

Beginner's Guide to Named Entity Recognition (NER): Complete Tutorial
Discover Named Entity Recognition (NER) in this beginner's guide by Aditya Toshniwal. Learn its workings, applications, and implementation to extract insights from unstructured text!

Introduction
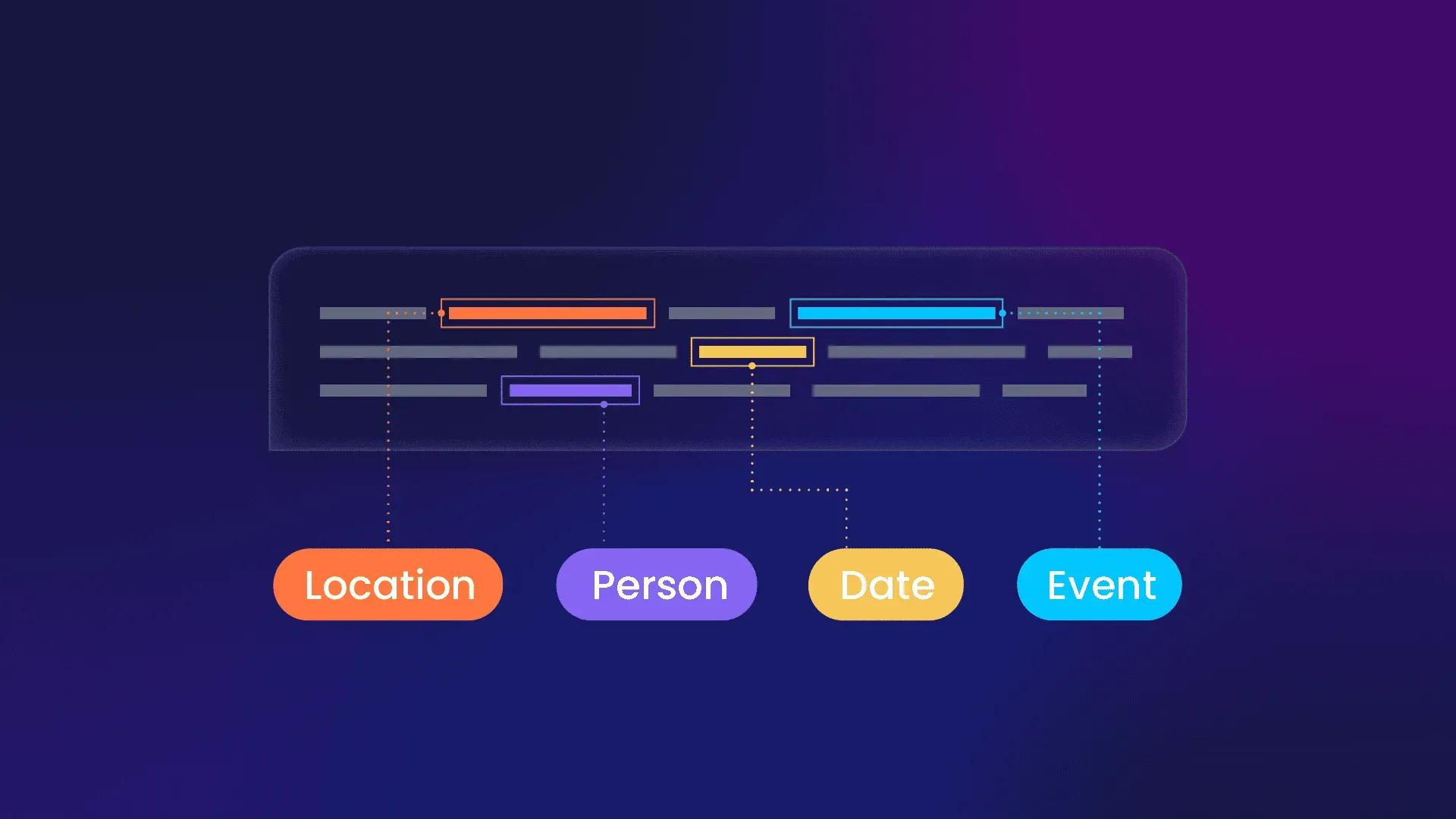
One of the most interesting parts of natural language processing (NLP) is named entity recognition (NER).
It is essential for deciphering and obtaining meaningful information from unstructured text.
NER essentially entails finding and classifying items in text data, including names of individuals, places, businesses, dates, and more.
