

How to super fast data annotations process with automation?

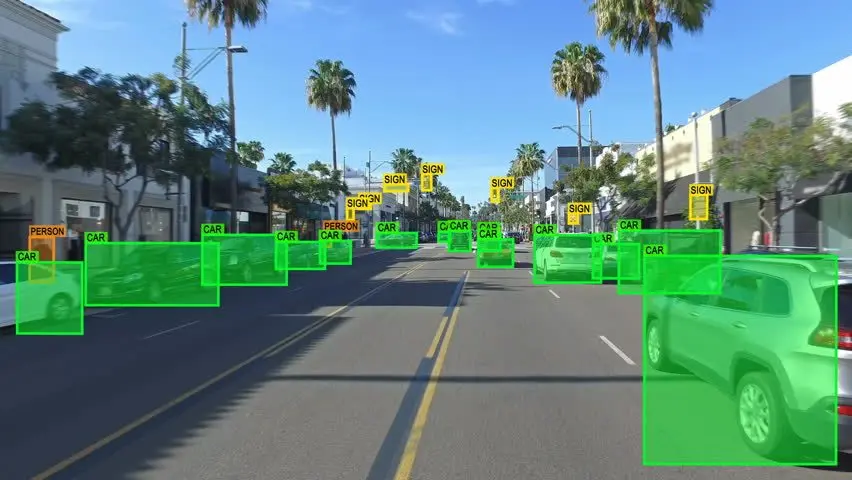
Lexi is a US-based data scientist and she is currently working on a data annotation project. She is looking for various methods to bring automation to data annotations. Let’s see what are the possible options for her.
Data annotation is a critical process for capturing data that can provide invaluable insights into business operations. Automating the process of data annotations not only results in greater accuracy and repeatability but also saves time, allowing teams to focus their efforts on more important priorities. In this post, we will explore various methods that businesses can use to bring automation to the data annotation process, providing an overview of key techniques along with the benefits associated with each approach.
We'll also look at the benefits and drawbacks of the annotation methods. So if you’re looking for ways to streamline your own dataset labeling tasks or simply want to understand how automation has advanced in this area, then read on! First, let’s see the difference between Manual and automated data annotation.
Manual vs. automated data annotation: What’s the difference?
Manual data annotation
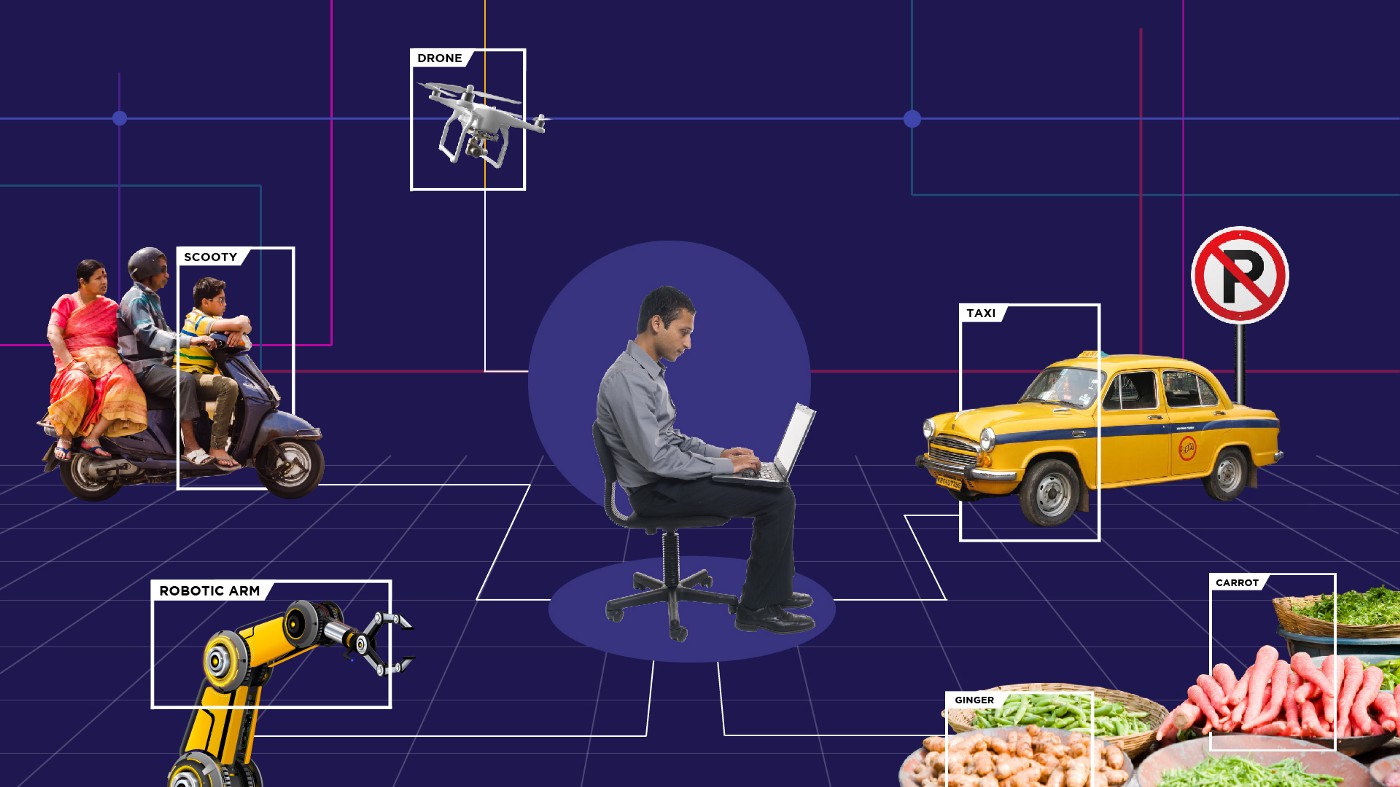
Manual data annotation requires a human annotator. This process is typically done by a team of commentators trained to understand the task at hand and the specific labels that need to be assigned. Annotators typically review each data point and assign appropriate labels based on their understanding of the data, labeling guidelines, and task at hand.
