

ML Beginner's Guide to Build Driver Monitoring AI Model


Driver monitoring systems are increasingly important to make on-road driving safer. To do this, the car must be able to monitor the driver's behavior and intervene if necessary to ensure the safety of everyone on the road.
One of the biggest challenges in developing driver monitoring systems is the complexity of human behavior. Drivers can exhibit a wide range of behaviors, and the system must be able to distinguish between normal driving behaviors and potentially dangerous ones.
Additionally, the system must handle changing conditions, such as lighting, weather, and road conditions. This requires using advanced computer vision and machine learning algorithms to detect and accurately classify the driver's behavior in real-time. By solving these challenges, driver monitoring systems can enable safe and reliable autonomous driving.
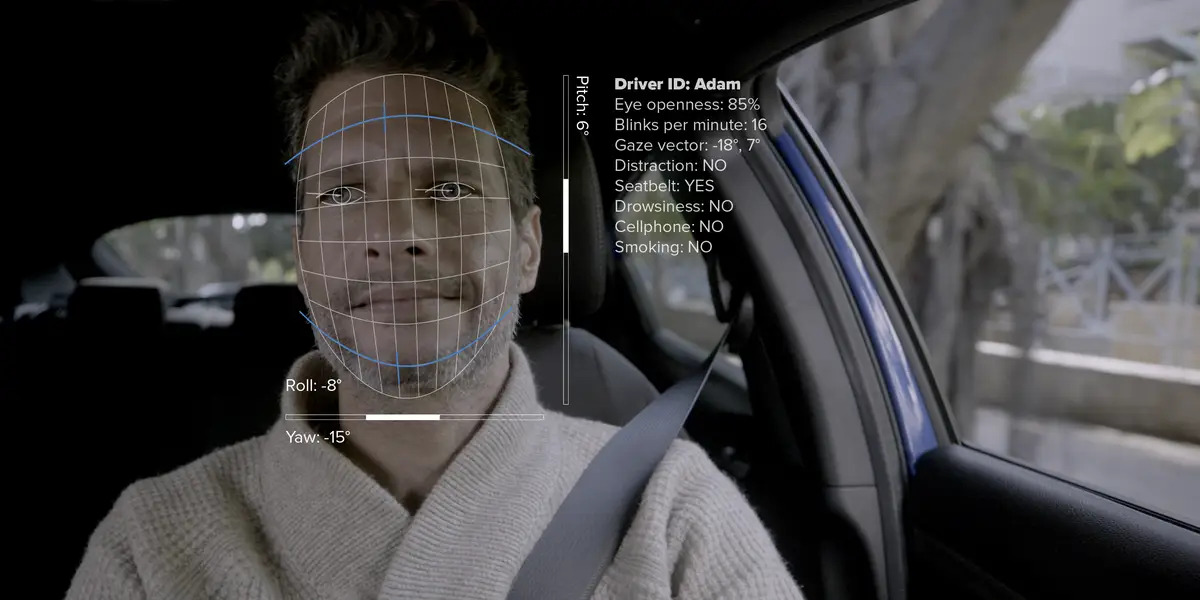
Figure: Driver monitoring system
According to a report by MarketsandMarkets, the global driver monitoring system market is expected to grow from $717 million in 2020 to $1,740 million by 2025 at a compound annual growth rate (CAGR) of 19.9% during the forecast period. This growth is driven by the increasing demand for advanced driver assistance systems (ADAS) and the growing road safety awareness.
The problem of driver distraction and fatigue has been estimated to cost the US economy $160 billion annually, according to a report by the National Safety Council. This cost includes medical expenses, property damage, and lost productivity due to accidents caused by distracted or fatigued drivers. Furthermore, the problem of driver distraction and fatigue leads to thousands of fatalities and injuries yearly, which has a significant emotional and societal impact.