The goal of this beginner's tutorial is to provide a solid understanding of the concepts, applications, and implementation of NER while demystifying the field.
This tutorial will bring you through the basics of NER and provide you the tools to apply this knowledge to real-world settings, whether you're a fledgling data scientist, an enthusiast for machine learning, or someone who is just fascinated by the magic of language interpretation.
Who Will Benefit from This Blog?
- Data Science Enthusiasts: If you're eager to explore the intersection of language and machine learning, this guide will serve as a perfect introduction to NER, giving you insights into how machines can identify and classify entities within text.
- Students and Learners: Whether you're a student diving into NLP for the first time or someone looking to enhance their machine learning skills, this guide provides a beginner-friendly approach, explaining concepts and code step by step.
- Developers and Programmers: If you're a developer curious about integrating NER into your applications or projects, this guide will equip you with the foundational knowledge needed to implement and leverage NER models effectively.
- NLP Enthusiasts: For those passionate about Natural Language Processing, this guide will deepen your understanding of NER, a critical component in extracting meaningful information from vast amounts of textual data.
- Business Professionals: Understanding NER can be valuable for professionals dealing with large volumes of text data, such as marketers, analysts, and business strategists. Learn how NER can enhance information extraction and analysis.
Dataset Overview
This is the extract from GMB corpus which is tagged, annotated and built specifically to train the classifier to predict named entities such as name, location, etc.
Essential info about entities:
- geo = Geographical Entity
- org = Organization
- per = Person
- gpe = Geopolitical Entity
- tim = Time indicator
- art = Artifact
- eve = Event
- nat = Natural Phenomenon
Total Words Count = 1354149
Target Data Column: "tag"
Outline
1.Importing Dependencies
2.Data Preprocessing
3.Splitting Data for Training and Evaluation
4.Building a BiLSTM-CRF Model
5.Training the Model
6.Evaluating Model Performance
7.Applying NER to Real-world Text
Importing Dependencies
In this section, essential libraries are imported to facilitate various tasks throughout the machine learning process.
import numpy as np
import tensorflow
from tensorflow.keras import Sequential, Model, Input
from tensorflow.keras.layers import LSTM, Embedding,
Dense, TimeDistributed, Dropout, Bidirectional
from tensorflow.keras.utils import plot_model
from numpy.random import seed
seed(1)
tensorflow.random.set_seed(13)
import pandas as pd
data = pd.read_csv('../input/named-entity-recognition-ner/ner_dataset.csv',
encoding= 'unicode_escape')
data.head()%20with%20Machine%20Learning/1.webp "Data Head")
Data Preprocessing
Learn the essential steps in data preprocessing, including mapping tokens and tags, handling missing values, and grouping data to prepare it for model input.
from itertools import chain
def get_dict_map(data, token_or_tag):
tok2idx = {}
idx2tok = {}
if token_or_tag == 'token':
vocab = list(set(data['Word'].to_list()))
else:
vocab = list(set(data['Tag'].to_list()))
idx2tok = {idx:tok for idx, tok in enumerate(vocab)}
tok2idx = {tok:idx for idx, tok in enumerate(vocab)}
return tok2idx, idx2tok
token2idx, idx2token = get_dict_map(data, 'token')
tag2idx, idx2tag = get_dict_map(data, 'tag')data['Word_idx'] = data['Word'].map(token2idx)
data['Tag_idx'] = data['Tag'].map(tag2idx)
data_fillna = data.fillna(method='ffill', axis=0)
# Groupby and collect columns
data_group = data_fillna.groupby(
['Sentence #'],as_index=False
)['Word', 'POS', 'Tag', 'Word_idx', 'Tag_idx'].agg(lambda x: list(x))Splitting Data for Training and Evaluation
Understand the importance of splitting data into training, testing, and validation sets. We'll also cover techniques like padding and one-hot encoding.
