

A Guide On How To Achieve Automated Data Labeling With Machine Learning


Table of Contents
- What's the Process of Data Labeling?
- Most Common Types of Data Models
- Automated Data Labeling with Machine Learning
If you are associated with data labeling, then you must be aware of how hectic this process is with the manual labeling process. Humans in the loop are a key factor but they should not be the only factor.
With automated data labeling, you can fasten your data labeling process to a greater extent and achieve better efficiency. If you are thinking how is it possible? Then, read out the complete blog to know how!
Some of the problems caused by the time-consuming annotation cycle may be solved by automatic data labeling techniques. A model of machine learning can be used to process a collection of unlabeled data after being trained on a labeled dataset.
But before getting deep into automated data labeling, let’s first understand what is data labeling.
Data labeling in machines is the method of classifying unlabeled data (such as images, text files, videos, etc.) and giving one or more insightful labels to give the data structure so that a machine-learning model may learn from it.
For example with the help of a Label, we can identify if a photograph shows a bird or an automobile, or whether a tumor is visible on an x-ray. For several use cases in computer vision data labeling is necessary.
What's the process of data labeling?
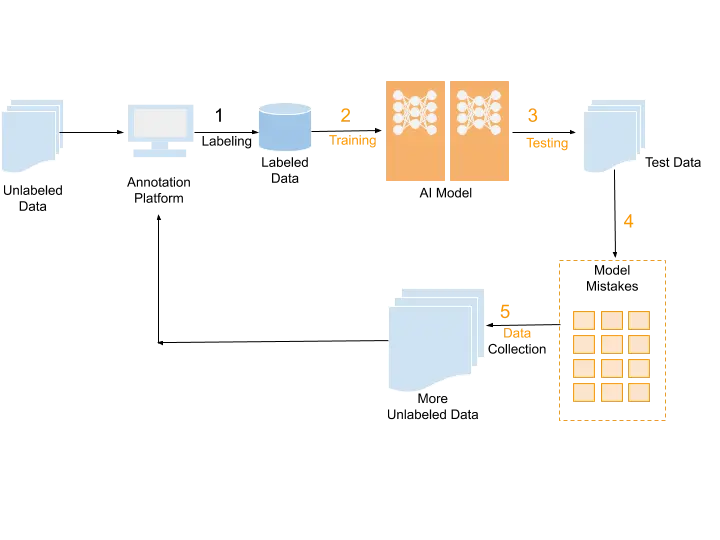
Processes for data labeling operate in the following ways:
Data gathering: The gathering of Raw data will be employed for training the model. To create a dataset that can be used to feed the model directly, this data must be cleaned and processed.
Data tagging: Several ways of data labeling are used to label the data and link it to an appropriate context that the computer can utilize as a source of truth.
Quality control: The accuracy of the coordinate points for bounding boxes and key-point annotations, as well as the precision of the tags for a given data point, are frequently used to assess the quality of the data annotations. Finding the accuracy rate of these annotations can be done with the use of QA tools like the Consensus mechanism and Cronbach's alpha test.
The machine-learning model is then trained to recognize patterns using this data. Model training is the process of instructing deep learning and machine learning models. Using fresh labeled data, even mature machine-learning models can be retrained.
Most Common types of data models
The three most typical fields and data model types that employ labeled data are:
Computer Vision: A branch of machine learning research known as "computer vision" (CV) teaches computers to recognize and comprehend images. To understand patterns or identify imagery, computer vision algorithms use annotated visual data. For instance, annotated image data with useful descriptors should be provided first to a computer vision learning algorithm to identify different bird species.
Natural Language Processing (NLP): It is a branch of study that focuses on instructing computers to recognize and comprehend spoken and written language. Predictive text for producing assistance is currently NLP's most common application.
For their final datasets, several NLP firms obtain user app data. But in some circumstances, this data still needs to be sorted and labeled. Frequently, this is originally carried out by operators.
Audio Processing: The study of teaching computers to recognize and classify sounds is known as audio processing. Music and animal noises can also be included in this audio.