Computer vision plays a critical role in driver monitoring systems for autonomous driving. It uses machine learning algorithms and deep neural networks to analyze video data from in-car cameras, tracking the driver's eyes, head position, and other facial features to determine their alertness and attention to the road.
By detecting signs of distraction, drowsiness, or other potentially dangerous behaviors, computer vision systems can alert the driver or the autonomous vehicle's control system to take action, such as providing visual or auditory warnings or adjusting the vehicle's driving mode. Computer vision can also help improve the overall driving experience by delivering personalized settings, such as seat and mirror positions, based on the driver's facial recognition.

Figure: Computer vision in Driving Monitoring System
CIPIA (Continuous Identification and Prediction of Interaction Actions) is a computer vision company that provides advanced driver monitoring and assistance systems for autonomous driving. The company's technology uses deep learning algorithms and 3D vision sensors to detect and analyze drivers' behavior in real-time, including their eye movements, head poses, and hand gestures. CIPIA's system can detect drowsiness, distraction, and other dangerous driving behaviors and provide alerts or corrective actions to prevent accidents.
The company's mission is to enhance the safety and comfort of autonomous vehicles for passengers and other road users while providing a seamless driving experience.
Read our blog on Cipia developing DMS.
Prerequisites
To proceed further and understand CNN based approach for detecting home objects, one should be familiar with the following:
- Python: All the below code will be written using python.
- Tensorflow: TensorFlow is a free, open-source machine learning and artificial intelligence software library. It can be utilized for various tasks but is most commonly employed for deep neural network training and inference.
- Keras: Keras is a Python interface for artificial neural networks and is open-source software. Keras serves as an interface for the TensorFlow library.
- Kaggle: Kaggle is a platform for data science competitions where users can work on real-world problems, build their skills, and compete with other data scientists. It also provides a community for sharing and collaborating on data science projects and resources.
Apart from the above-listed tools, there are certain other theoretical concepts one should be familiar with to understand the below tutorial.
Transfer Learning
Transfer learning is a machine learning technique that adapts a pre-trained model to a new task. This technique is widely used in deep learning because it dramatically reduces the data and computing resources required to train a model.
This technique avoids the need to start the training process from scratch, as it takes advantage of the knowledge learned from solving the first problem that has already been trained on a large dataset.
The pre-trained model can be a general-purpose model trained on a large dataset like ImageNet or a specific model trained for a similar task. The idea behind transfer learning is that the learned features in the pre-trained model are highly relevant to the new task and can be used as a starting point for fine-tuning the model on the new dataset.
Transfer learning has proven highly effective in various applications, including computer vision, natural language processing, and speech recognition.
VGG19 Architecture
VGG19 is a deep convolutional neural network architecture proposed in 2014 by the Visual Geometry Group (VGG) at the University of Oxford. It is a variant of the VGG16 architecture, a popular convolutional neural network used for image recognition.
The VGG19 architecture comprises 19 layers, including 16 convolutional layers and three fully connected layers. The convolutional layers are designed to extract features from images of different scales and orientations, while the fully connected layers are responsible for classification.
One notable feature of the VGG19 architecture is that it uses small 3x3 filters for convolution, which allows it to capture finer details in images. The architecture also uses max pooling layers after every two convolutional layers, which helps reduce the input's spatial size.
VGG19 has been used for various image recognition tasks, including object recognition, scene recognition, and image classification. It has also been used as a feature extractor for machine-learning tasks, such as image captioning and retrieval.
Methodology
In this blog, we will develop a small-scale prototype of our driver monitoring system, which describes the driver's state when driving in his vehicle. To proceed with our DMS system, we proceed in the following steps:
- We begin by importing the required libraries.
- Then, we visualize the dataset.
- Then, we create the train and validation data by splitting the dataset in the ratio of 80-20.
- Next, we create ImageGenerators, which perform data augmentation in real-time.
- Next, we create our model. For this, we use the concept of transfer learning.
- We finally train our model and make predictions on the given set of test images.