from sklearn.model_selection import train_test_split
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
def get_pad_train_test_val(data_group, data):
#get max token and tag length
n_token = len(list(set(data['Word'].to_list())))
n_tag = len(list(set(data['Tag'].to_list())))
#Pad tokens (X var)
tokens = data_group['Word_idx'].tolist()
maxlen = max([len(s) for s in tokens])
pad_tokens = pad_sequences(tokens, maxlen=maxlen, dtype='int32',
padding='post', value= n_token - 1)
#Pad Tags (y var) and convert it into one hot encoding
tags = data_group['Tag_idx'].tolist()
pad_tags = pad_sequences(tags, maxlen=maxlen, dtype='int32',
padding='post', value= tag2idx["O"])
n_tags = len(tag2idx)
pad_tags = [to_categorical(i, num_classes=n_tags) for i in pad_tags]
#Split train, test and validation set
tokens_, test_tokens, tags_, test_tags = train_test_split(pad_tokens,
pad_tags, train_size=0.8, random_state=42)
train_tokens, val_tokens, train_tags, val_tags =
train_test_split(tokens_,tags_,train_size =0.8, random_state=42)
print(
'train_tokens length:' , len(train_tokens),
'\ntrain_tags: ', len(train_tags),
'\ntest_tokens length: ', len(test_tokens),
'\ntest_tags: ', len(test_tags),
'\nval_tokens: ', len(val_tokens),
'\nval_tags: ', len(val_tags),
)
return train_tokens, val_tokens, test_tokens, train_tags, val_tags, test_tags
train_tokens, val_tokens, test_tokens, train_tags, val_tags,
test_tags = get_pad_train_test_val(data_group, data)
%20with%20Machine%20Learning/2.webp)
Building a BiLSTM-CRF Model
Explore the architecture of a Bidirectional Long Short-Term Memory (BiLSTM) model with Conditional Random Field (CRF) for NER. We'll discuss embedding layers, LSTM layers, and the final TimeDistributed Dense layer.
input_dim = len(list(set(data['Word'].to_list())))+1
output_dim = 64
input_length = max([len(s) for s in data_group['Word_idx'].tolist()])
n_tags = len(tag2idx)def get_bilstm_lstm_model():
model = Sequential()
# Add Embedding layer
model.add(Embedding(input_dim=input_dim, output_dim=output_dim,
input_length=input_length))
# Add bidirectional LSTM
model.add(Bidirectional(LSTM(units=output_dim, return_sequences=True,
dropout=0.2, recurrent_dropout=0.2), merge_mode = 'concat'))
# Add LSTM
model.add(LSTM(units=output_dim, return_sequences=True,
dropout=0.5, recurrent_dropout=0.5))
# Add timeDistributed Layer
model.add(TimeDistributed(Dense(n_tags, activation="relu")))
#Optimiser
# adam = k.optimizers.Adam(lr=0.0005, beta_1=0.9, beta_2=0.999)
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
return modelTraining the Model
Step into the model training process, including setting up parameters and iterating through epochs for improved performance.
def train_model(X, y, model):
loss = list()
for i in range(50):
# fit model for one epoch on this sequence
hist = model.fit(X, y, batch_size=1024, verbose=1, epochs=1, validation_split=0.2)
loss.append(hist.history['loss'][0])
return lossEvaluating Model Performance
Assess the model's accuracy and loss metrics. Visualize the model architecture to gain insights into its structure.
results = pd.DataFrame()
model_bilstm_lstm = get_bilstm_lstm_model()
plot_model(model_bilstm_lstm)
results['with_add_lstm'] = train_model(train_tokens, np.array(train_tags), model_bilstm_lstm)%20with%20Machine%20Learning/3.webp)
%20with%20Machine%20Learning/4.webp)
Applying NER to Real-world Text
Apply the trained NER model to a real-world text and observe how it identifies named entities.
import spacy
from spacy import displacy
*Load the small English model from SpaCy*
nlp = spacy.load('en_core_web_sm')
*Input text for processing*
text = nlp("""AI-based machine learning techniques are going beyond the cloud-based
data center, as processing of vital IoT sensor data moves much closer to where the data
first resides.
The move will be enabled by new artificial intelligence (AI)-equipped chips.
These include embedded microcontrollers with narrower memory and power
consumption requirements than GPUs (graphical processing units), FPGAs (field-
programmable gate arrays) and other specialized IC types first used to answer
data scientists’ questions in the cloud data centers of Amazon Web Services,
Microsoft and Google.
It was in these clouds that machine learning and related neural network use exploded.
But the rise of IoT created a data onslaught that required edge-based
machine learning as well.
Now, cloud providers, Internet of Things (IoT) platform makers,
and others see benefit in processing data at the edge before
turning it over to the cloud for analytics.
Making AI decisions at the edge reduces latency and makes
real-time response to sensor data more practical and possible.
Still, what people call “edge AI” takes many forms.
And how to power it with next-gen IoT presents
challenges in terms of presenting good-quality actionable data.
Edge Computing Workloads Grow
Edge-based machine learning could drive significant
growth of AI in the IoT market, which Mordor Intelligence
estimates will grow at a 27.3% CAGR through to 2026.