Manual data labeling is often used when the data is complex or when high-quality labels that require human interpretation and decision-making are needed. For instance, in medical and healthcare tasks It can also be used when there are no existing algorithms or models that can accurately characterize the data.
What are the benefits of manually labeling data?
One of the benefits of manual data labeling is the greater control and accuracy of the labeling process. Because labels are assigned by personnel trained to understand the data and labeling guidelines, they are often more correct and consistent than labels generated by automated methods. This is especially important for tasks that require high-quality labels, such as the image or audio classification task.
What are the drawbacks of manual data labeling?
On the other hand, manual data labeling can be time-consuming and costly, especially for large datasets. You also need a team of trained commentators, which can be difficult to find and manage.
Automated data annotation
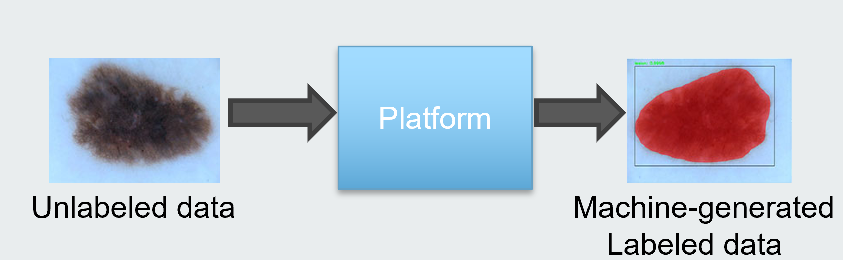
Automated data annotation, or AI-assisted data annotation, is the process of using artificial intelligence (AI) algorithms to aid human annotators in labeling data. In a sense, it is hybrid or semi-automated data labeling. This can be done in several ways. B. Suggest labels based on data (like a recommender system) or automatically generate labels that can be reviewed and corrected by human reviewers.