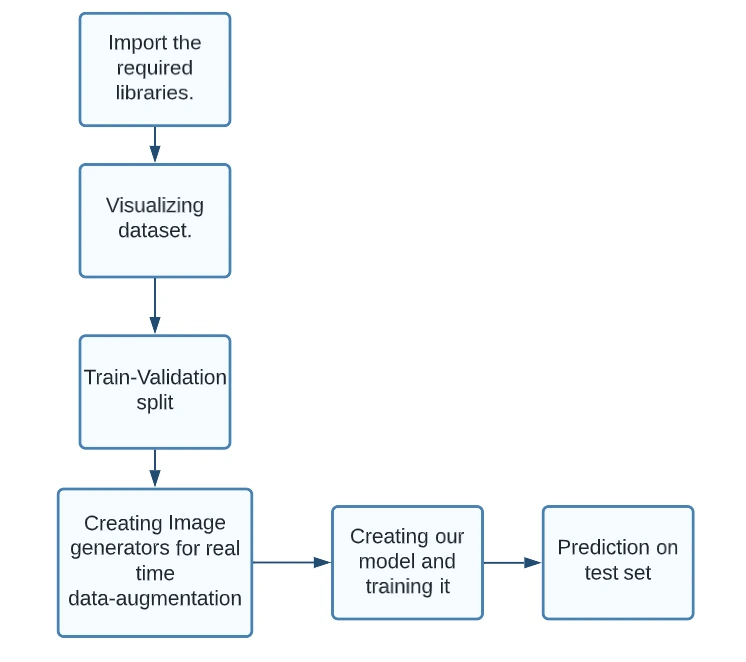
Figure: Flowchart for methodology
Dataset Selection
The Small Home Objects (SHO) image dataset available on Kaggle, created by Hossein Mousavi, is a collection of 1,312 high-resolution images of 10 small household objects. The objects include a calculator, stapler, scissors, pencil, keychain, pen, marker, eraser, ruler, and a paper clip.
The images were captured using a smartphone camera and saved in JPG format. They have a resolution of 4032 x 3024 pixels and are labeled according to the object they depict. The dataset is split into training and testing sets, with 80% of the images used for training and 20% for testing.