That is buttressed by Eclipse Foundation IoT
Group research in 2020, which pegged AI at 30% as
the most commonly cited edge computing workload
among IoT developers.
For many applications, replicating the endless racks
of servers that enabled parallel machine learning on
the cloud is not an option. IoT edge cases that benefit
from local processing are many, and highlighted by
varied cases of operations monitoring. The processors,
for example, watch events triggered by pressure gauge
changes on an oil rig, detection of an anomaly on
a distant power line, or captured video surveillance
of an issue at a factory.
The last case is one of those most widely pursued.
Application of AI that parses image data at the edge
has proved a fertile area. But there are many complex
processing needs for event processing using IoT
device-gathered data.
The Value of Edge Compute
Still, cloud-based IoT analytics will endure, said
Steve Conway, senior adviser, Hyperion Research.
But the distance data must travel brings processing
latency. Moving data to and from a cloud naturally
creates lag; the round trip takes time.
“There is something called the speed of light,”
Conway quips. “And you cannot exceed it.” As result,
a hierarchy of processing is developing on the edge.
Other than devices and board-level implementations,
this hierarchy includes IoT gateways and data centers
in manufacturing that expand architectural options
available for next-generation IoT system development.
In the long view, edge AI architecture is yet another
generational shift in data processing focus – but
a key one, according to Saurabh Mishra, senior manager
for product marketing at SAS’s IoT and Edge division.
“There is a progression here,” he said. “At one time,
the idea was centralizing your data. You can do that
for certain industries and certain use cases – ones
where data was already created in a context, such as
in a data center,” he said.
It’s not really possible to efficiently – and
economically – move that to the cloud for analysis,”
Mishra said, who noted that SAS has created validated
edge IoT reference architectures on top of which
customers can build AI and analytical applications.
Striking a balance between cloud and edge AI will be
a fundamental requirement, he said.
Finding balance begins with consideration of the amount
of data needed to run machine learning models, according
to Frédéric Desbiens, program manager, IoT and Edge
Computing at the Eclipse Foundation. That is where the
new intelligent processors come in.
“AI accelerators at the edge can do local processing before
sending the data somewhere else. But, this requires you to
think about the functional requirements, including the
software stack and storage needed,” Desbiens said.
AI Edge Chip Abundance
The rise of cloud-based machine learning was influenced by
the rise of the high-memory bandwidth GPU, often in the
form of a NVIDIA semiconductor. That success drew the
attention of other chip makers.
In-house AI-specific processors followed from hyperscale
cloud-players Google, AWS and Microsoft.
That AI chip battle has been joined by leading lights such
as AMD, Intel, Qualcomm, and ARM Technology (which, for its
part, last year was acquired by NVIDIA).
In turn, embedded microprocessor and systems-on-a-chip
mainstays like Maxim Integrated, NXP Semiconductors,
Silicon Labs, STM Microelectronics and others began to
focus on adding AI abilities to the edge.
Today, IoT and edge processing needs have attracted AI chip
start-ups that include EdgeQ, Graphcore, Hailo, Mythic
and others. Processing on the edge is constrained. Barriers
include memory available, energy consumed and cost,
emphasizes Hyperion’s Steve Conway.
“The embedded processors are very important, as energy
use is very important,” Conway said. “The GPUs and CPUs
are not tiny dies, and GPUs, particularly, use a ton of
energy,” he said, referring to the relatively large silicon
form factors GPUs and CPUs can take on.
Making Neurals Fit the Part
Data movement is a factor in energy consumption on the edge,
advises Kris Ardis, executive director of Maxim Integrated’s
microcontroller and software algorithm businesses. Recently,
the company released the MAX78000, which pairs a low-power
controller with a neural net processor that can run on
battery-powered IoT devices.
“If you can do a computation at the very edge, you save
bandwidth, and communications power. The challenge is
taking the neural net and making it fit in the part,”
Ardis said.
Individual IoT devices based on the chip can feed
IoT gateways, which also have a useful part to play,
combining rollups of data from devices, and further
filtering data that may go to the cloud in order to
analyze overall operations, he indicated.
Other semiconductor device makers also are adjusting
to a trend that sees compute moving nearer to where
data is. They are part of the effort to broaden the
capabilities of developers, even as their hardware choices grow.
Bill Pearson, vice president of Intel’s IoT group admits
there was a time when “the CPU was the answer to all
problems.” Trends like edge AI belie that now.