AI-powered data annotation is widely used to improve the efficiency and accuracy of the labeling process. Using AI algorithms to aid the labeling process allows human commentators to focus on more complex and nuanced tasks, while AI algorithms handle the more mundane or repetitive aspects of the labeling process. This reduces labeling time and resources while improving label quality.
What are the benefits of AI-supported data annotation?
One of the advantages of AI-powered data annotation is that it offers a balanced approach that combines the strengths of humans and machine learning. Human annotators can supply the ability and interpretation skills needed for complex tasks, while AI algorithms can handle the more mundane aspects of labeling, such as image recognition and text classification. This can improve label accuracy and consistency while reducing labeling time and resources.
What are the drawbacks of AI-supported data annotations?
However, AI-supported data annotations also have limitations. To train AI algorithms, we rely on the availability of labeled training data, which may not always be available or difficult to obtain. It also requires the development and implementation of AI algorithms that can support the labeling process. This can be a time-consuming and complex process based on the principle that algorithms in operation are incentivized for positive outcomes and penalized for negative outcomes. Naturally, over time, you'll learn to adopt the concept, adapt it, and deliver correct results.
Using trial-and-error methods, begin predicting outcomes that match the context you trained with your own feedback. Regression and classification challenges are identified and corrected autonomously thanks to the ability to adapt to changing results based on feedback loops. So once the algorithm learns that the image it is presented with is of a cat and not a dog, it learns how to distinguish between the two and gets better and better. The next time she is shown a fresh picture of a cat, she correctly finds herself.
Machine learning techniques and other approaches to auto-labeling
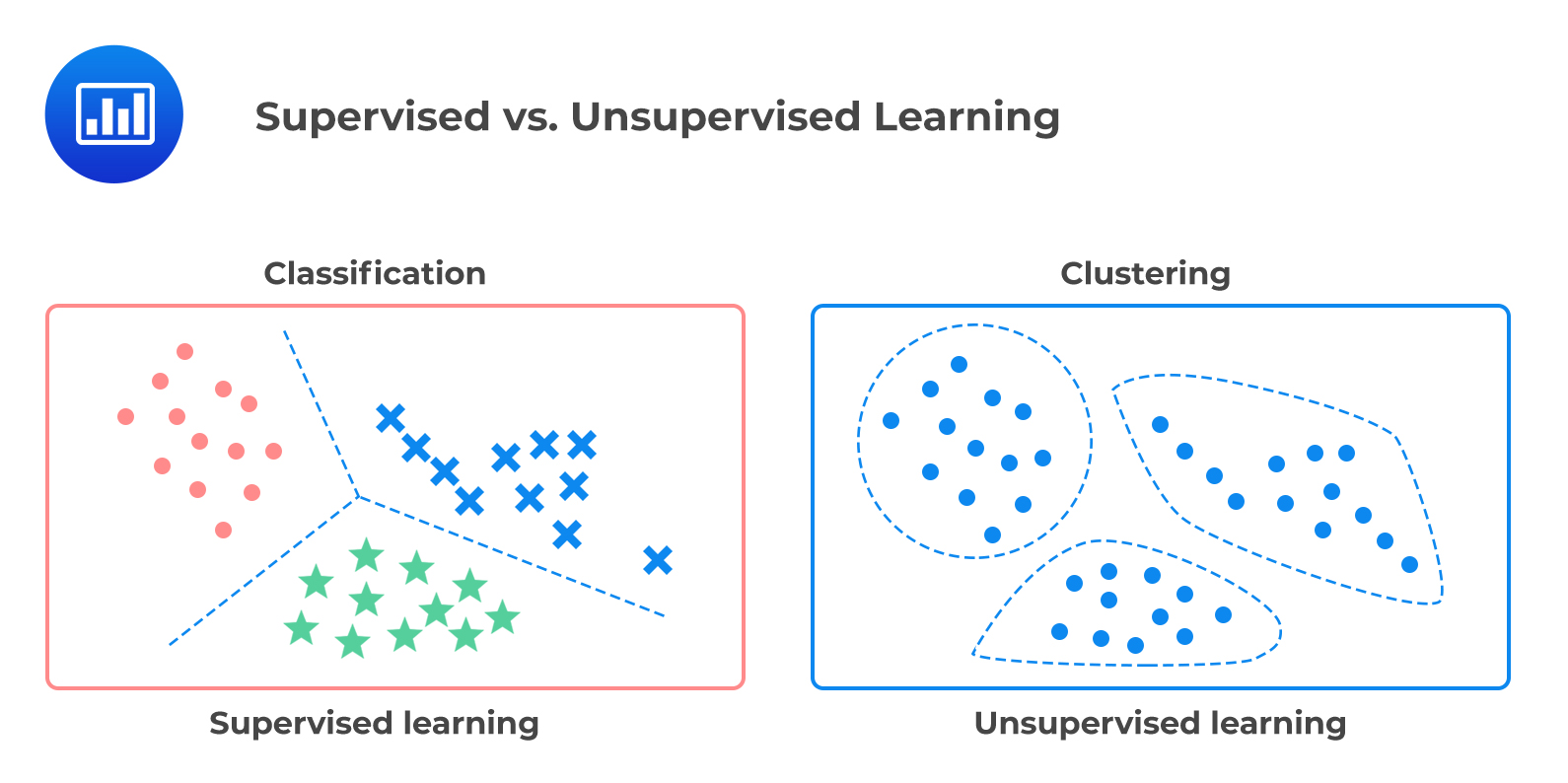
Supervised Learning
Supervised learning is a technique in which machine learning algorithms learn by mapping inputs to specific outputs. Simply put, learn from the examples provided. Supervised learning is very efficient in predictive analytics, where historical data can be matched to specific predictions.
For example, supervised learning can be used to predict equipment malfunctions in a factory based on failure history, predict the likelihood of repaying a loan based on creditworthiness, or predict a driver's likelihood of causing an accident. for calculating insurance premiums, etc.
This is an ideal method for automating data labeling, but supervised learning initially requires a huge amount of pre-labeled data to start the learning process, which is ironic. Introducing errors or mislabelled entities can skew the results and ultimately render the process useless.
Unsupervised learning
This is the exact opposite of supervised learning. Unsupervised learning thrives on unstructured or raw data, where you develop unique mechanisms to classify the data into clusters and make sense of it. Learning is autonomous without manual intervention. In other words, you don't need human-labeled records to understand what's a dog and what's a cat. You will find it yourself.
Labellerr's data annotation platform helps to build automated data annotation process?
