

Meta Launched Co-Tracker! This Is What We Have to Say About It.


Table of Contents
- Introduction
- Co-Tracker Architecture
- Essential Aspects of Co-Tracker's Functionality
- Our Findings About Co-Tracker's Performance
- Conclusion
- FAQs
Introduction
Last Month, Meta AI released a deep learning-based model for tracking objects in a video motion called Co-Tracker. Co-Tracker is a fast transformer-based model that can track any point in a video. It brings to tracking some of the benefits of Optical Flow. Co-Tracker can track:
- Every pixel in a video
- Points sampled on a regular grid on any video frame
- Manually selected points

Figure: Co-Tracker Output for video tracking
Multi-object Tracking, in computer vision, is a task where you detect and follow multiple objects in a video. The aim is to spot and figure out where these objects are in each frame and connect them from one frame to the next to monitor how they move over time.
It is a challenging task because of many factors, including:
- Objects getting hidden (commonly referred to as occlusions)
- Blurriness in motion and changes in how objects look.
- Rapid frame/perspective changes due to changes in the camera frame.
Usually, to solve this, you use methods that combine object spotting and figuring out how they relate to each other as they move.
![]()
Figure: Multi-Object Tracking in Computer Vision
Methods for predicting motion in videos can take two main approaches: either estimate the motion of all points in a single video frame together using optical flow or independently track the motion of individual points throughout the entire video.
Even powerful deep-learning techniques tend to follow the latter approach, which involves tracking points separately, even when dealing with occlusions. However, this method overlooks the strong correlations between these points, such as when they are part of the same physical object, potentially leading to reduced performance.
This architecture, used in Co-Tracker, combines optical flow and tracking research insights into a new, adaptable, and robust design. It is primarily built on a transformer network that models the temporal correlations between different points using specialized attention layers.
The transformer continually refines the predictions for multiple trajectories, making it suitable for applications with long videos using an unrolled training loop.
Moreover, the Co-Tracker is flexible and can track anywhere from one to several points simultaneously, with the capability to add new points to track at any point in time.
In this blog, we aim to discuss Co-Tracker. More precisely, we aim to talk about the different features of Co-Tracker along with its limitations. We will discuss scenarios where it might not work as expected.
Co-Tracker Architecture
The special thing about Co-Tracker is that it uses two different ways to pay attention: one to see how things change over time and the other to see how things are related. Co-Tracker better understands how things move and fit together in videos using these two ways.
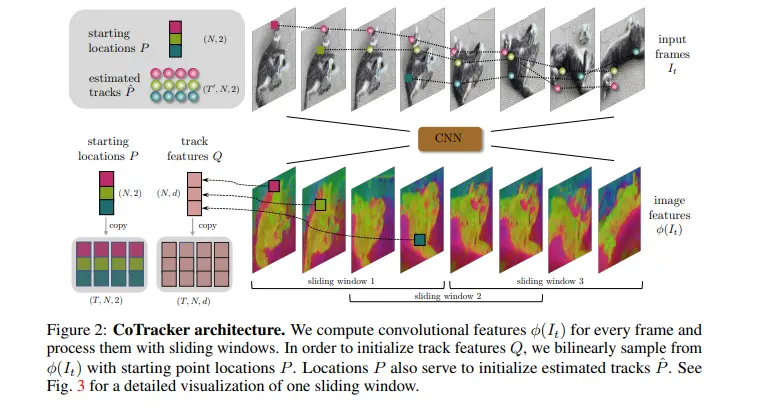
Figure: Architecture for Co-Tracker
This clever approach helps Co-Tracker better predict motion in videos than older methods that only look at one thing at a time. It's like a new and improved way of making videos more accurate.
Smart motion tracking helps computers follow moving objects in videos more accurately and quickly. It uses new technology to track objects even when they move fast or hide behind others.
Good labeled data is very important for smart motion tracking. Using easy and precise labeling tools, many points and objects in videos can be marked clearly. This helps train smart trackers to become more accurate and reliable.
Essential Aspects of Co-Tracker's Functionality
In their exploration of Meta Co-Tracker, the researchers discovered a variety of methods for tracking points in videos, with certain approaches proving particularly suitable for their specific use cases:
Grid-Based Tracking
This method involves dividing an image, such as a 720x720 frame, into a grid of specified dimensions. Subsequently, all points within each grid cell are tracked accordingly. However, this approach is limited because it doesn't allow pinpointing a specific region within the frame.