The dataset is intended for computer vision and machine learning research, particularly for object recognition and classification tasks. The dataset's small size and relatively simple objects make it a valuable resource for training and testing models for beginners or those interested in a more straightforward classification problem.
Below, I’ve attached a sample image corresponding to each activity class of the driver.
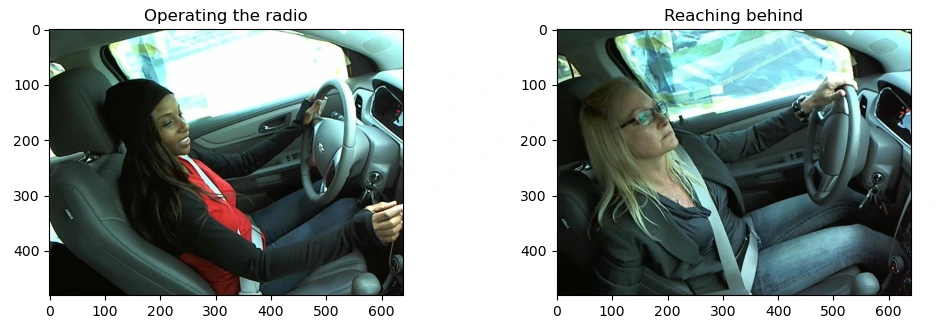
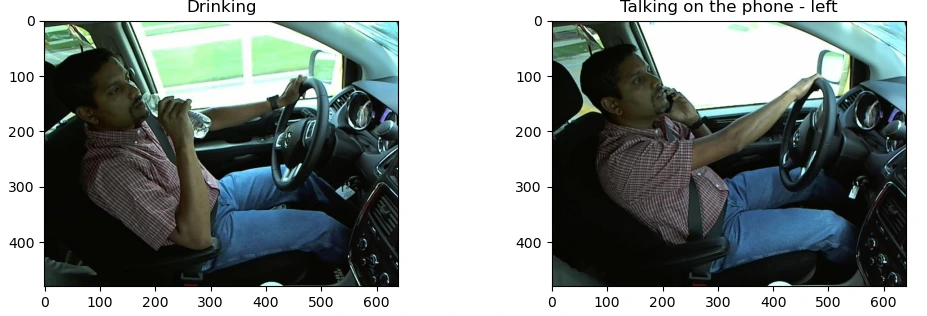

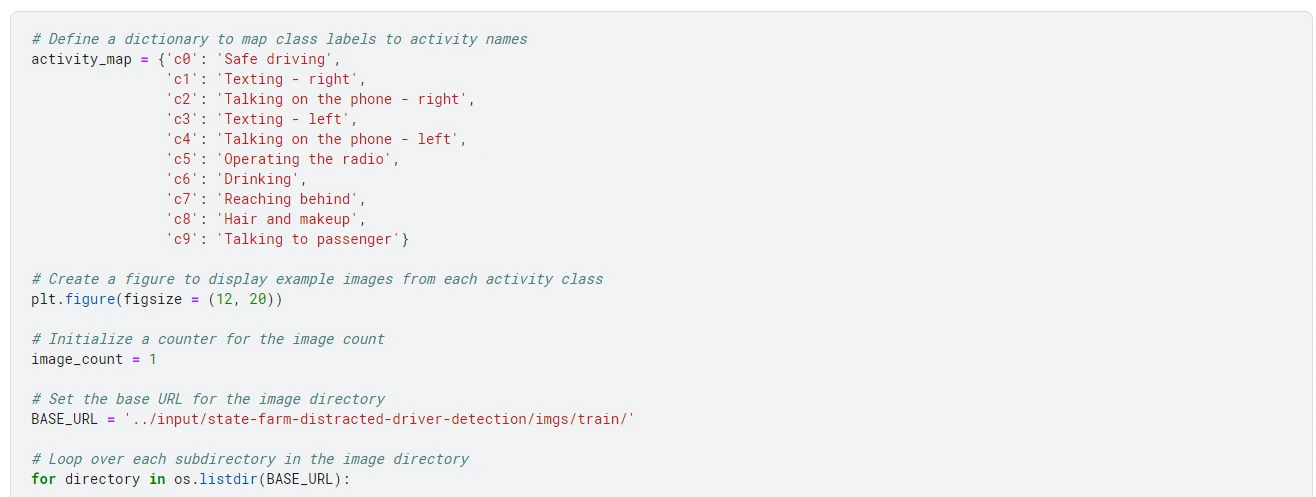
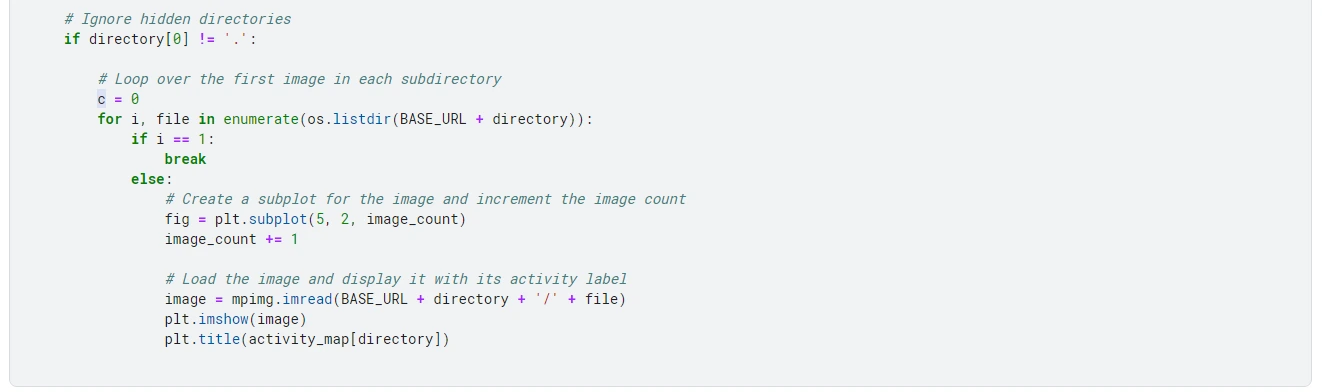
Implementation
Environment setup
The below points are to be noted before starting the tutorial.