He uses the term “XPU” to represent a variety of chip types
that support different uses. But, he adds, the variety should
be supported by a single software application
programming interface (API).
To aid software developers, Intel recently released
Version 2021.2 of the OpenVINO toolkit for inference
on edge systems. It provides a, common environment
for development among Intel components including
CPUs, GPUs, and Movidius Visual Processing Units.
As well, Intel offers DevCloud for the Edge
software to forecast performance of neural
network inference on different Intel hardware,
according to Pearson.
The drive to simplify is marked at GPU powerhouse NVIDIA too.
“The industry has to make it easier for people that aren’t
AI specialists,” said Justin Boitano, vice president and
general manager for Enterprise and Edge Computing, NVIDIA.
That may take the form of NVIDIA Jetson, which includes a
low-power ARM processor. Named with a nod to the ‘60s
science-fiction cartoon series, Jetson is intended to
provide GPU-accelerated parallel processing in mobile
embedded systems.
Recently, to ease vision system development, NVIDIA
rolled out Jetson JetPack 4.5, which includes the first
production version of its Vision Programming Interface (VPI).
With time, edge AI development chores will be handled more by
IT shops, and less by AI researchers with deep knowledge of
machine learning, Boitano said.
The Tiny ML That Roared
The skills needed to migrate machine learning methods from the
vast cloud to the constrained edge device are not easily gained.
But new software techniques are being applied to enable compact
edge AI, while easing the task of the developer.
In fact, industry has experienced the rise of “Tiny ML”
approaches. These make do with less power and use limited
memory, while achieving capable inference-operations-per-second
ratings.
Various machine learning tooling to reduce edge processing
requirements have emerged, including Apache MXNet, Edge
Impulse’s EON, Facebook’s Glow, Foghorn Lightning Edge ML,
Google TensorFlow Lite, Microsoft ELL, OctoML’s Octomizer
and others.
Down-sizing neural net processing is a main target here, and
the techniques are several. Among these are quantization,
binarization and pruning, according to Sastry Malladi, who
is CTO at Foghorn, a maker of a software platform that supports
a variety of edge and on-premises implementations.
Quantization of neural net processing focuses on use of low
bit-width math. Binarization, in turn, is used to reduce the
complexity of computations. And, pruning is used to reduce the
number of neural nodes that must be processed.
Malladi admits that is a daunting gamut for most developers to
traverse – especially across a range of hardware. The efforts
behind Foghorn’s Lightning platform, he said, are intended to
abstract the complexity in machine learning on the edge.
The goal is to allow line operators and reliability engineers,
for example, to work with drag-and-drop interfaces, rather
than application programming interfaces and software
development kits, which are less intuitive and require
more coding knowledge.
Software that simplifies development and runs across multiple
types of edge AI hardware is also a focus for Edge Impulse,
makers of a development platform for embedded machine
learning.
Ultimately, machine learning maturation means some model
miniaturization, according to Zach Shelby, CEO, Edge Impulse.
“Once, the direction of the research was toward bigger and
bigger models of more and more
%20with%20Machine%20Learning/5.webp)
%20with%20Machine%20Learning/6.webp)
%20with%20Machine%20Learning/7.webp)
%20with%20Machine%20Learning/8.webp)
%20with%20Machine%20Learning/9.webp)
%20with%20Machine%20Learning/10.webp)
%20with%20Machine%20Learning/11.webp)
Conclusion
This beginner's guide to Named Entity Recognition (NER) provided a foundational understanding of dataset exploration, token mapping, and data preprocessing. We set the stage for building a powerful NER model by preparing the data for training and strategically splitting it into training, testing, and validation sets. The journey has just begun, and upcoming chapters will unravel the intricacies of model architecture, training, and evaluation. Whether you're a data enthusiast or aspiring data scientist, this guide aims to empower you on your NER exploration. Stay tuned for more insights and practical applications in the exciting world of NER.
Frequently Asked Questions
1.What is the purpose of NER in NLP?
One technique for extracting information from text in natural language processing (NLP) is named entity recognition (NER). NER entails identifying and classifying named entities—important information found in text—into groups.
2.What are the approaches to create a NER system?
Lexicon-based, rule-based, and machine learning-based are the three main NER techniques.
3.What are the challenges of named entity recognition?
Contextual difficulties, inconsistent entity references, unclear entity types, ambiguity in entity names, and misspelt entity names are some of the difficulties that NER encounters.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
