 images and a testing set with 1,233 images.

Implementation
Environment Setup
The below points are to be noted before starting the tutorial.
- The below code is written in my Kaggle notebook. For this, you first need to have a Kaggle account. So, if not, you need to sign up and create a Kaggle account.
- Once you have created your account, visit The Nature Conservancy Fisheries Monitoring and create a new notebook.
- Run the below code as given. For better results, you can try hyperparameter tuning, i.e., changing the batch size, number of epochs, etc.
Hands-on
We begin by importing the required libraries.
Next, we unzip our dataset and create the required directory structure.
As in the dataset, we are provided with train and test data. Thus we create validation data with a split of 10% of train data.
Next, we start with model preparation. For this project, we have used a pre-trained VGG16 model (base model), above which we place our custom model (head layer) and train only the head layer.
This way, the base model acts as a feature extractor, and the head layer acts as a classifier.
Why did we use VGG16 architecture?
We have used VGG16 due to the following reasons:
- Good performance: VGG16 has performed excellently on benchmark image classification datasets like ImageNet.
- Simple and uniform architecture: VGG16 has a simple and uniform architecture, which makes it easy to understand and implement.
- Pre-trained models available: Pre-trained VGG16 models are available, which can be fine-tuned on specific image classification tasks with smaller datasets. This can save time and computational resources and help improve the model's performance.
We begin by downloading the weights of the pre-trained VGG16 model.
The vgg_preprocess function preprocesses input images for the VGG16 convolutional neural network model. The preprocessing steps are as follows:
Subtract the mean RGB value from the input image. The mean RGB value was computed on the image set used to train the VGG16 model.
Reverse the order of the RGB channels to convert from RGB to BGR, which is the color order used in the VGG16 model.
Why did we pre-process the data?
These preprocessing steps are necessary because the VGG16 model was trained on images that were preprocessed in this way. By applying the same preprocessing steps to the input images, we ensure that the input data is in the same format as the training data and that the model can make accurate predictions on the input data.
Next, we create our head model.
To analyze our model structure, we print the summary of the model.
Next, we add this model to the top of our VGG16 base model.
Finally, we add a Dense layer to our model structure.
Next, we prepare our dataset using ImageGenetrators to perform data augmentation.
The above code:
- The code creates an instance of ImageDataGenerator class from keras.preprocessing.image module.
- trn_batches and val_batches are created by calling the flow_from_directory() method of ImageDataGenerator.
- flow_from_directory() method takes the path to the directory containing the images and generates batches of image data in the form of (x, y) pairs, where x is a batch of images and y is the corresponding label.
- The target_size parameter specifies the size to which the images are resized.
- class_mode is set to categorical, meaning the labels are represented as one-hot vectors.
- shuffle is set to True, meaning the order of the images is randomized within each batch.
- batch_size is set to 32, meaning each batch will contain 32 images.
Next, we train our model on our training data.
Finally, we analyze our model training. We plot both the training loss plot and the training accuracy of our model.
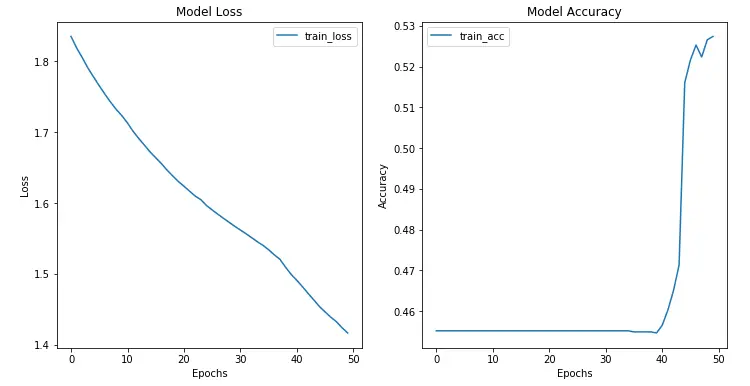
From the above plots, we see that:
- The model loss while training decreases as the number of training epochs increases. This means that our model is training in the right direction, i.e., learning correct parameters from training data.
- The accuracy has increased to 0.53. This can be further increased by tuning parameters like epochs, learning rate, etc.
Conclusion
The above blog discusses the aquaculture industry's challenges and how technology-driven solutions like computer vision-based systems can provide real-time monitoring and analysis of fish health, welfare, and environmental conditions.
Aquabyte, a company providing computer vision and machine learning solutions to the aquaculture industry, is mentioned as an example.
The blog then explains the methodology for developing a fish monitoring system using computer vision.
The dataset used is The Nature Conservancy Fisheries Monitoring dataset available on Kaggle.
The VGG16 model is used as the base model for the image classification task, and transfer learning is employed to fine-tune the model on the new dataset. The steps involved in the implementation are also explained.
In conclusion, computer vision-based solutions can potentially improve the efficiency and sustainability of fish farming operations. Using pre-trained models like VGG16 can greatly reduce the data and computing resources required to train a model.
Developing such solutions can benefit the aquaculture industry and help address some of its challenges.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