- The below code is written in my Kaggle notebook. For this, you first need to have a Kaggle account. So, if not, you need to sign up and create a Kaggle account.
- Once you have created your account, visit Distracted Driver Activity and create a new notebook.
- Run the below code as given. For better results, you can try hyperparameter tuning, i.e., changing the batch size, number of epochs, etc.
Hands-on with Code
We begin by importing the required libraries.

Next, we perform some data visualization and then perform a train-test split. For our project, we do a train-test split of 80-20.
I am plotting the data for each activity of the driver.
From the above plots, we can see that our model could detect drivers in 10 distinct states.
Now, we perform our train-validation split on the dataset. We have performed a split of 80-20 on our dataset, which means that 80% of our data is in the train set and the remaining 20% in the validation set.

Next, we perform some Data Augmentation on our dataset.
This code sets up generators for training and validation data for image classification using Keras' ImageDataGenerator class.
First, it sets the data generator's batch size and image size, with batch_size equal to 32 and img_height and img_width equal to 224.
Then, it creates an instance of the ImageDataGenerator class with no image augmentation, which will be used for the training data. Another instance is created for the validation data.
Next, it creates separate generators for the training and validation sets using the flow_from_directory method. The training data specifies the directory containing the training data (/kaggle/working/output/train), target size (224 x 224), batch size (32), and type of labels (categorical). It also specifies that the subset of data to use is the training set (subset='training').
The validation data specifies the directory containing the validation data (/kaggle/working/output/val), target size (224 x 224), batch size (32), and type of labels (categorical).
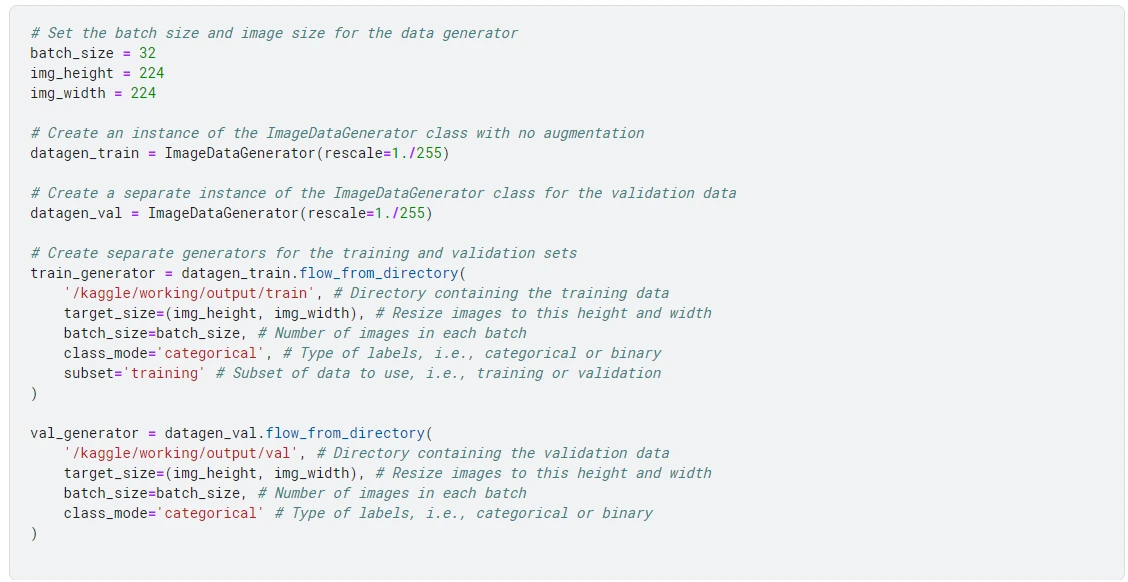
Next, we create a function for plotting loss and accuracy.