Figure: Grid-Based Tracking
Manual Point Selection
In this approach, users manually supply the model with the coordinates of specific points and the corresponding frame numbers from which tracking should commence. For instance, users can designate the centroid of a bounding box or select a couple of points within the bounding box. Co-Tracker can then track these designated points.
Combining a Regular Grid with a Segmentation Mask
In this strategy, the objective is to track points within a mask_object. However, a notable challenge arises because the Co-Tracker needs a built-in mechanism for segmenting the object.
To address this, users must determine the object's coordinates within the bounding box, which can be achieved using techniques like SAM.
Sequential Steps Approach
First, we find the exact location of a bounding box. Then, we carefully figure out the shape's location inside this box using a pre-trained model like SAM.
After that, we go through the detailed process of pinpointing the exact spots of the points within this shape. Finally, we track these points, following their movements over time. Even though this process involves several detailed steps, it has the potential to provide very accurate tracking results.
When we successfully find these tracked points, the system adds the bounding box around the object in the frames where the points are seen. These diverse tracking approaches empower Meta Co--Tracker to adapt to a range of tracking scenarios and cater to users' specific requirements.
Our Findings About Co-Tracker's Performance
This section discusses specific cases and situations where Co-Tracker fails to provide multi-object tracking.
Tracking with Multiple Camera Perspectives
From what we have studied above, a Meta Co-Tracker is primarily built on a transformer network that models the temporal correlations between different points using specialized attention layers. However, the Co-Tracker might sometimes work as expected for some larger cases. Consider the following case:
Consider a scenario involving a soccer game. Imagine you're trying to track the movements of the soccer players on the field using a computer vision system. In some cases, only some of the players will follow the same path from one frame to the next.
For instance, a player might suddenly change direction to pass the ball while another continues running in a straight line. This means that the correlation between all the points on the players may only sometimes work as expected.
Now, think about the challenge of processing the images from multiple cameras around the stadium to get a complete view of the game. Each camera captures the action from a different angle, and as a result, the points on the players may need to match up perfectly between the camera views.
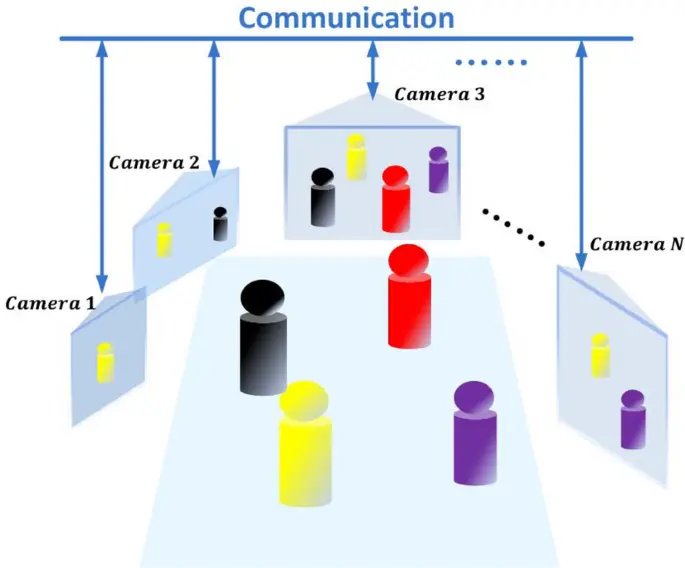
Figure: Tracking from multiple cameras and Perspectives
For example, when a player moves from the view of one camera to another, the points on that player may no longer be visible in the new camera's perspective.
In this context, using transformers, which are powerful but complex neural networks, to handle all the possible motions and viewpoints captured by the cameras is challenging.
Zoom In and Zoom Out
The tracking system couldn't follow the designated point correctly when the camera zoomed in or out in the initial frame. To understand, look at the snippet below:

Figure: Video Illustration of How Co-tracker Fails on Zoomed-up Video
As we can see in the above video:
- The Co-tracker initially begins by tracking a point in a video.
- However, on zooming up the video, the ideal behavior should have been that the tracking of the point should have vanished/stopped as the point selected is now out of the window scope. Instead, it keeps on tracking the point in the video
Failing to track Rapid Movement
The tracking system didn't correctly stop tracking the point when an object obstructed it, and it also struggled to keep up with the point's movement when it moved very quickly.