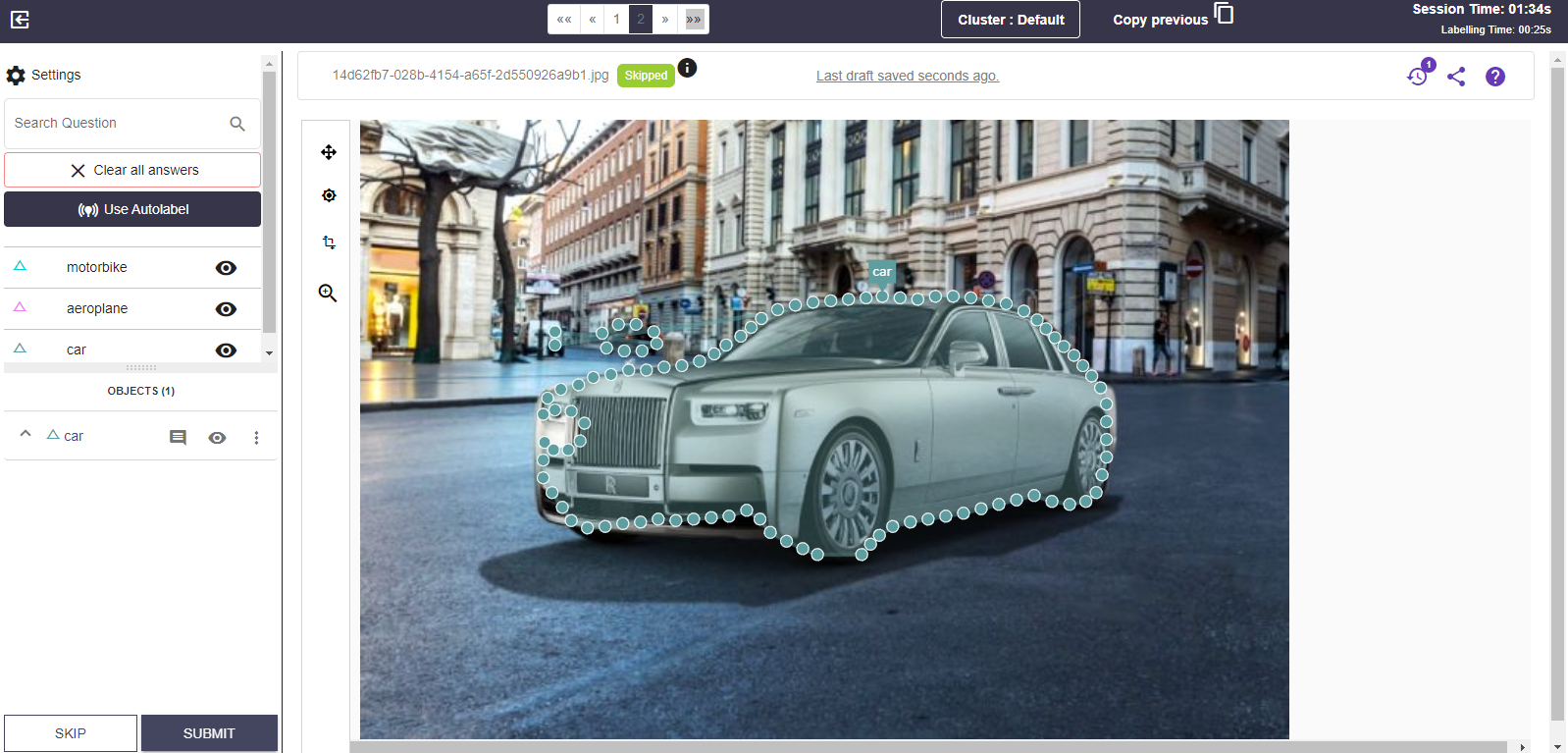
Labeller allows you to automate your data annotation process. With Labeller, you can access various annotating methods that help you deliver the best results. By doing so, you'll be able to find anything you missed and mark it appropriately, maintaining high quality as you grow.
Labeller has created the amazing feature of automatic image segmentation annotation to simplify processes and make your model training journey easier. You won't have to spend your valuable time sitting and doing the tedious segmentation process this way. All you must do is create a bounding box around the object, and our tool will do the image segmentation process for your images. Isn't it a fantastic feature? Yes, we know that it is.
Labeller is here to avail itself of the benefits of the automated object detection process. All you need to do is contact us to set it up for you. Our automated object detection feature allows you to work on exploratory data analysis. We have made it easier for you to detect datasets that are already labeled with classification or bounding boxes. We know no one heard you, but we did! So, if you are interested in making your model's performance much more effective, then waiting a day to do slow-processing data analysis or labeling is just a waste. Go ahead and automate your processes with Labeller.
Want to fasten your process with automated data annotation, contact us today!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