The code defines a function to plot the training history of a machine learning model, displaying both the validation accuracy and validation loss over epochs. It uses the matplotlib library to create two plots for accuracy and loss, with separate lines for the training and validation data.

Next, we create our model and train it for five epochs.
This code defines a new model by adding some layers to a pre-trained VGG19 model with ImageNet weights, excluding the top layer. The new layers consist of a flattened layer, three dense layers with ReLU activation functions, two dropout layers, and a final dense layer with a softmax activation function. The new model is then compiled with Stochastic Gradient Descent (SGD) optimizer, categorical cross-entropy loss, and accuracy metric.
The input shape of the pre-trained model is (224, 224, 3), which means that it expects images with a width and height of 224 pixels and three color channels (RGB). The output shape of the new model is (10), which predicts ten different classes.
Why VGG19?
For this project, we have used vgg19 due to following reasons:
- Strong performance: VGG19 has achieved state-of-the-art performance on various image classification benchmarks, such as the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) dataset.
- Transfer learning: VGG19 has been pre-trained on large-scale image datasets, such as ImageNet, which allows it to be used for transfer learning.
- Training Time: VGG19 has a relatively simple architecture compared to more recent deep neural networks such as ResNet, DenseNet, and EfficientNet. This simplicity can make it faster to train than these newer architectures.
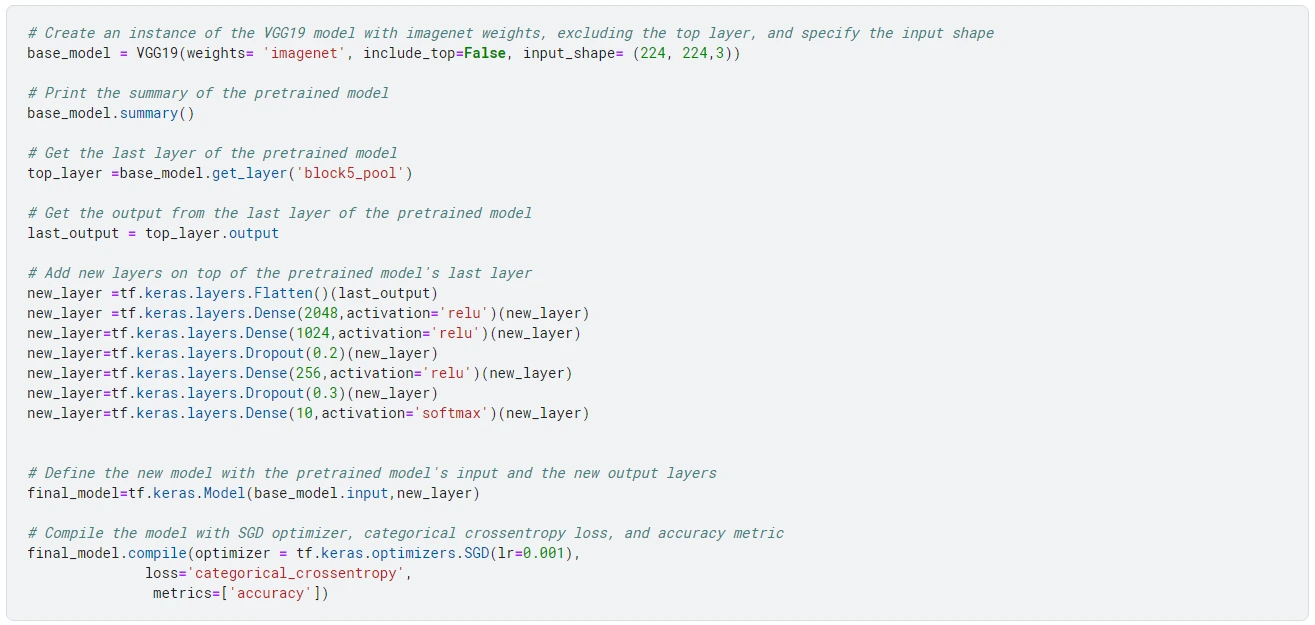

After the training is complete, we plot the loss and accuracy curves.