Figure: Video Illustration of How Co-tracker Fails on Rapid Movement
For a better understanding, imagine a scenario at a busy airport. The airport security has deployed a state-of-the-art tracking system to monitor the movement of passengers and their luggage. In this case:
Occlusion Problem: A passenger is walking through the security checkpoint area, pushing a large suitcase. As the passenger approaches the X-ray machine, they place the suitcase on the conveyor belt. The tracking system has followed the passenger's movements accurately until now.
However, as the suitcase moves onto the conveyor belt, it obstructs the view of the passenger's legs and lower body. The tracking system doesn't correctly stop tracking the passenger, and it mistakenly tracks the suitcase instead, losing sight of the person temporarily due to the obstruction.
Rapid Movement Challenge: Meanwhile, in another area of the airport, a passenger is in a hurry to catch a connecting flight. This passenger is moving quickly, weaving through the crowd.
The tracking system is designed to keep tabs on individuals, but it needs help to keep up with the rapid movements of this fast-moving passenger. As a result, the tracking system may occasionally lose track of the person or provide laggy updates, making monitoring their exact whereabouts in real-time difficult.
In this real-life scenario, the challenges of object occlusion and tracking fast-moving objects illustrate situations where a tracking system may encounter difficulties.
These challenges can affect airport security, highlighting the need for robust tracking solutions that can handle various scenarios effectively to ensure passenger safety and security.
Conclusion
After thoroughly examining Meta Co-Tracker, it's evident that this innovative architecture brings significant advancements to the challenging field of multi-object tracking in computer vision.
The primary goal of multi-object tracking is to detect and follow multiple objects across video frames, providing insights into their movements over time. Co-Tracker addresses the inherent complexities of this task by introducing a novel approach that simultaneously tracks multiple points within video sequences.
This architecture combines insights from optical flow and tracking research into a flexible, robust design primarily built on a transformer network. Co-Tracker's unique features, including dual attention mechanisms, the transformer network, windowed inference, and unrolled learning, make it a promising tool for handling long videos and predicting motion accurately.
However, it's important to acknowledge the challenges and limitations that come with this approach. The complexity of the transformer network can pose difficulties, particularly when dealing with densely packed predictions. Furthermore, the Co-Tracker's effectiveness may vary depending on the specific use case, particularly when tracking objects with diverse motion trajectories.
It's also worth noting that challenges arise when the camera zooms in or out, potentially leading to tracking errors. Additionally, Co-Tracker may face difficulties in tracking rapidly moving objects and handling occlusions, which are common scenarios in real-world applications.
(Subhradip Roy, ML Associate @Labellerr performed this experiment and benchmarking on the Co-Tracker model.)
How Labellerr Can Help Your Motion Tracking Projects
Easy and accurate video labeling tools speed up the training of smart motion tracking models. Try a free demo todaythe to see how these tools can improve your AI projects.
Frequently Asked Questions
1. What is Co-Tracker, released by Meta Ai?
Co-Tracker is a fast transformer-based model that can track any point in a video. It brings to tracking some of the benefits of Optical Flow. Co-Tracker can track:
- Every pixel in a video
- Points sampled on a regular grid on any video frame
- Manually selected points
2. What Are the Challenges and Limitations of Co-Tracker?
Co-Tracker, while promising, has certain challenges and limitations. The transformer network's complexity can be a drawback, particularly when dealing with densely packed predictions.
Effectiveness can vary depending on the specific tracking scenario, such as objects with diverse motion trajectories. Co-Tracker may face difficulties when dealing with zooming in or out of the camera or tracking rapidly moving objects. Additionally, it can struggle with object occlusions, impacting tracking accuracy in real-world scenarios.
3. What is Multi-Object Tracking?
Multi-object tracking is a computer vision task aimed at detecting and following multiple objects in a video, tracing their positions across frames to understand their motion over time.
This task is challenging because objects can become hidden due to occlusions, exhibit motion blur, or change appearance. Tracking methods must combine object detection with understanding the relationships between objects as they move.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