A smartphone application that recognizes songs by recording them, is an excellent example of a commercial product that employs audio processing algorithms. Various sounds and noises will initially need to be labeled and categorized by humans. Labels may be necessary to transcribe the audio if it contains speech.
Automated Data Labeling with Machine Learning
Today, experiential learning applies to machines that can feel, think, act, and adapt through experience to resemble the human brain. The researchers do this by utilizing machine learning methods, which enable AI systems to independently study and learn from data input. Therefore, which method is employed for automatic labeling:
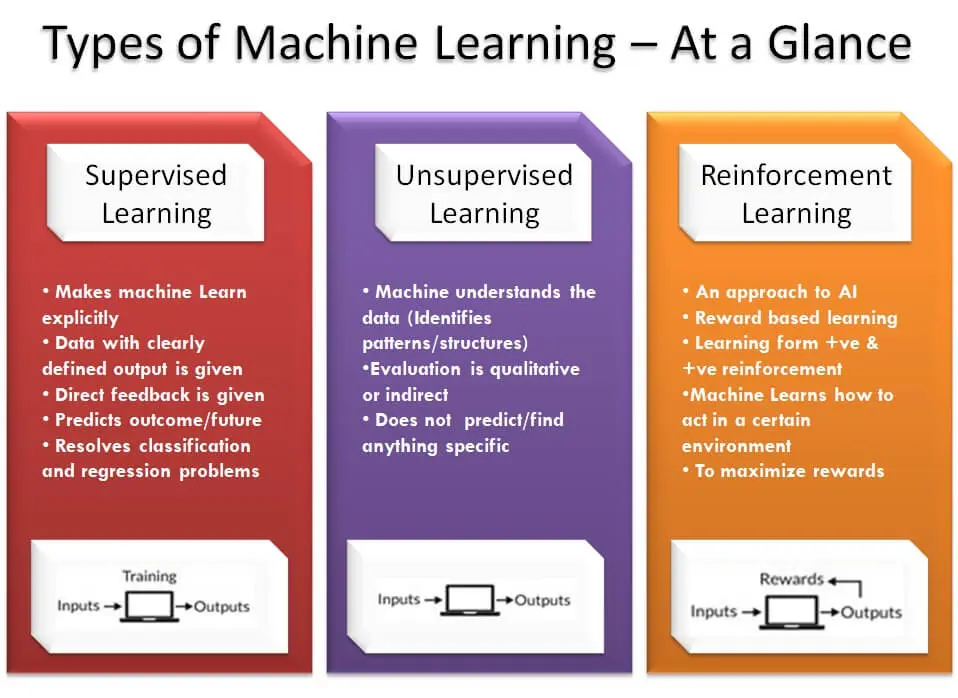
Reinforcement Learning: AI models can learn through trial and error in a particular situation leveraging feedback from their personal experience thanks to reinforcement learning. Robotics, video games, processing of data, automation systems, and chatbots that learn from human interactions all make extensive use of them.
Supervised Learning: There must be a tremendous amount of manually labeled data. To identify mistakes and inconsistencies, the system evaluates the fresh data received with the labeled data. After that, the model has adjusted appropriately.
It gains the capacity to forecast the likelihood of future occurrences and is primarily used to foresee fraudulent transactions or examine past data. An error or inconsistency in the data input might have a detrimental impact on the output quality, making it a very sensible but time-consuming technique.
Unsupervised learning: Unsupervised learning makes use of unstructured or unprocessed data. It is utilized for more complicated operations because its objective is to independently discover the structure and cluster the data. This kind of learning is beneficial for transactional data, such as recognizing client groupings with the same characteristics so that marketing efforts can treat them similarly.
Along with machine learning techniques, human participation can enhance the labeling of automatically generated data. A human annotator checks and validates the labels once the AI has labeled the raw data. The training data and projects for image processing can then include data that has been accurately classified.
If you are looking to perform automated data labeling for your project, and are in search of a platform that can automate your tasks by producing efficient content with accuracy, then, you can visit our website.
Labellerr is a data training platform that helps in reducing your efforts in the data annotation process and also, with our ML team experts we provide accurate results. To know more about our platform, visit us!
If you want to know more information, then do read our other blogs!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