Output
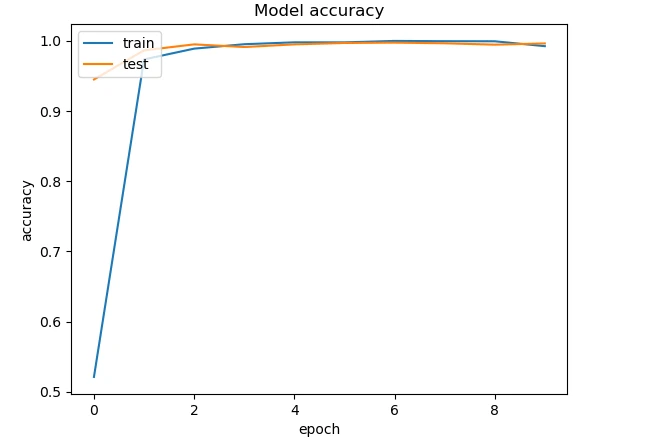
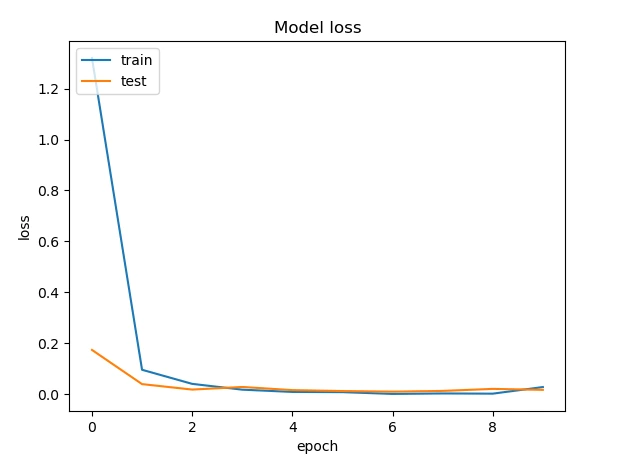
Figure: Accuracy Plot and Loss Plot
From the above two plots, we observe that:
- The loss decrease and converges to a value of 0.
- The accuracy increase and converges to a value near 1.
Also, we don't see much oscillation in the curve; thus, our learning rate is also fine.
Conclusion
In conclusion, driver monitoring systems are increasingly important in developing autonomous driving technologies. These systems must accurately detect and classify a wide range of driver behaviors in real-time using advanced computer vision and machine learning algorithms.
In the above tutorial, we saw the implementation of an activity detection of Distracted-Drivers using Keras' ImageDataGenerator class. The tutorial starts with importing the required libraries and performing data visualization, followed by a train-test split. The data is then augmented using the ImageDataGenerator class.
A function for plotting loss and accuracy is defined, and a model is created by adding layers to a pre-trained VGG19 model with ImageNet weights, excluding the top layer. The new model is then compiled with a Stochastic Gradient Descent optimizer and categorical cross-entropy loss.
Finally, the model is trained for five epochs, and the loss and accuracy curves are plotted. The tutorial also suggests that hyperparameter tuning can be performed to improve results.
Companies like CIPIA provide advanced driver monitoring and assistance systems for autonomous driving using deep learning algorithms and 3D vision sensors.
Looking for high quality training data to train your driver monitoring AI model? Talk to our team to get a tool demo.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
